KoELECTRA
1.0.0
เกาหลี ภาษาอังกฤษ
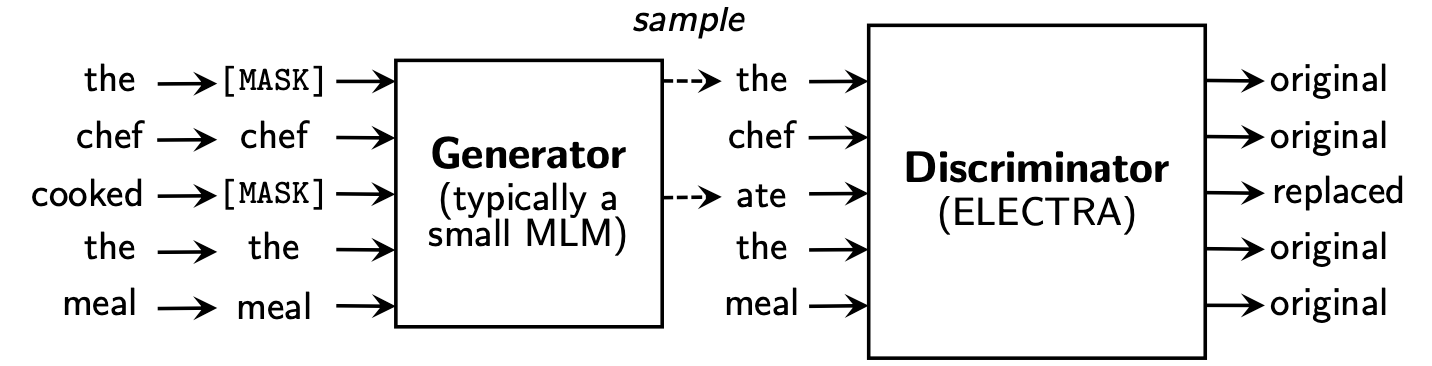
Electra เรียนรู้ที่จะ Replaced Token Detection โดยการพิจารณาว่าเป็นโทเค็น "จริง" หรือ "ปลอม" โทเค็นใน discriminator วิธีนี้มีข้อได้เปรียบในการเรียนรู้เกี่ยวกับโทเค็นอินพุตทั้งหมดและมีประสิทธิภาพที่ดีกว่าเมื่อเทียบกับ Bert
Koelectra เรียนรู้ใน ข้อความเกาหลี 34GB และแจกจ่ายสองรุ่น: KoELECTRA-Base และ KoELECTRA-Small
นอกจากนี้ Koelectra สามารถใช้งานได้ทันทีโดยการติดตั้งไลบรารี Transformers โดยไม่คำนึงถึงระบบปฏิบัติการผ่าน WordPiece และ การอัปโหลด Model S3
| แบบอย่าง | การเลือกปฏิบัติ | เครื่องกำเนิดไฟฟ้า | tensorflow-v1 |
|---|---|---|---|
KoELECTRA-Base-v1 | การเลือกปฏิบัติ | เครื่องกำเนิดไฟฟ้า | tensorflow-v1 |
KoELECTRA-Small-v1 | การเลือกปฏิบัติ | เครื่องกำเนิดไฟฟ้า | tensorflow-v1 |
KoELECTRA-Base-v2 | การเลือกปฏิบัติ | เครื่องกำเนิดไฟฟ้า | tensorflow-v1 |
KoELECTRA-Small-v2 | การเลือกปฏิบัติ | เครื่องกำเนิดไฟฟ้า | tensorflow-v1 |
KoELECTRA-Base-v3 | การเลือกปฏิบัติ | เครื่องกำเนิดไฟฟ้า | tensorflow-v1 |
KoELECTRA-Small-v3 | การเลือกปฏิบัติ | เครื่องกำเนิดไฟฟ้า | tensorflow-v1 |
| ชั้น | ขนาดฝัง | ขนาดที่ซ่อน | # หัว | ||
|---|---|---|---|---|---|
KoELECTRA-Base | การเลือกปฏิบัติ | 12 | 768 | 768 | 12 |
| เครื่องกำเนิดไฟฟ้า | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | การเลือกปฏิบัติ | 12 | 128 | 256 | 4 |
| เครื่องกำเนิดไฟฟ้า | 12 | 128 | 256 | 4 |
Wordpiece ที่ใช้ในกระดาษต้นฉบับและรหัสโดยไม่ต้องใช้ประโยคหรือ MECAB| คำศัพท์เลน | do_lower_case | |
|---|---|---|
| V1 | 32200 | เท็จ |
| V2 | 32200 | เท็จ |
| V3 | 35000 | เท็จ |
v1 และ v2 เราใช้ คลังข้อมูลประมาณ 14 กรัม (โทเค็น 2.6B) (ข่าว, วิกิ, ต้นไม้วิกิ)v3 เราใช้ ม้าเพิ่มเติมประมาณ 20 กรัม (หนังสือพิมพ์, ปลาหมึก, พูด, messenger, เว็บ)| แบบอย่าง | ขนาดแบทช์ | รถไฟก้าว | LR | Max Seq Len | ขนาดเครื่องกำเนิดไฟฟ้า | เวลาฝึกซ้อม |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700K | 2e-4 | 512 | 0.33 | 7d |
Base v3 | 256 | 1.5m | 2e-4 | 512 | 0.33 | 14d |
Small v1,2 | 512 | 300K | 5E-4 | 512 | 1.0 | 3D |
Small v3 | 512 | 800K | 5E-4 | 512 | 1.0 | 7d |
ในกรณีของรุ่น KoELECTRA-Small ตัวเลือกเดียว กับ ELECTRA-Small++ ในกระดาษต้นฉบับถูกนำมาใช้
KoELECTRA-Base ขนาดของรุ่นของเครื่องกำเนิดไฟฟ้าและ discriminator (= generator_hidden_size ) ก็เหมือนกัน ยกเว้น Batch size และ Train steps ฉันก็ใช้ แบบไฮเปอร์พารามิเตอร์ของกระดาษต้นฉบับ
ฉันเรียนรู้การใช้ TPU V3-8 และการใช้ TPU ใน GCP สรุปไว้ใน [การใช้ TPU สำหรับการเตรียมการ]
รองรับ ElectraModel อย่างเป็นทางการจาก Transformers v2.8.0
โมเดลได้อัปโหลดไปยัง HuggingFace S3 แล้วดังนั้นคุณสามารถใช้งานได้ทันที โดยไม่ต้องดาวน์โหลดโมเดลโดยตรง
ElectraModel คล้ายกับ BertModel ยกเว้นว่าจะไม่ส่งคืน pooled_output
