KoELECTRA
1.0.0
Coreano | Inglês
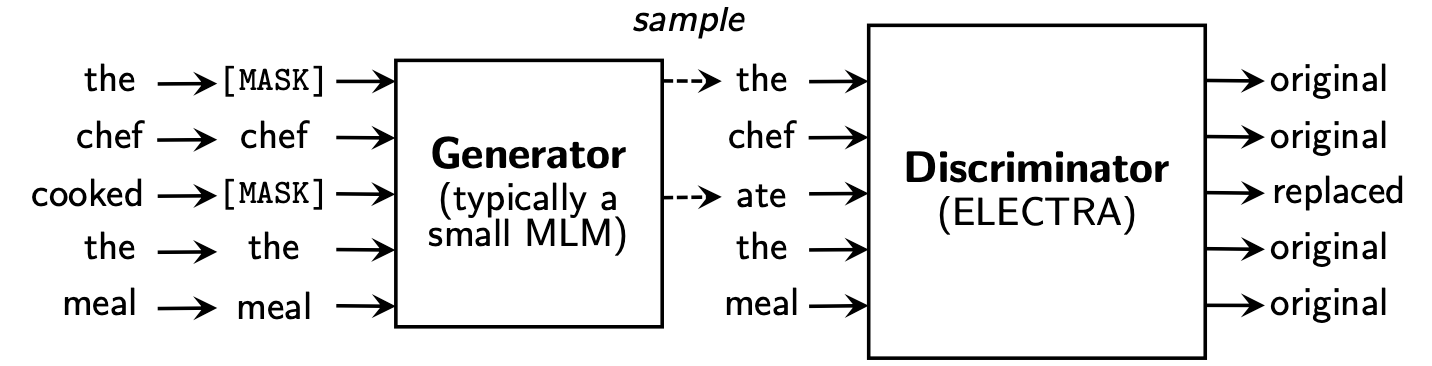
O Electra aprende a Replaced Token Detection , determinando se é um token "real" ou "falso" token no discriminador. Esse método tem a vantagem de poder aprender sobre todo o token de entrada e tem melhor desempenho em comparação com o BERT.
Koelectra aprendeu em 34 GB de texto coreano e distribuiu dois modelos: KoELECTRA-Base e KoELECTRA-Small .
Além disso, o Koelectra pode ser usado imediatamente instalando a biblioteca Transformers , independentemente do sistema operacional através da palavra da palavra e do upload do modelo S3 .
| Modelo | Discriminador | Gerador | Tensorflow-v1 |
|---|---|---|---|
KoELECTRA-Base-v1 | Discriminador | Gerador | Tensorflow-v1 |
KoELECTRA-Small-v1 | Discriminador | Gerador | Tensorflow-v1 |
KoELECTRA-Base-v2 | Discriminador | Gerador | Tensorflow-v1 |
KoELECTRA-Small-v2 | Discriminador | Gerador | Tensorflow-v1 |
KoELECTRA-Base-v3 | Discriminador | Gerador | Tensorflow-v1 |
KoELECTRA-Small-v3 | Discriminador | Gerador | Tensorflow-v1 |
| Camadas | Tamanho da incorporação | Tamanho oculto | # cabeças | ||
|---|---|---|---|---|---|
KoELECTRA-Base | Discriminador | 12 | 768 | 768 | 12 |
| Gerador | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | Discriminador | 12 | 128 | 256 | 4 |
| Gerador | 12 | 128 | 256 | 4 |
Wordpiece usada no papel original e o código sem usar a sentença ou o MECAB.| Vocable Len | do_lower_case | |
|---|---|---|
| v1 | 32200 | Falso |
| v2 | 32200 | Falso |
| v3 | 35000 | Falso |
v1 e v2 , usamos cerca de 14G corpus (2,6b tokens). (Notícias, wiki, wiki da árvore)v3 , usamos cavalos adicionais de cerca de 20g . (Jornal, polvo, falado, mensageiro, web)| Modelo | Tamanho do lote | Trep degraus | Lr | Max Seq Len | Tamanho do gerador | Tempo de trem |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700K | 2E-4 | 512 | 0,33 | 7d |
Base v3 | 256 | 1,5m | 2E-4 | 512 | 0,33 | 14d |
Small v1,2 | 512 | 300k | 5E-4 | 512 | 1.0 | 3d |
Small v3 | 512 | 800K | 5E-4 | 512 | 1.0 | 7d |
No caso do modelo KoELECTRA-Small , foi usada a mesma opção que ELECTRA-Small++ no papel original.
