KoELECTRA
1.0.0
Coréen | Anglais
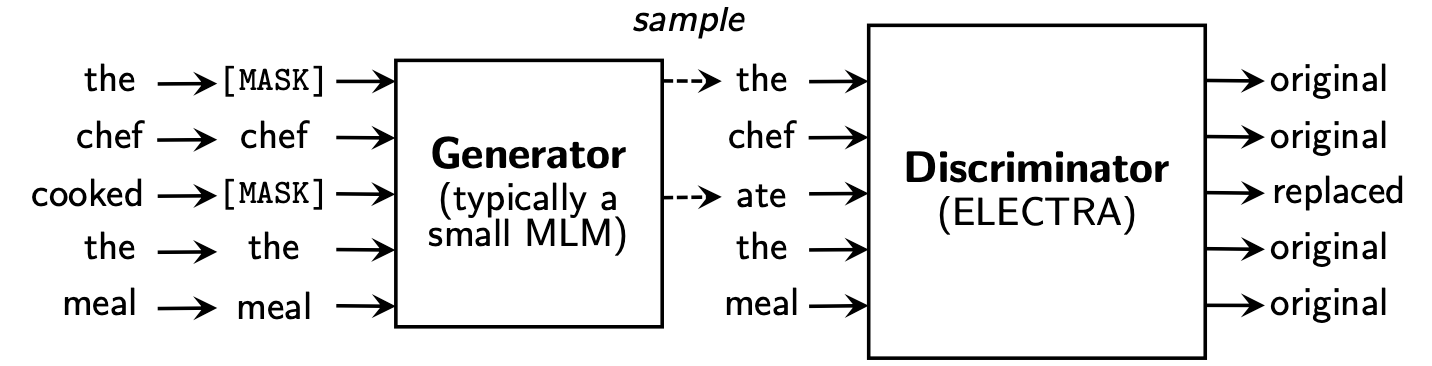
L'Electra apprend à Replaced Token Detection , en déterminant s'il s'agit de jeton "réel" ou "faux" en discriminateur. Cette méthode a l'avantage de pouvoir en savoir plus sur tous les jetons d'entrée, et il a de meilleures performances par rapport à Bert.
Koelectra a appris dans 34 Go de texte coréen et a distribué deux modèles: KoELECTRA-Base et KoELECTRA-Small .
De plus, Koelectra peut être utilisé immédiatement en installant la bibliothèque Transformers , quel que soit le système d'exploitation via la pièce d'éloge et le téléchargement du modèle S3 .
| Modèle | Discriminateur | Générateur | Tensorflow-V1 |
|---|---|---|---|
KoELECTRA-Base-v1 | Discriminateur | Générateur | Tensorflow-V1 |
KoELECTRA-Small-v1 | Discriminateur | Générateur | Tensorflow-V1 |
KoELECTRA-Base-v2 | Discriminateur | Générateur | Tensorflow-V1 |
KoELECTRA-Small-v2 | Discriminateur | Générateur | Tensorflow-V1 |
KoELECTRA-Base-v3 | Discriminateur | Générateur | Tensorflow-V1 |
KoELECTRA-Small-v3 | Discriminateur | Générateur | Tensorflow-V1 |
| Couches | Taille d'incorporation | Taille cachée | # têtes | ||
|---|---|---|---|---|---|
KoELECTRA-Base | Discriminateur | 12 | 768 | 768 | 12 |
| Générateur | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | Discriminateur | 12 | 128 | 256 | 4 |
| Générateur | 12 | 128 | 256 | 4 |
Wordpiece utilisée dans le papier d'origine et le code sans utiliser le SentencE ou Mecab.| Vocab | do_lower_case | |
|---|---|---|
| v1 | 32200 | FAUX |
| v2 | 32200 | FAUX |
| v3 | 35000 | FAUX |
v1 et v2 , nous avons utilisé environ 14 g de corpus (jetons 2.6b). (News, Wiki, Tree Wiki)v3 , nous avons utilisé des chevaux supplémentaires d'environ 20 g . (Journal, poulpe, parlé, messager, web)| Modèle | Taille de lot | Marches de train | LR | Max Seq Len | Taille du générateur | Temps de train |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700k | 2E-4 | 512 | 0,33 | 7d |
Base v3 | 256 | 1,5 m | 2E-4 | 512 | 0,33 | 14D |
Small v1,2 | 512 | 300k | 5E-4 | 512 | 1.0 | 3D |
Small v3 | 512 | 800k | 5E-4 | 512 | 1.0 | 7d |
Dans le cas du modèle KoELECTRA-Small , la même option que ELECTRA-Small++ dans le papier d'origine a été utilisée.
