KoELECTRA
1.0.0
كوري | إنجليزي
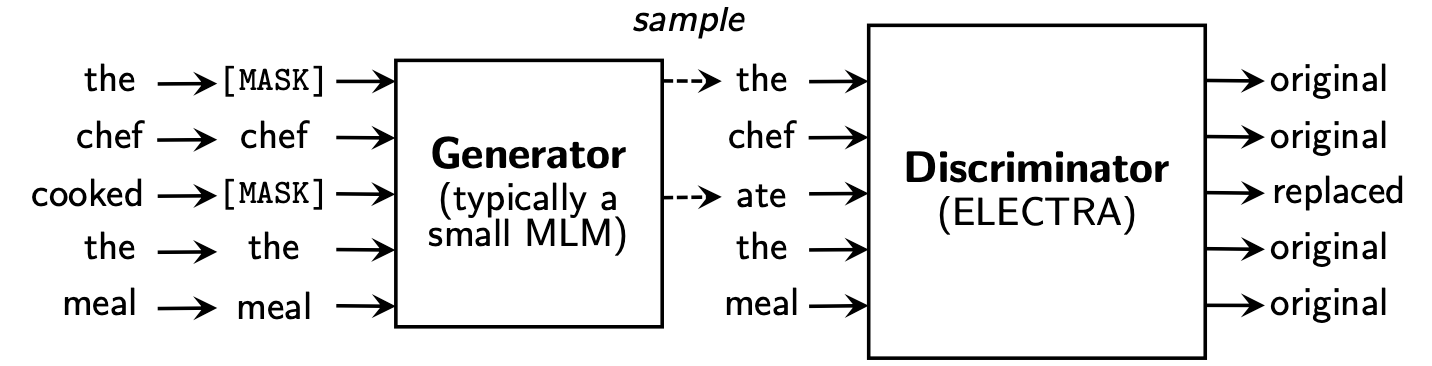
يتعلم Electra Replaced Token Detection ، من خلال تحديد ما إذا كان رمزًا "حقيقيًا" أو "مزيفًا" في التمييز. تتمتع هذه الطريقة بميزة القدرة على التعرف على كل الرمز المميز للمدخلات ، ولديها أداء أفضل مقارنة بـ BERT.
تعلمت Koelectra في 34 جيجابايت من النص الكوري ووزعت نموذجين: KoELECTRA-Base و KoELECTRA-Small .
بالإضافة إلى ذلك ، يمكن استخدام Koelectra فورًا عن طريق تثبيت مكتبة Transformers ، بغض النظر عن نظام التشغيل من خلال WordPiece وتحميل النموذج S3 .
| نموذج | تمييز | مولد | Tensorflow-V1 |
|---|---|---|---|
KoELECTRA-Base-v1 | تمييز | مولد | Tensorflow-V1 |
KoELECTRA-Small-v1 | تمييز | مولد | Tensorflow-V1 |
KoELECTRA-Base-v2 | تمييز | مولد | Tensorflow-V1 |
KoELECTRA-Small-v2 | تمييز | مولد | Tensorflow-V1 |
KoELECTRA-Base-v3 | تمييز | مولد | Tensorflow-V1 |
KoELECTRA-Small-v3 | تمييز | مولد | Tensorflow-V1 |
| طبقات | حجم التضمين | الحجم المخفي | # رؤساء | ||
|---|---|---|---|---|---|
KoELECTRA-Base | تمييز | 12 | 768 | 768 | 12 |
| مولد | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | تمييز | 12 | 128 | 256 | 4 |
| مولد | 12 | 128 | 256 | 4 |
Wordpiece المستخدمة في الورقة الأصلية والرمز دون استخدام Sentence أو MECAB.| vocab لين | do_lower_case | |
|---|---|---|
| V1 | 32200 | خطأ شنيع |
| V2 | 32200 | خطأ شنيع |
| V3 | 35000 | خطأ شنيع |
v1 و v2 ، استخدمنا حوالي 14 جرام (2.6B الرموز المميزة). (أخبار ، ويكي ، شجرة ويكي)v3 ، استخدمنا خيول إضافية من حوالي 20 جرام . (الصحف ، الأخطبوط ، المنطوق ، الرسول ، الويب)| نموذج | حجم الدُفعة | خطوات التدريب | LR | ماكس سيك لين | حجم المولد | وقت القطار |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700K | 2E-4 | 512 | 0.33 | 7D |
Base v3 | 256 | 1.5m | 2E-4 | 512 | 0.33 | 14D |
Small v1,2 | 512 | 300K | 5e-4 | 512 | 1.0 | 3D |
Small v3 | 512 | 800k | 5e-4 | 512 | 1.0 | 7D |
في حالة طراز KoELECTRA-Small ، تم استخدام نفس الخيار مثل ELECTRA-Small++ في الورقة الأصلية.
