KoELECTRA
1.0.0
韓国語|英語
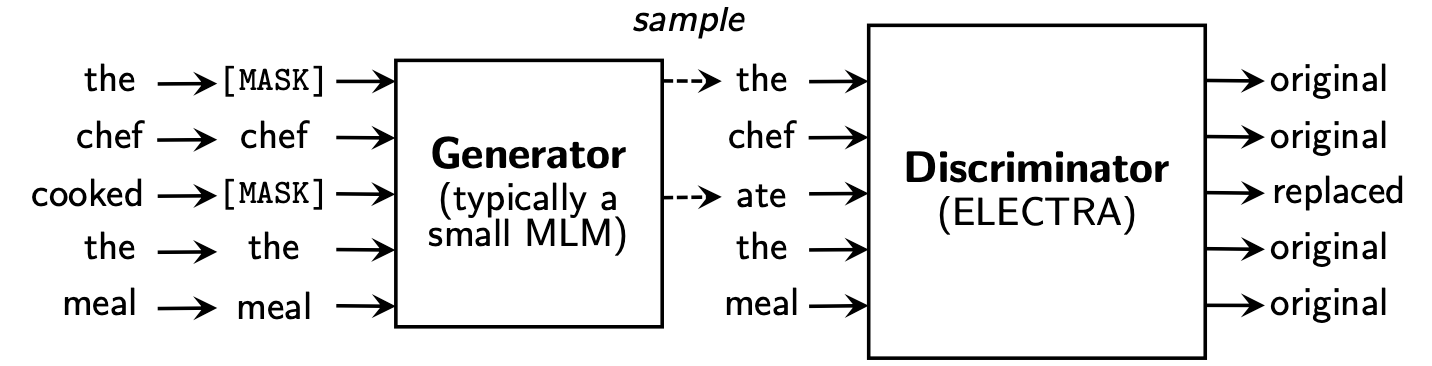
ElectraはReplaced Token Detectionを学びます。この方法には、すべての入力トークンについて学ぶことができるという利点があり、BERTに比べてパフォーマンスが向上しています。
Koelectraは、34GBの韓国のテキストで学び、 KoELECTRA-BaseとKoELECTRA-Small 2つのモデルを分配しました。
さらに、 WordPieceとModel S3のアップロードを介してOSに関係なく、 Transformersライブラリをインストールすることにより、Koelectraをすぐに使用できます。
| モデル | 判別器 | ジェネレータ | Tensorflow-V1 |
|---|---|---|---|
KoELECTRA-Base-v1 | 判別器 | ジェネレータ | Tensorflow-V1 |
KoELECTRA-Small-v1 | 判別器 | ジェネレータ | Tensorflow-V1 |
KoELECTRA-Base-v2 | 判別器 | ジェネレータ | Tensorflow-V1 |
KoELECTRA-Small-v2 | 判別器 | ジェネレータ | Tensorflow-V1 |
KoELECTRA-Base-v3 | 判別器 | ジェネレータ | Tensorflow-V1 |
KoELECTRA-Small-v3 | 判別器 | ジェネレータ | Tensorflow-V1 |
| レイヤー | 埋め込みサイズ | 隠されたサイズ | #ヘッド | ||
|---|---|---|---|---|---|
KoELECTRA-Base | 判別器 | 12 | 768 | 768 | 12 |
| ジェネレータ | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | 判別器 | 12 | 128 | 256 | 4 |
| ジェネレータ | 12 | 128 | 256 | 4 |
Wordpieceを使用したTransformersライブラリを使用して、すぐにモデルを作成することでした。| Vocab Len | do_lower_case | |
|---|---|---|
| V1 | 32200 | 間違い |
| V2 | 32200 | 間違い |
| V3 | 35000 | 間違い |
v1およびv2には、約14Gコーパス(2.6Bトークン)を使用しました。 (ニュース、ウィキ、ツリーウィキ)v3の場合、約20gの追加の馬を使用しました。 (新聞、タコ、話された、メッセンジャー、ウェブ)| モデル | バッチサイズ | 列車の階段 | LR | Max seq len | ジェネレーターサイズ | トレーニング時間 |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700k | 2E-4 | 512 | 0.33 | 7d |
Base v3 | 256 | 1.5m | 2E-4 | 512 | 0.33 | 14D |
Small v1,2 | 512 | 300k | 5E-4 | 512 | 1.0 | 3D |
Small v3 | 512 | 800k | 5E-4 | 512 | 1.0 | 7d |
KoELECTRA-Smallモデルの場合、元の論文のELECTRA-Small++と同じオプションが使用されました。
KoELECTRA-Baseとは異なり、ジェネレーターと識別子のモデルサイズ(= generator_hidden_size size)は同じです。 Batch sizeとTrain stepsを除いて、私は元の論文のハイパーパラメーターと同じを取りました。
TPU V3-8を使用して学習しましたが、GCPでのTPU使用は[TPUを使用して事前化する]に要約されています。
Transformers v2.8.0からのElectraModelを正式にサポートしています。
モデルは既にHuggingface S3にアップロードされているため、モデルを直接ダウンロードすることなくすぐに使用できます。
ElectraModelは、 BertModelに似ていますが、 pooled_outputを返さないことを除きます。
Electraは、Finetuningにdiscriminatorを使用します。
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]これは、構成の設定の結果であり、HyperParameterチューニングを追加すると、パフォーマンスを向上させることができます。
