KoELECTRA
1.0.0
韩语|英语
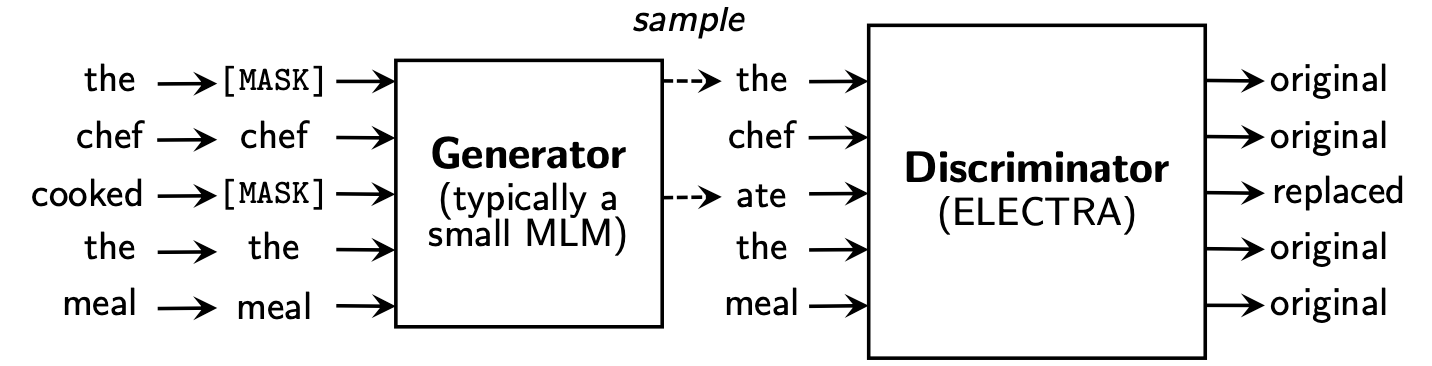
伊莱克特拉(Electra)学会了通过确定歧视器中的“真实”令牌或Replaced Token Detection 。该方法具有能够了解所有输入令牌的优点,并且与BERT相比,其性能更好。
Koelectra在34GB的韩语文本中学习了两种模型: KoELECTRA-Base和KoELECTRA-Small 。
此外,无论是通过文字和模型S3上传,都可以通过安装Transformers库来立即使用Koelectra。
| 模型 | 歧视者 | 发电机 | TensorFlow-V1 |
|---|---|---|---|
KoELECTRA-Base-v1 | 歧视者 | 发电机 | TensorFlow-V1 |
KoELECTRA-Small-v1 | 歧视者 | 发电机 | TensorFlow-V1 |
KoELECTRA-Base-v2 | 歧视者 | 发电机 | TensorFlow-V1 |
KoELECTRA-Small-v2 | 歧视者 | 发电机 | TensorFlow-V1 |
KoELECTRA-Base-v3 | 歧视者 | 发电机 | TensorFlow-V1 |
KoELECTRA-Small-v3 | 歧视者 | 发电机 | TensorFlow-V1 |
| 层 | 嵌入尺寸 | 隐藏尺寸 | #头 | ||
|---|---|---|---|---|---|
KoELECTRA-Base | 歧视者 | 12 | 768 | 768 | 12 |
| 发电机 | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | 歧视者 | 12 | 128 | 256 | 4 |
| 发电机 | 12 | 128 | 256 | 4 |
Wordpiece和代码中使用的文字,而无需使用sendencece或mecab。| 词汇Len | do_lower_case | |
|---|---|---|
| V1 | 32200 | 错误的 |
| v2 | 32200 | 错误的 |
| V3 | 35000 | 错误的 |
v1和v2 ,我们使用了大约14G语料库(2.6b代币)。 (新闻,维基,树维基)v3 ,我们使用了大约20克的其他马匹。 (报纸,章鱼,口语,信使,网络)| 模型 | 批量大小 | 火车步骤 | LR | Max Seq Len | 发电机大小 | 火车时间 |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700k | 2E-4 | 512 | 0.33 | 7d |
Base v3 | 256 | 1.5m | 2E-4 | 512 | 0.33 | 14d |
Small v1,2 | 512 | 300k | 5E-4 | 512 | 1.0 | 3D |
Small v3 | 512 | 800k | 5E-4 | 512 | 1.0 | 7d |
对于KoELECTRA-Small模型,使用了与原始纸中的ELECTRA-Small++相同的选项。
KoELECTRA-Base不同,生成器和鉴别器的模型大小(= generator_hidden_size size)是相同的。除了Batch size和Train steps外,我也采用了原始纸的超参数。
我了解了使用TPU V3-8 ,GCP中的TPU用法总结在[使用TPU进行预处理]中。
它正式支持来自Transformers v2.8.0的ElectraModel 。
该模型已经上传到HuggingFace S3 ,因此您可以立即使用它,而无需直接下载模型。
ElectraModel类似于BertModel ,除了它不会返回pooled_output 。
Electra使用discriminator进行填充。
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]这是配置设置的结果,如果您添加更多的超参数调整,则可以获得更好的性能。
请参阅[Finetung]以获取代码和详细信息
