KoELECTRA
1.0.0
Корейский | Английский
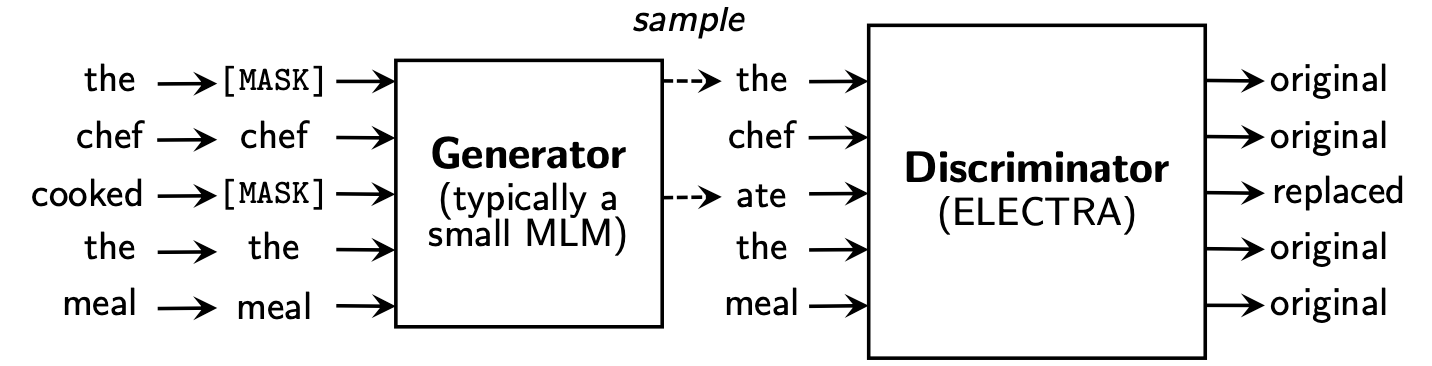
Electra учится Replaced Token Detection , определяя, является ли он «реальным» токеном или «поддельным» токеном в дискриминаторе. Этот метод имеет преимущество в том, что он способен узнать обо всех входных токенах, и он обладает лучшей производительностью по сравнению с BERT.
Koelectra выучился в 34 ГБ корейского текста и распространял две модели: KoELECTRA-Base и KoELECTRA-Small .
Кроме того, Koelectra можно использовать немедленно путем установки библиотеки Transformers , независимо от ОС через слова и загрузку модели S3 .
| Модель | Дискриминатор | Генератор | Tensorflow-V1 |
|---|---|---|---|
KoELECTRA-Base-v1 | Дискриминатор | Генератор | Tensorflow-V1 |
KoELECTRA-Small-v1 | Дискриминатор | Генератор | Tensorflow-V1 |
KoELECTRA-Base-v2 | Дискриминатор | Генератор | Tensorflow-V1 |
KoELECTRA-Small-v2 | Дискриминатор | Генератор | Tensorflow-V1 |
KoELECTRA-Base-v3 | Дискриминатор | Генератор | Tensorflow-V1 |
KoELECTRA-Small-v3 | Дискриминатор | Генератор | Tensorflow-V1 |
| Слои | Размер встраивания | Скрытый размер | # головы | ||
|---|---|---|---|---|---|
KoELECTRA-Base | Дискриминатор | 12 | 768 | 768 | 12 |
| Генератор | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | Дискриминатор | 12 | 128 | 256 | 4 |
| Генератор | 12 | 128 | 256 | 4 |
Wordpiece используемое в оригинальной статье, и код без использования приговора или мекаба.| Vocab Len | do_lower_case | |
|---|---|---|
| v1 | 32200 | ЛОЖЬ |
| v2 | 32200 | ЛОЖЬ |
| v3 | 35000 | ЛОЖЬ |
v1 и v2 мы использовали около 14G -корпуса (токены 2,6B). (Новости, Вики, дерево вики)v3 мы использовали дополнительных лошадей около 20 г. (Газета, осьминог, разговор, посланник, Интернет)| Модель | Размер партии | Поезда шаги | Лр | Макс Сик Лен | Размер генератора | Время поезда |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700K | 2E-4 | 512 | 0,33 | 7d |
Base v3 | 256 | 1,5 м | 2E-4 | 512 | 0,33 | 14d |
Small v1,2 | 512 | 300K | 5e-4 | 512 | 1.0 | 3d |
Small v3 | 512 | 800K | 5e-4 | 512 | 1.0 | 7d |
В случае модели KoELECTRA-Small использовался тот же вариант , что и ELECTRA-Small++ в исходной статье.