Electra ใช้ discriminator สำหรับ finetuning
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]นี่คือผลลัพธ์ของการตั้งค่าการกำหนดค่าตามที่เป็นอยู่และหากคุณเพิ่มการปรับแต่งพารามิเตอร์ hyperparameter มากขึ้นคุณจะได้รับประสิทธิภาพที่ดีขึ้น
โปรดดู [Finetung] สำหรับรหัสและรายละเอียด
| NSMC (ACC) | นาวีเนอร์ (F1) | อุ้งเท้า (ACC) | Kornli (ACC) | คี (สเปียร์แมน) | คู่คำถาม (ACC) | Korquad (dev) (em/f1) | ภาษาเกาหลี-เกลียดชัง (dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| โคเบิร์ต | 89.59 | 87.92 | 81.25 | 79.62 | 81.59 | 94.85 | 51.75 / 79.15 | 66.21 |
| XLM-Roberta-base | 89.03 | 86.65 | 82.80 | 80.23 | 78.45 | 93.80 | 64.70 / 88.94 | 64.06 |
| ฮันเบิร์ต | 90.06 | 87.70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| ฐาน Koelectra | 90.33 | 87.18 | 81.70 | 80.64 | 82.00 | 93.54 | 60.86 / 89.28 | 66.09 |
| Koelectra-base-V2 | 89.56 | 87.16 | 80.70 | 80.72 | 82.30 | 94.85 | 84.01 / 92.40 | 67.45 |
| Koelectra-base-V3 | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 | 67.61 |
| NSMC (ACC) | นาวีเนอร์ (F1) | อุ้งเท้า (ACC) | Kornli (ACC) | คี (สเปียร์แมน) | คู่คำถาม (ACC) | Korquad (dev) (em/f1) | ภาษาเกาหลี-เกลียดชัง (dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| กลั่นกรอง | 88.60 | 84.65 | 60.50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60.72 |
| Koelectra-small | 88.83 | 84.38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| Koelectra-Small-V2 | 88.83 | 85.00 | 72.35 | 78.14 | 77.84 | 93.27 | 81.43 / 90.46 | 60.14 |
| Koelectra-Small-V3 | 89.36 | 85.40 | 77.45 | 78.60 | 80.79 | 94.85 | 82.11 / 91.13 | 63.07 |
27 เมษายน 2563
KorSTS , QuestionPair ) และอัปเดตผลลัพธ์สำหรับงานย่อยห้าฉบับที่มีอยู่3 มิถุนายน 2020
KoELECTRA-v2 ถูกสร้างขึ้นโดยใช้คำศัพท์ที่ใช้ใน Enlipleai PLM ทั้งรุ่นฐานและขนาดเล็กมีประสิทธิภาพที่ดีขึ้นใน KorQuaD9 ตุลาคม 2563
KoELECTRA-v3 โดยใช้ 모두의 말뭉치 เพิ่มเติม คำศัพท์ยังถูกสร้างขึ้นใหม่โดยใช้ Mecab และ WordpieceElectraForSequenceClassification ของ Huggingface Transformers ผลงานย่อยที่มีอยู่คือการอัปเดตใหม่ นอกจากนี้เรายังเพิ่มผลลัพธ์ของการพูดด้วยความเกลียดชังเกาหลี from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )26 พฤษภาคม 2564
torch<=1.4 ปัญหาที่ไม่ได้โหลดtensorflow v2 อัปโหลดไปยัง HuggingFace Hub ( tf_model.h5 )20 ต.ค. 2021
tf_model.h5 มีหลายประเด็นที่โหลดโดยตรงจากส่วนของการลบ (จากการโหลดด้วย from_pt=True ) Koelectra ผลิตด้วยการสนับสนุน Cloud TPU จากโปรแกรม การวิจัย Tensorflow Cloud (TFRC) KoELECTRA-v3 ก็ผลิตด้วยความช่วยเหลือของ ม้าม้าทั้งหมด
หากคุณใช้รหัสนี้เพื่อการวิจัยโปรดอ้างอิงดังนี้
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