KoELECTRA-Base , o tamanho do modelo de gerador e discriminador (= generator_hidden_size ) é o mesmo. Exceto pelo Batch size e Train steps , tomei o mesmo que o hiperparâmetro do papel original .
Aprendi usando o TPU V3-8 , e o uso da TPU no GCP está resumido em [usando TPU para pré-treinamento].
Apoia oficialmente ElectraModel da Transformers v2.8.0 .
O modelo já está carregado para o HuggingFace S3 , para que você possa usá -lo imediatamente sem precisar fazer o download diretamente do modelo .
ElectraModel é semelhante ao BertModel , exceto que não retorna pooled_output .
Electra usa discriminator para finetuning.
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]Este é o resultado da configuração da configuração e, se você adicionar mais ajuste hiperparâmetro, poderá obter um melhor desempenho.
Consulte [Finetung] para obter código e detalhes
| NSMC (ACC) | Naver ner (F1) | Patas (ACC) | Kornli (ACC) | Korsts (Lanceiro) | Par de perguntas (ACC) | Korquad (Dev) (Em/F1) | Funche-falação de ódio coreano (Dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Kobert | 89.59 | 87.92 | 81.25 | 79.62 | 81.59 | 94.85 | 51.75 / 79.15 | 66.21 |
| XLM-ROBERTA-BASE | 89.03 | 86.65 | 82.80 | 80.23 | 78.45 | 93.80 | 64.70 / 88.94 | 64.06 |
| Hanbert | 90.06 | 87,70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| Koelectra-Base | 90.33 | 87.18 | 81.70 | 80,64 | 82.00 | 93.54 | 60.86 / 89.28 | 66.09 |
| Koelectra-Base-V2 | 89.56 | 87.16 | 80,70 | 80,72 | 82.30 | 94.85 | 84.01 / 92.40 | 67.45 |
| Koelectra-Base-V3 | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 | 67.61 |
| NSMC (ACC) | Naver ner (F1) | Patas (ACC) | Kornli (ACC) | Korsts (Lanceiro) | Par de perguntas (ACC) | Korquad (Dev) (Em/F1) | Funche-falação de ódio coreano (Dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Destilkobert | 88,60 | 84.65 | 60,50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60,72 |
| Koelectra-Small | 88.83 | 84.38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| Koelectra-Small-V2 | 88.83 | 85,00 | 72.35 | 78.14 | 77.84 | 93.27 | 81.43 / 90.46 | 60.14 |
| Koelectra-Small-V3 | 89.36 | 85.40 | 77.45 | 78.60 | 80,79 | 94.85 | 82.11 / 91.13 | 63.07 |
27 de abril de 2020
KorSTS , QuestionPair ) e atualizamos os resultados para cinco subtarefas existentes.3 de junho de 2020
KoELECTRA-v2 foi criado usando o vocabulário usado no Enipleai Plm. Os modelos básicos e pequenos têm melhor desempenho em KorQuaD .9 de outubro de 2020
KoELECTRA-v3 usando 모두의 말뭉치 adicionais. O vocabulário também é criado recentemente usando Mecab e Wordpiece .ElectraForSequenceClassification dos Huggingface Transformers os resultados da subtarefa existentes são atualizados recentemente. Também adicionamos os resultados da fala coreana-ódio. from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )26 de maio de 2021
torch<=1.4 Problemas que não são carregados (carga de re -Up concluída após modificar o modelo) (questão relacionada)tensorflow v2 Carregado para Hubgingface Hub ( tf_model.h5 )20 de outubro de 2021
tf_model.h5 , existem vários problemas que são carregados diretamente da parte da remoção (do carregamento com from_pt=True ) O Koelectra foi produzido com o suporte à Cloud TPU do programa TensorFlow Research Cloud (TFRC) . KoELECTRA-v3 também foi produzido com a ajuda de todos os cavalos de cavalo .
Se você estiver usando este código para pesquisa, cite o seguinte.
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