KoELECTRA-Base , размер модели генератора и дискриминатора (= generator_hidden_size ) одинаково. За исключением Batch size и Train steps , я сделал то же самое, что и гиперпараметр оригинальной бумаги .
Я научился, используя TPU V3-8 , и использование TPU в GCP обобщено в [с использованием TPU для предварительной подготовки].
Он официально поддерживает ElectraModel от Transformers v2.8.0 .
Модель уже загружена на S3 HuggingFace , поэтому вы можете использовать ее немедленно , не загружая модель непосредственно .
ElectraModel аналогична BertModel , за исключением того, что она не возвращает pooled_output .
Electra использует discriminator для создания.
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]Это является результатом настройки конфигурации, как есть, и если вы добавите больше настройки гиперпараметров, вы можете получить лучшую производительность.
Пожалуйста, обратитесь к [Feenetung] для кода и подробностей
| NSMC (ACC) | Навер Нер (F1) | Лапы (ACC) | Корнли (ACC) | Корсты (Спирмен) | Пара вопросов (ACC) | Korquad (dev) (EM/F1) | Корейская-ненавистная речь (разработка) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Коберт | 89,59 | 87.92 | 81.25 | 79,62 | 81.59 | 94,85 | 51,75 / 79,15 | 66.21 |
| XLM-Roberta-Base | 89.03 | 86.65 | 82,80 | 80.23 | 78.45 | 93,80 | 64,70 / 88,94 | 64.06 |
| Ханберт | 90.06 | 87.70 | 82,95 | 80.32 | 82,73 | 94,72 | 78,74 / 92,02 | 68.32 |
| Koelectra-Base | 90.33 | 87.18 | 81.70 | 80.64 | 82.00 | 93,54 | 60,86 / 89,28 | 66.09 |
| Koelectra-Base-V2 | 89,56 | 87.16 | 80.70 | 80.72 | 82.30 | 94,85 | 84,01 / 92,40 | 67.45 |
| Koelectra-Base-V3 | 90.63 | 88.11 | 84,45 | 82,24 | 85,53 | 95,25 | 84,83 / 93,45 | 67.61 |
| NSMC (ACC) | Навер Нер (F1) | Лапы (ACC) | Корнли (ACC) | Корсты (Спирмен) | Пара вопросов (ACC) | Korquad (dev) (EM/F1) | Корейская-ненавистная речь (разработка) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Distilkobert | 88.60 | 84,65 | 60.50 | 72.00 | 72,59 | 92.48 | 54,40 / 77,97 | 60.72 |
| Koelectra-Small | 88.83 | 84,38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| Koelectra-Small-V2 | 88.83 | 85,00 | 72,35 | 78.14 | 77.84 | 93,27 | 81.43 / 90.46 | 60.14 |
| Koelectra-Small-V3 | 89,36 | 85,40 | 77.45 | 78.60 | 80.79 | 94,85 | 82.11 / 91.13 | 63,07 |
27 апреля 2020 года
KorSTS , QuestionPair ) и обновили результаты для пяти существующих подзадач.3 июня 2020 года
KoELECTRA-v2 был создан с использованием словаря, используемого в Enlipleai PLM. Как базовые, так и небольшие модели имеют улучшение производительности в KorQuaD .9 октября 2020 года
KoELECTRA-v3 , используя дополнительных 모두의 말뭉치 . Vocab также недавно создан с использованием Mecab и Wordpiece .ElectraForSequenceClassification Huggingface Transformers существующие результаты подзадачи являются вновь обновлением. Мы также добавили результаты корейской-ненавистной речи. from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )26 мая 2021 года
torch<=1.4 Проблемы, которые не загружаются (завершенная загрузка повторной нагрузки после изменения модели) (связанная проблема)tensorflow v2 Модель загружена в Hub Huggingface ( tf_model.h5 )20 октября 2021 года
tf_model.h5 есть несколько проблем, которые загружаются непосредственно из части удаления (от загрузки с помощью from_pt=True ) Koelectra была произведена с поддержкой Cloud TPU из программы Tensorflow Research Cloud (TFRC) . KoELECTRA-v3 также был произведен с помощью всех лошадей лошадей .
Если вы используете этот код для исследования, пожалуйста, укажите следующее.
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