コードと詳細については、[Finetung]を参照してください
| NSMC (acc) | Naver Ner (F1) | 足 (acc) | コーンリ (acc) | コースト (スピアマン) | 質問ペア (acc) | Korquad(dev) (EM/F1) | 韓国から嫌いなもの(開発者) (F1) | |
|---|---|---|---|---|---|---|---|---|
| コバート | 89.59 | 87.92 | 81.25 | 79.62 | 81.59 | 94.85 | 51.75 / 79.15 | 66.21 |
| xlm-roberta-base | 89.03 | 86.65 | 82.80 | 80.23 | 78.45 | 93.80 | 64.70 / 88.94 | 64.06 |
| ハンバート | 90.06 | 87.70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| Koelectra-base | 90.33 | 87.18 | 81.70 | 80.64 | 82.00 | 93.54 | 60.86 / 89.28 | 66.09 |
| koelectra-base-v2 | 89.56 | 87.16 | 80.70 | 80.72 | 82.30 | 94.85 | 84.01 / 92.40 | 67.45 |
| koelectra-base-v3 | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 | 67.61 |
| NSMC (acc) | Naver Ner (F1) | 足 (acc) | コーンリ (acc) | コースト (スピアマン) | 質問ペア (acc) | Korquad(dev) (EM/F1) | 韓国から嫌いなもの(開発者) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Distilkobert | 88.60 | 84.65 | 60.50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60.72 |
| koelectra-small | 88.83 | 84.38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| koelectra-small-v2 | 88.83 | 85.00 | 72.35 | 78.14 | 77.84 | 93.27 | 81.43 / 90.46 | 60.14 |
| koelectra-small-v3 | 89.36 | 85.40 | 77.45 | 78.60 | 80.79 | 94.85 | 82.11 / 91.13 | 63.07 |
2020年4月27日
KorSTS 、 QuestionPair )を完了し、5つの既存のサブタスクの結果を更新しました。2020年6月3日
KoELECTRA-v2 Enlipleai PLMで使用される語彙を使用して作成されました。ベースモデルと小さなモデルの両方が、 KorQuaDのパフォーマンスが向上しました。2020年10月9日
모두의 말뭉치を使用して、 KoELECTRA-v3を作成しました。 Vocabは、 MecabとWordpieceを使用して新たに作成されています。Huggingface TransformersのElectraForSequenceClassificationの公式サポートを考慮すると、既存のサブタスクの結果は新しく更新されます。また、韓国人嫌悪のスピーチの結果を追加しました。 from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )2021年5月26日
torch<=1.4ロードされていない問題(モデルを変更した後に完了したRe -UPロード)(関連する問題)tensorflow v2モデルHuggingface Hub( tf_model.h5 )にアップロード2021年10月20日
tf_model.h5では、削除の部分から直接ロードされるいくつかの問題があります( from_pt=Trueのロードから) Koelectraは、Tensorflow Research Cloud(TFRC)プログラムからクラウドTPUサポートで生産されました。 KoELECTRA-v3 、すべての馬の馬の助けを借りて生産されました。
このコードを調査に使用している場合は、次のように引用してください。
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