KoELECTRA-Base , la taille du modèle du générateur et du discriminateur (= generator_hidden_size ) est la même. À l'exception Batch size et Train steps , j'ai pris la même chose que l'hyperparamètre du papier d'origine .
J'ai appris en utilisant le TPU V3-8 , et l'utilisation du TPU dans le GCP est résumé en [utilisant TPU pour la pré-entraînement].
Il soutient officiellement ElectraModel de Transformers v2.8.0 .
Le modèle est déjà téléchargé sur HuggingFace S3 , vous pouvez donc l'utiliser immédiatement sans avoir à télécharger directement le modèle .
ElectraModel est similaire à BertModel , sauf qu'il ne retourne pas pooled_output .
Electra utilise discriminator pour les finetuning.
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]C'est le résultat du paramètre de la configuration tel quel, et si vous ajoutez plus de réglage hyperparamètre, vous pouvez obtenir de meilleures performances.
Veuillez vous référer à [Finetung] pour le code et les détails
| Nsmc (ACC) | Naver Ner (F1) | Pattes (ACC) | Kornli (ACC) | KORSTS (Lancier) | Paire de questions (ACC) | Korquad (dev) (EM / F1) | Coréen-hate-dispeech (dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Kobert | 89.59 | 87,92 | 81.25 | 79.62 | 81,59 | 94.85 | 51.75 / 79.15 | 66.21 |
| XLM-Roberta-base | 89.03 | 86,65 | 82.80 | 80.23 | 78,45 | 93.80 | 64.70 / 88.94 | 64.06 |
| Hanbert | 90.06 | 87.70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| Koelectra-base | 90.33 | 87.18 | 81.70 | 80.64 | 82.00 | 93.54 | 60,86 / 89.28 | 66.09 |
| Koelectra-bas-v2 | 89.56 | 87.16 | 80.70 | 80.72 | 82.30 | 94.85 | 84.01 / 92.40 | 67.45 |
| Koelectra-bas-v3 | 90,63 | 88.11 | 84.45 | 82.24 | 85,53 | 95.25 | 84.83 / 93.45 | 67.61 |
| Nsmc (ACC) | Naver Ner (F1) | Pattes (ACC) | Kornli (ACC) | KORSTS (Lancier) | Paire de questions (ACC) | Korquad (dev) (EM / F1) | Coréen-hate-dispeech (dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Distilkobert | 88,60 | 84.65 | 60,50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60,72 |
| Koelectra-Small | 88,83 | 84.38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| Koelectra-Small-V2 | 88,83 | 85,00 | 72.35 | 78.14 | 77.84 | 93.27 | 81.43 / 90.46 | 60.14 |
| Koelectra-Small-V3 | 89.36 | 85.40 | 77.45 | 78,60 | 80.79 | 94.85 | 82.11 / 91.13 | 63.07 |
27 avril 2020
KorSTS , QuestionPair ) et mis à jour les résultats pour cinq sous-tâches existantes.3 juin 2020
KoELECTRA-v2 a été créé en utilisant le vocabulaire utilisé dans Enlipleai PLM. Les modèles de base et de petits ont amélioré les performances à KorQuaD .9 octobre 2020
KoELECTRA-v3 en utilisant 모두의 말뭉치 supplémentaires. Le vocabulaire est également nouvellement créé à l'aide Mecab et Wordpiece .ElectraForSequenceClassification de Huggingface Transformers les résultats de la sous-tâche existants sont nouvellement mis à jour. Nous avons également ajouté les résultats du discours coréen-hate. from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )26 mai 2021
torch<=1.4 problèmes qui ne sont pas chargés (charge ré-up terminée après modification du modèle) (problème connexe)tensorflow v2 Modèle téléchargé sur HuggingFace Hub ( tf_model.h5 )20 octobre 2021
tf_model.h5 , plusieurs problèmes sont chargés directement à partir de la partie de la suppression (du chargement avec from_pt=True ) Koelectra a été produit avec le support Cloud TPU du programme Tensorflow Research Cloud (TFRC) . KoELECTRA-v3 a également été produit avec l'aide de tous les chevaux .
Si vous utilisez ce code pour la recherche, veuillez citer comme suit.
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

