ELF
1.0.0
ELF是用于游戏研究的兴奋性,轻量级和F Lexsible平台,特别是用于实时策略(RTS)游戏。在C ++方面,Elf与C ++线程并联多个游戏。在Python方面,Elf一次返回一批游戏状态,使其对现代RL非常友好。相比之下,其他平台(例如,OpenAi Gym)将一个单个游戏实例与一个Python接口包装。这使得游戏执行有些复杂,这是许多现代强化学习算法的要求。
此外,Elf现在还提供了用于运行并发游戏环境的Python版本,通过与Zeromq Inter-Process Inter-Process通信进行Python多处理。有关一个简单的示例,请参见./ex_elfpy.py 。
对于RTS游戏的研究,Elf配备了快速的RTS引擎和三个混凝土环境:Minirts,捕获国旗和塔式防御。 Minirts具有实时战略游戏的所有关键动力,包括收集资源,建筑设施和部队,在可感知地区以外的未知领土搜寻,并捍卫/攻击敌人。用户可以访问其内部表示形式,并可以自由更改游戏设置。
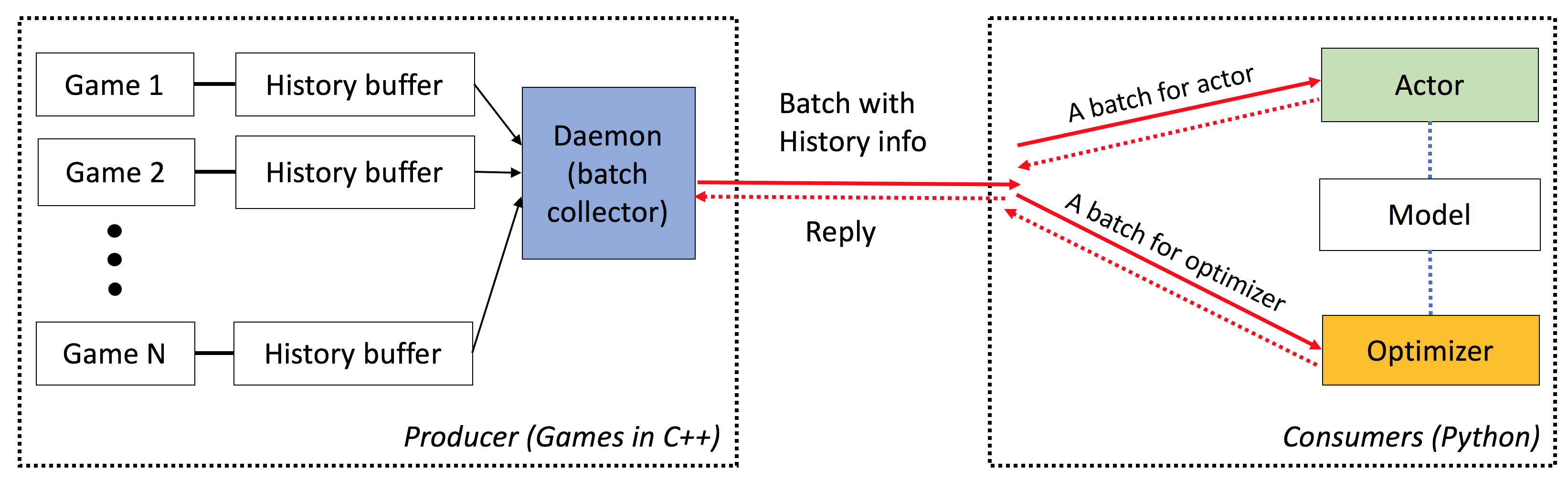
小精灵具有以下特征:
端到端:ELF为游戏研究提供了端到端的解决方案。它提供了微型实时策略游戏环境,并发模拟,直观的API,基于Web的VisualZation,并带有强化学习后端,并由Pytorch赋予了最小的资源要求。
广泛:任何具有C/C ++接口的游戏都可以通过编写简单的包装器插入此框架中。例如,我们已经将Atari Games纳入我们的框架中,并表明每个Core的仿真速度与单核版本相当,因此比使用多处理或Python多线程的实现要快得多。将来,我们计划结合更多的环境,例如,Darkforest GO引擎。
轻量级:小精灵的开销很快。用简单的游戏(Minirts)建立在RTS发动机上的小精灵在MacBook Pro上每秒运行40K帧。从头开始训练模型播放Minirts需要一天的时间为6 CPU + 1 GPU 。
灵活:环境和参与者之间的配对非常灵活,例如一种环境,一种环境(例如,香草A3C),一个具有多种代理的环境(例如,自我播放/MCT)或一个与一个参与者(例如,batcha3c,ga3c)。同样,在RTS引擎顶部建造的任何游戏都可以完全访问其内部表示形式和动态。除了有效的模拟器外,我们还提供了一个轻巧而强大的增强学习框架。该框架可以托管大多数现有的RL算法。在此开源版本中,我们提供了用Pytorch编写的最先进的演员批评算法。