| NSMC (ACC) | naver ner (F1) | 爪子 (ACC) | 科恩利 (ACC) | 科斯特 (斯皮尔曼) | 问题对 (ACC) | Korquad(DEV) (EM/F1) | 韩国讨厌的语音(开发人员) (F1) | |
|---|---|---|---|---|---|---|---|---|
| 科伯特 | 89.59 | 87.92 | 81.25 | 79.62 | 81.59 | 94.85 | 51.75 / 79.15 | 66.21 |
| XLM-Roberta-bas | 89.03 | 86.65 | 82.80 | 80.23 | 78.45 | 93.80 | 64.70 / 88.94 | 64.06 |
| 汉伯特 | 90.06 | 87.70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| koelectra-base | 90.33 | 87.18 | 81.70 | 80.64 | 82.00 | 93.54 | 60.86 / 89.28 | 66.09 |
| koelectra-base-v2 | 89.56 | 87.16 | 80.70 | 80.72 | 82.30 | 94.85 | 84.01 / 92.40 | 67.45 |
| Koelectra-Base-V3 | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 | 67.61 |
| NSMC (ACC) | naver ner (F1) | 爪子 (ACC) | 科恩利 (ACC) | 科斯特 (斯皮尔曼) | 问题对 (ACC) | Korquad(DEV) (EM/F1) | 韩国讨厌的语音(开发人员) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Distilkobert | 88.60 | 84.65 | 60.50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60.72 |
| Koelectra-small | 88.83 | 84.38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| koelectra-small-v2 | 88.83 | 85.00 | 72.35 | 78.14 | 77.84 | 93.27 | 81.43 / 90.46 | 60.14 |
| koelectra-small-v3 | 89.36 | 85.40 | 77.45 | 78.60 | 80.79 | 94.85 | 82.11 / 91.13 | 63.07 |
2020年4月27日
KorSTS , QuestionPair ),并为五个现有子任务更新了结果。2020年6月3日
KoELECTRA-v2是使用Enlipleai PLM中使用的词汇创建的。基本和小型模型都在KorQuaD中提高了性能。2020年10月9日
모두의 말뭉치制作了KoELECTRA-v3 。词汇也是使用Mecab和Wordpiece新创建的。ElectraForSequenceClassification的官方支持Huggingface Transformers现有的子任务结果是新更新。我们还添加了韩国讨厌的语音的结果。 from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )2021年5月26日
torch<=1.4未加载的问题(修改模型后完成的重新加载)(相关问题)tensorflow v2模型上传到HuggingFace Hub( tf_model.h5 )2021年10月20日
tf_model.h5中,有几个问题直接从删除的部分加载(从加载from_pt=True ) Koelectra是由Tensorflow Research Cloud(TFRC)程序的云TPU支持生产的。 KoELECTRA-v3也是在所有马匹的帮助下生产的。
如果您使用此代码进行研究,请引用如下。
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

