KoELECTRA
1.0.0
Korea | Bahasa inggris
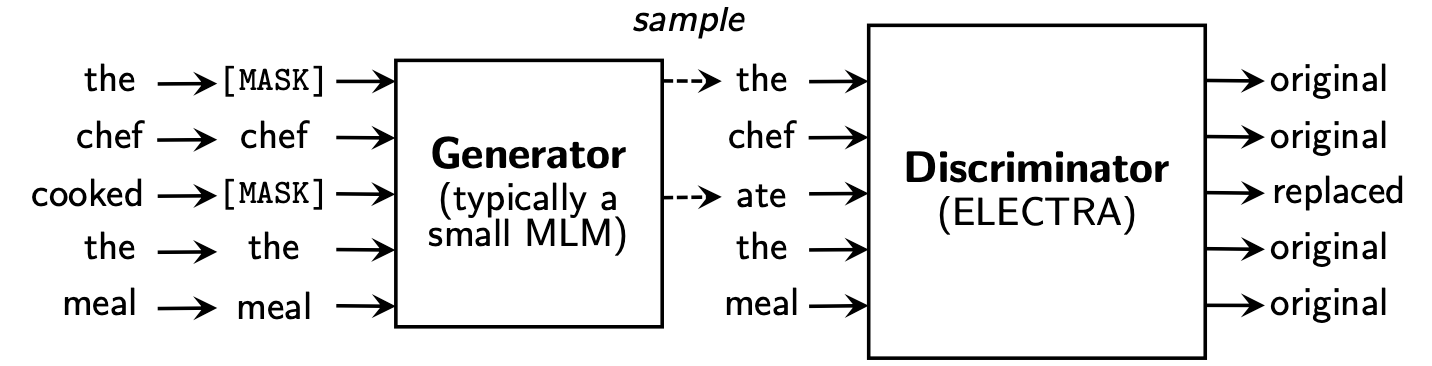
Electra belajar untuk Replaced Token Detection , dengan menentukan apakah itu token "nyata" atau token "palsu" pada diskriminator. Metode ini memiliki keuntungan karena dapat mempelajari semua token input, dan memiliki kinerja yang lebih baik dibandingkan dengan Bert.
Koelectra belajar dalam 34GB teks Korea dan mendistribusikan dua model: KoELECTRA-Base dan KoELECTRA-Small .
Selain itu, koelectra dapat segera digunakan dengan menginstal perpustakaan Transformers , terlepas dari OS melalui wordpiece dan unggahan Model S3 .
| Model | Diskriminator | Generator | TensorFlow-V1 |
|---|---|---|---|
KoELECTRA-Base-v1 | Diskriminator | Generator | TensorFlow-V1 |
KoELECTRA-Small-v1 | Diskriminator | Generator | TensorFlow-V1 |
KoELECTRA-Base-v2 | Diskriminator | Generator | TensorFlow-V1 |
KoELECTRA-Small-v2 | Diskriminator | Generator | TensorFlow-V1 |
KoELECTRA-Base-v3 | Diskriminator | Generator | TensorFlow-V1 |
KoELECTRA-Small-v3 | Diskriminator | Generator | TensorFlow-V1 |
| Lapisan | Ukuran embedding | Ukuran tersembunyi | # kepala | ||
|---|---|---|---|---|---|
KoELECTRA-Base | Diskriminator | 12 | 768 | 768 | 12 |
| Generator | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | Diskriminator | 12 | 128 | 256 | 4 |
| Generator | 12 | 128 | 256 | 4 |
Wordpiece yang digunakan dalam kertas asli dan kode tanpa menggunakan Sentencece atau Mecab.| Vocab Len | do_lower_case | |
|---|---|---|
| v1 | 32200 | PALSU |
| v2 | 32200 | PALSU |
| v3 | 35000 | PALSU |
v1 dan v2 , kami menggunakan sekitar 14G corpus (2,6b token). (Berita, wiki, wiki pohon)v3 , kami menggunakan kuda tambahan sekitar 20g . (Surat Kabar, Gurita, Lisan, Messenger, Web)| Model | Ukuran batch | Langkah Latih | Lr | Max Seq Len | Ukuran generator | Waktu kereta api |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700K | 2e-4 | 512 | 0.33 | 7d |
Base v3 | 256 | 1.5m | 2e-4 | 512 | 0.33 | 14d |
Small v1,2 | 512 | 300K | 5e-4 | 512 | 1.0 | 3d |
Small v3 | 512 | 800K | 5e-4 | 512 | 1.0 | 7d |
Dalam kasus model KoELECTRA-Small , opsi yang sama dengan ELECTRA-Small++ dalam kertas asli digunakan.