请参阅此处。
您需要让cmake > = 3.8, gcc > = 4.9和tbb (Linux libtbb-dev )才能成功安装此脚本。
# Download miniconda and install.
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -O $HOME/miniconda.sh
/bin/bash $HOME/miniconda.sh -b
$HOME/miniconda3/bin/conda update -y --all python=3
# Add the following to ~/.bash_profile (if you haven't already) and source it:
export PATH=$HOME/miniconda3/bin:$PATH
# Create a new conda environment and install the necessary packages:
conda create -n elf python=3
source activate elf
# If you use cuda 8.0
# conda install pytorch cuda80 -c soumith
conda install pytorch -c soumith
pip install --upgrade pip
pip install msgpack_numpy
conda install tqdm
conda install libgcc
# Install cmake >= 3.8, gcc >= 4.9 and libtbb-dev
# This is platform-dependent.
# Clone and build the repository:
cd ~
git clone https://github.com/facebookresearch/ELF
cd ELF/rts/
mkdir build && cd build
cmake .. -DPYTHON_EXECUTABLE=$HOME/miniconda3/bin/python
make
# Train the model
cd ../..
sh ./train_minirts.sh --gpu 0
任何具有C/C ++接口的游戏都可以通过编写简单的包装器插入此框架中。目前,我们有以下环境:
Minirts及其扩展( ./rts )
一个微型的实时战略游戏,捕捉了其类型的关键动力,包括建筑工人,收集资源,探索看不见的领土,捍卫敌人并攻击他们。该游戏的运行速度非常快(在笔记本电脑上每核40k fps),以促进许多现有的政策增强学习方法的使用。
Atari Games ( ./atari atari)
我们将街机学习环境(ALE)纳入精灵,以便您可以加载任何ROM并轻松运行1000个并发游戏实例。
去引擎( ./go )
我们在Elf Platform中重新实现了Darkforest Go Engine。现在,您可以轻松地加载一堆.sgf文件,并以最小的资源要求训练自己的AI(即单个GPU加一个星期)。
使用精灵时,请参考以下Bibtex条目的论文:
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Yuandong Tian, Qucheng Gong, Wenling Shang, Yuxin Wu, C. Lawrence Zitnick
NIPS 2017
@article{tian2017elf,
title={ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games},
author={Yuandong Tian and Qucheng Gong and Wenling Shang and Yuxin Wu and C. Lawrence Zitnick},
journal={Advances in Neural Information Processing Systems (NIPS)},
year={2017}
}
ICML视频游戏和机器学习(VGML)研讨会的幻灯片。
演示。左上是受过训练的机器人,而底部是基于规则的机器人。
在此处查看详细文档。您也可以使用sphinx在./doc中编译版本。
小精灵很容易使用。初始化看起来如下:
# We run 1024 games concurrently.
num_games = 1024
# Wait for a batch of 256 games.
batchsize = 256
# The return states contain key 's', 'r' and 'terminal'
# The reply contains key 'a' to be filled from the Python side.
# The definitions of the keys are in the wrapper of the game.
input_spec = dict ( s = '' , r = '' , terminal = '' )
reply_spec = dict ( a = '' )
context = Init ( num_games , batchsize , input_spec , reply_spec )主循环也非常简单:
# Start all game threads and enter main loop.
context . Start ()
while True :
# Wait for a batch of game states to be ready
# These games will be blocked, waiting for replies.
batch = context . Wait ()
# Apply a model to the game state. The output has key 'pi'
# You can do whatever you want here. E.g., applying your favorite RL algorithms.
output = model ( batch )
# Sample from the output to get the actions of this batch.
reply [ 'a' ][:] = SampleFromDistribution ( output )
# Resume games.
context . Steps ()
# Stop all game threads.
context . Stop () 请检查train.py和eval.py的实际可运行代码。
需要具有C ++ 11支持的C ++编译器(例如,GCC> = 4.9)。需要以下tbb 。 CMAKE> = 3.8也需要。
需要Python 3.x。此外,您需要安装以下软件包:Pytorch版本0.2.0+, tqdm , zmq , msgpack , msgpack_numpy
要训练Minirts的型号,请首先编译./rts/game_MC (请参阅使用cmake中的./rts/中的说明)。请注意,除非您想查看可视./rts/backend ,否则不需要培训。
然后,请在当前目录中运行以下命令(您也可以参考train_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 train.py
--num_games 1024 --batchsize 128 # Set number of games to be 1024 and batchsize to be 128.
--freq_update 50 # Update behavior policy after 50 updates of the model.