KoELECTRA-Base ، فإن حجم نموذج المولد والتمييز (= generator_hidden_size ) هو نفسه. باستثناء Batch size Train steps ، أخذت نفس الفصح في الورقة الأصلية .
لقد تعلمت استخدام TPU V3-8 ، ويتم تلخيص استخدام TPU في GCP في [باستخدام TPU للتدرب].
يدعم رسميا ElectraModel من Transformers v2.8.0 .
تم تحميل النموذج بالفعل إلى Huggingface S3 ، بحيث يمكنك استخدامه على الفور دون الحاجة إلى تنزيل النموذج مباشرة .
يشبه ElectraModel BertModel ، باستثناء أنه لا يعيد pooled_output .
يستخدم Electra discriminator للتأثير.
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]هذا هو نتيجة إعداد التكوين كما هو ، وإذا قمت بإضافة المزيد من ضبط الفائقة ، فيمكنك الحصول على أداء أفضل.
يرجى الرجوع إلى [Finetung] للحصول على الكود والتفاصيل
| NSMC (ACC) | naver ner (F1) | الكفوف (ACC) | كورنلي (ACC) | Korsts (الرامح) | زوج أسئلة (ACC) | Korquad (Dev) (EM/F1) | الكراهية الكورية للكراهية (ديف) (F1) | |
|---|---|---|---|---|---|---|---|---|
| كوبرت | 89.59 | 87.92 | 81.25 | 79.62 | 81.59 | 94.85 | 51.75 / 79.15 | 66.21 |
| XLM-Roberta-base | 89.03 | 86.65 | 82.80 | 80.23 | 78.45 | 93.80 | 64.70 / 88.94 | 64.06 |
| هانبرت | 90.06 | 87.70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| Koelectra-base | 90.33 | 87.18 | 81.70 | 80.64 | 82.00 | 93.54 | 60.86 / 89.28 | 66.09 |
| Koelectra-Base-V2 | 89.56 | 87.16 | 80.70 | 80.72 | 82.30 | 94.85 | 84.01 / 92.40 | 67.45 |
| Koelectra-Base-V3 | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 | 67.61 |
| NSMC (ACC) | naver ner (F1) | الكفوف (ACC) | كورنلي (ACC) | Korsts (الرامح) | زوج أسئلة (ACC) | Korquad (Dev) (EM/F1) | الكراهية الكورية للكراهية (ديف) (F1) | |
|---|---|---|---|---|---|---|---|---|
| distilkobert | 88.60 | 84.65 | 60.50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60.72 |
| Koelectra-Small | 88.83 | 84.38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| Koelectra-Small-V2 | 88.83 | 85.00 | 72.35 | 78.14 | 77.84 | 93.27 | 81.43 / 90.46 | 60.14 |
| Koelectra-Small-V3 | 89.36 | 85.40 | 77.45 | 78.60 | 80.79 | 94.85 | 82.11 / 91.13 | 63.07 |
27 أبريل 2020
KorSTS ، QuestionPair ) وقمنا بتحديث النتائج لخمس مهام فرعية موجودة.3 يونيو 2020
KoELECTRA-v2 باستخدام المفردات المستخدمة في Enlipleai PLM. كل من النماذج القاعدة والنماذج الصغيرة قد تحسنت الأداء في KorQuaD .9 أكتوبر 2020
KoELECTRA-v3 باستخدام 모두의 말뭉치 إضافية. يتم إنشاء Vocab حديثًا باستخدام Mecab و Wordpiece .ElectraForSequenceClassification Huggingface Transformers يتم تحديث نتائج المهام الفرعية الحالية حديثًا. لقد أضفنا أيضًا نتائج الكئيب الكوري للكراهية. from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )26 مايو 2021
torch<=1.4 مشكلات لم يتم تحميلها (تحميل إعادة التشغيل المكتمل بعد تعديل النموذج) (المشكلة ذات الصلة)tensorflow v2 تم تحميله إلى Huggingface Hub ( tf_model.h5 )20 أكتوبر 2021
tf_model.h5 ، هناك العديد من المشكلات التي يتم تحميلها مباشرة من جزء الإزالة (من التحميل مع from_pt=True ) تم إنتاج Koelectra بدعم Cloud TPU من برنامج TensorFlow Research Cloud (TFRC) . تم إنتاج KoELECTRA-v3 أيضًا بمساعدة جميع خيول الخيول .
إذا كنت تستخدم هذا الرمز للبحث ، فيرجى اقتباسًا على النحو التالي.
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

