KoELECTRA
1.0.0
Korean | English
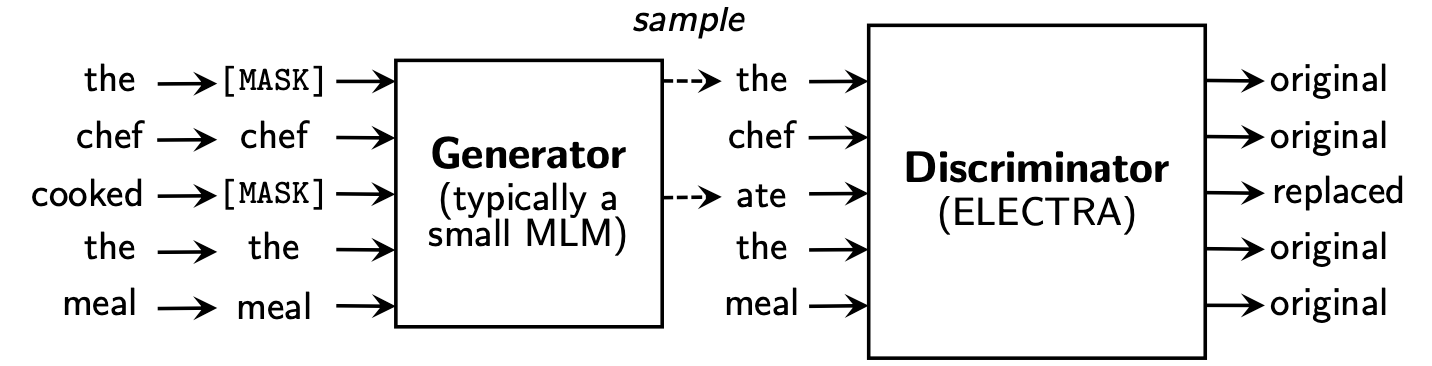
The Electra learns to Replaced Token Detection , by determining whether it is "real" token or "Fake" token in Discriminator. This method has the advantage of being able to learn about all input token, and it has better performance compared to BERT.
KOELECTRA learned in 34GB of Korean text and distributed two models: KoELECTRA-Base and KoELECTRA-Small .
In addition, KoelectRA can be used immediately by installing the Transformers library, regardless of the OS through the WordPIECE and the Model S3 upload .
| Model | Discriminator | Generator | Tensorflow-V1 |
|---|---|---|---|
KoELECTRA-Base-v1 | Discriminator | Generator | Tensorflow-V1 |
KoELECTRA-Small-v1 | Discriminator | Generator | Tensorflow-V1 |
KoELECTRA-Base-v2 | Discriminator | Generator | Tensorflow-V1 |
KoELECTRA-Small-v2 | Discriminator | Generator | Tensorflow-V1 |
KoELECTRA-Base-v3 | Discriminator | Generator | Tensorflow-V1 |
KoELECTRA-Small-v3 | Discriminator | Generator | Tensorflow-V1 |
| Layers | Embedding size | Hidden size | # heads | ||
|---|---|---|---|---|---|
KoELECTRA-Base | Discriminator | 12 | 768 | 768 | 12 |
| Generator | 12 | 768 | 256 | 4 | |
KoELECTRA-Small | Discriminator | 12 | 128 | 256 | 4 |
| Generator | 12 | 128 | 256 | 4 |
Wordpiece used in the original paper and the code without using the SENTENCECE or MECAB.| VOCAB LEN | do_lower_case | |
|---|---|---|
| v1 | 32200 | False |
| v2 | 32200 | False |
| v3 | 35000 | False |
v1 and v2 , we used about 14g Corpus (2.6b tokens). (News, Wiki, Tree Wiki)v3 , we used additional horses of about 20g . (Newspaper, octopus, spoken, messenger, web)| Model | Batch size | Train Steps | LR | Max Seq Len | Generator size | Train Time |
|---|---|---|---|---|---|---|
Base v1,2 | 256 | 700K | 2E-4 | 512 | 0.33 | 7D |
Base v3 | 256 | 1.5m | 2E-4 | 512 | 0.33 | 14D |
Small v1,2 | 512 | 300K | 5E-4 | 512 | 1.0 | 3D |
Small v3 | 512 | 800K | 5E-4 | 512 | 1.0 | 7D |
In the case of KoELECTRA-Small model, the same option as ELECTRA-Small++ in the original paper was used.
KoELECTRA-Base , the model size of Generator and Discriminator (= generator_hidden_size ) is the same. Except for Batch size and Train steps , I took the same as the hyperparameter of the original paper .
I learned using the TPU V3-8 , and the TPU usage in the GCP is summarized in [Using TPU for Pretraining].
It officially supports ElectraModel from Transformers v2.8.0 .
The model is already uploaded to the HUGGingFace S3 , so you can use it immediately without having to download the model directly .