--players " fs=50,type=AI_NN,args=backup/AI_SIMPLE|delay/0.99|start/500;fs=20,type=AI_SIMPLE " # Specify AI and its opponent, separated by semicolon. `fs` is frameskip that specifies How often your opponent makes a decision (e.g., fs=20 means it acts every 20 ticks)
# If `backup` is specified in `args`, then we use rule-based AI for the first `start` ticks, then trained AI takes over. `start` decays with rate `decay`.
--tqdm # Show progress bar.
--gpu 0 # Use first gpu. If you don't specify gpu, it will run on CPUs.
--T 20 # 20 step actor-critic
--additional_labels id,last_terminal
--trainer_stats winrate # If you want to see the winrate over iterations.
# Note that the winrate is computed when the action is sampled from the multinomial distribution (not greedy policy).
# To evaluate your model more accurately, please use eval.py.请注意,较长的地平线(例如, --T 20 )可以使训练更快,并且(同时)稳定。借助Long Horizon,您应该能够在12小时内使用16CPU和1GPU在12小时内将其训练为70%。您可以使用taskset -c控制培训中使用的CPU数量。
这是一个受过训练的模型,具有80%的获胜AI_SIMPLE ,而frameskip = 50。这是一个游戏重播。
以下是培训过程中的样本输出:
Version: bf1304010f9609b2114a1adff4aa2eb338695b9d_staged
Num Actions: 9
Num unittype: 6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5000/5000 [01:35<00:00, 52.37it/s]
[2017-07-12 09:04:13.212017][128] Iter[0]:
Train count: 820/5000, actor count: 4180/5000
Save to ./
Filename = ./save-820.bin
Command arguments run.py --batchsize 128 --freq_update 50 --fs_opponent 20 --latest_start 500 --latest_start_decay 0.99 --num_games 1024 --opponent_type AI_SIMPLE --tqdm
0:acc_reward[4100]: avg: -0.34079, min: -0.58232[1580], max: 0.25949[185]
0:cost[4100]: avg: 2.15912, min: 1.97886[2140], max: 2.31487[1173]
0:entropy_err[4100]: avg: -2.13493, min: -2.17945[438], max: -2.04809[1467]
0:init_reward[820]: avg: -0.34093, min: -0.56980[315], max: 0.26211[37]
0:policy_err[4100]: avg: 2.16714, min: 1.98384[1520], max: 2.31068[1176]
0:predict_reward[4100]: avg: -0.33676, min: -1.36083[1588], max: 0.39551[195]
0:reward[4100]: avg: -0.01153, min: -0.13281[1109], max: 0.04688[124]
0:rms_advantage[4100]: avg: 0.15646, min: 0.02189[800], max: 0.79827[564]
0:value_err[4100]: avg: 0.01333, min: 0.00024[800], max: 0.06569[1549]
86%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 4287/5000 [01:23<00:15, 46.97it/s]
要评估Minirts的模型,请尝试以下命令(您还可以参考eval_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 eval.py
--load [your model]
--batchsize 128
--players " fs=50,type=AI_NN;fs=20,type=AI_SIMPLE "
--num_games 1024
--num_eval 10000
--tqdm # Nice progress bar
--gpu 0 # Use GPU 0 as the evaluation gpu.
--additional_labels id # Tell the game environment to output additional dict entries.
--greedy # Use greedy policy to evaluate your model. If not specified, then it will sample from the action distributions. 这是一个示例输出(用12个CPU评估10K游戏需要1分钟40秒):
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
Load from ./save-212808.bin
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
100%|████████████████████████████████████████████████████████████████████████████████████████████| 10000/10000 [01:40<00:00, 99.94it/s]
str_acc_win_rate: Accumulated win rate: 0.735 [7295/2628/9923]
best_win_rate: 0.7351607376801297
new_record: True
count: 0
str_win_rate: [0] Win rate: 0.735 [7295/2628/9923], Best win rate: 0.735 [0]
Stop all game threads ...
如果您想在Minirts中进行自我播放,请尝试以下脚本。它将从两个机器人开始,均以预训练的模型开始。一个机器人将随着时间的推移进行训练,而另一个机器人将固定。如果您只想在没有培训的情况下检查他们的获胜率,请尝试--actor_only 。
sh ./selfplay_minirts.sh [your pre-trained model]
要可视化训练有素的机器人,您可以指定--save_replay_prefix [replay_file_prefix]运行eval.py以保存(大量)重播。请注意,同一标志也可以应用于训练/自我播放。
所有重播文件都包含动作序列,在.rep中,并且在加载时应重现完全相同的游戏。要加载重播在命令行中,请使用以下内容:
./minirts-backend replay --load_replay [your replay] --vis_after 0并打开网页./rts/frontend/minirts.html检查游戏。要在命令行中加载并运行重播(例如,如果您只想快速看到谁赢得比赛),请尝试:
./minirts-backend replay_cmd --load_replay [your replay]