KoELECTRA-Base , ukuran model generator dan diskriminator (= generator_hidden_size ) adalah sama. Kecuali untuk Batch size dan Train steps , saya mengambil hal yang sama dengan hiperparameter kertas asli .
Saya belajar menggunakan TPU V3-8 , dan penggunaan TPU dalam GCP dirangkum dalam [menggunakan TPU untuk pretraining].
Secara resmi mendukung ElectraModel dari Transformers v2.8.0 .
Model ini sudah diunggah ke HuggingFace S3 , sehingga Anda dapat menggunakannya segera tanpa harus mengunduh model secara langsung .
ElectraModel mirip dengan BertModel , kecuali bahwa itu tidak mengembalikan pooled_output .
Electra menggunakan discriminator untuk finetuning.
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]Ini adalah hasil dari pengaturan konfigurasi sebagaimana adanya, dan jika Anda menambahkan lebih banyak tuning hiperparameter, Anda bisa mendapatkan kinerja yang lebih baik.
Silakan merujuk ke [Finetung] untuk kode dan detailnya
| NSMC (ACC) | Naver Ner (F1) | Cakar (ACC) | Kornli (ACC) | Korst (Spearman) | Tanya pasangan (ACC) | Korquad (dev) (Em/f1) | Korea-benci-Speech (dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Kobert | 89.59 | 87.92 | 81.25 | 79.62 | 81.59 | 94.85 | 51.75 / 79.15 | 66.21 |
| XLM-Roberta-Base | 89.03 | 86.65 | 82.80 | 80.23 | 78.45 | 93.80 | 64.70 / 88.94 | 64.06 |
| Hanbert | 90.06 | 87.70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| Koelectra-base | 90.33 | 87.18 | 81.70 | 80.64 | 82.00 | 93.54 | 60.86 / 89.28 | 66.09 |
| Koelectra-base-v2 | 89.56 | 87.16 | 80.70 | 80.72 | 82.30 | 94.85 | 84.01 / 92.40 | 67.45 |
| Koelectra-Base-V3 | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 | 67.61 |
| NSMC (ACC) | Naver Ner (F1) | Cakar (ACC) | Kornli (ACC) | Korst (Spearman) | Tanya pasangan (ACC) | Korquad (dev) (Em/f1) | Korea-benci-Speech (dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Distilkobert | 88.60 | 84.65 | 60.50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60.72 |
| Koelectra-Small | 88.83 | 84.38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| Koelectra-Small-V2 | 88.83 | 85.00 | 72.35 | 78.14 | 77.84 | 93.27 | 81.43 / 90.46 | 60.14 |
| Koelectra-Small-V3 | 89.36 | 85.40 | 77.45 | 78.60 | 80.79 | 94.85 | 82.11 / 91.13 | 63.07 |
27 April 2020
KorSTS , QuestionPair ) dan memperbarui hasil untuk lima subtugas yang ada.3 Juni 2020
KoELECTRA-v2 dibuat menggunakan kosa kata yang digunakan dalam eneripleai PLM. Baik model dasar dan kecil telah meningkatkan kinerja di KorQuaD .9 Oktober 2020
KoELECTRA-v3 dengan menggunakan 모두의 말뭉치 tambahan. Vocab juga baru dibuat menggunakan Mecab dan Wordpiece .ElectraForSequenceClassification dari Huggingface Transformers hasil subtugas yang ada baru diperbarui. Kami juga menambahkan hasil-pekarangan Korea-Benci. from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )26 Mei 2021
torch<=1.4 Masalah yang tidak dimuat (LEBIH LUAR BIASA SEPERTI MODEL SETELAH MODIFIKASI) (Masalah Terkait)tensorflow v2 Model Diunggah ke HUB HUBGINGFACE ( tf_model.h5 )20 Okt 2021
tf_model.h5 , ada beberapa masalah yang dimuat langsung dari bagian penghapusan (dari pemuatan dengan from_pt=True ) Koelectra diproduksi dengan dukungan TPU cloud dari program TensorFlow Research Cloud (TFRC) . KoELECTRA-v3 juga diproduksi dengan bantuan semua kuda kuda .
Jika Anda menggunakan kode ini untuk penelitian, silakan kutip sebagai berikut.
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