ElectraModel is similar to BertModel , except that it does not return pooled_output .
Electra uses discriminator for finetuning.
from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-discriminator" ) # KoELECTRA-Base
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-discriminator" ) # KoELECTRA-Small
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v2-discriminator" ) # KoELECTRA-Base-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v2-discriminator" ) # KoELECTRA-Small-v2
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" ) # KoELECTRA-Base-v3
model = ElectraModel . from_pretrained ( "monologg/koelectra-small-v3-discriminator" ) # KoELECTRA-Small-v3 from transformers import TFElectraModel
model = TFElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" , from_pt = True ) > >> from transformers import ElectraTokenizer
> >> tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
> >> tokenizer . tokenize ( "[CLS] 한국어 ELECTRA를 공유합니다. [SEP]" )
[ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ]
> >> tokenizer . convert_tokens_to_ids ([ '[CLS]' , '한국어' , 'EL' , '##EC' , '##TRA' , '##를' , '공유' , '##합니다' , '.' , '[SEP]' ])
[ 2 , 11229 , 29173 , 13352 , 25541 , 4110 , 7824 , 17788 , 18 , 3 ]This is the result of the config's setting as it is, and if you add more hyperparameter tuning, you can get better performance.
Please refer to [FINETUNG] for code and details
| NSMC (ACC) | Naver ner (F1) | PAWS (ACC) | Kornli (ACC) | KORSTS (Spearman) | Question Pair (ACC) | Korquad (Dev) (EM/F1) | Korean-Hate-SPEECH (Dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| Kobert | 89.59 | 87.92 | 81.25 | 79.62 | 81.59 | 94.85 | 51.75 / 79.15 | 66.21 |
| XLM-ROBERTA-base | 89.03 | 86.65 | 82.80 | 80.23 | 78.45 | 93.80 | 64.70 / 88.94 | 64.06 |
| Hanbert | 90.06 | 87.70 | 82.95 | 80.32 | 82.73 | 94.72 | 78.74 / 92.02 | 68.32 |
| Koelectra-base | 90.33 | 87.18 | 81.70 | 80.64 | 82.00 | 93.54 | 60.86 / 89.28 | 66.09 |
| Koelectra-Base-V2 | 89.56 | 87.16 | 80.70 | 80.72 | 82.30 | 94.85 | 84.01 / 92.40 | 67.45 |
| Koelectra-Base-V3 | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 | 67.61 |
| NSMC (ACC) | Naver ner (F1) | PAWS (ACC) | Kornli (ACC) | KORSTS (Spearman) | Question Pair (ACC) | Korquad (Dev) (EM/F1) | Korean-Hate-SPEECH (Dev) (F1) | |
|---|---|---|---|---|---|---|---|---|
| DISTILKOBERT | 88.60 | 84.65 | 60.50 | 72.00 | 72.59 | 92.48 | 54.40 / 77.97 | 60.72 |
| Koelectra-Small | 88.83 | 84.38 | 73.10 | 76.45 | 76.56 | 93.01 | 58.04 / 86.76 | 63.03 |
| KoelectRA-SMALL-V2 | 88.83 | 85.00 | 72.35 | 78.14 | 77.84 | 93.27 | 81.43 / 90.46 | 60.14 |
| Koelectra-Small-V3 | 89.36 | 85.40 | 77.45 | 78.60 | 80.79 | 94.85 | 82.11 / 91.13 | 63.07 |
APRIL 27, 2020
KorSTS , QuestionPair ) and updated the results for five existing subtasks.JUNE 3, 2020
KoELECTRA-v2 was created using Vocabulary used in EnlipleAi PLM. Both the base and Small models have improved performance in KorQuaD .October 9, 2020
KoELECTRA-v3 by using additional 모두의 말뭉치 . VOCAB is also newly created using Mecab and Wordpiece .ElectraForSequenceClassification of Huggingface Transformers the existing subtask results are newly update. We also added the results of Korean-Hate-Speech. from transformers import ElectraModel , ElectraTokenizer
model = ElectraModel . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )
tokenizer = ElectraTokenizer . from_pretrained ( "monologg/koelectra-base-v3-discriminator" )May 26, 2021
torch<=1.4 issues that are not loaded (completed re -up load after modifying model) (Related Issue)tensorflow v2 Model Uploaded to HuggingFace Hub ( tf_model.h5 )Oct 20, 2021
tf_model.h5 , there are several issues that are loaded directly from the part of the removal (from loading with from_pt=True ) Koelectra was produced with Cloud TPU support from the Tensorflow Research Cloud (TFRC) program. KoELECTRA-v3 was also produced with the help of all the horse horses .
If you are using this code for research, please quote as follows.
@misc { park2020koelectra ,
author = { Park, Jangwon } ,
title = { KoELECTRA: Pretrained ELECTRA Model for Korean } ,
year = { 2020 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/monologg/KoELECTRA} }
}

