ELF
1.0.0
ELF-это ELFSE , LEALWEEELE и F LEXIBLE для Game Research, в частности для игр стратегии в реальном времени (RTS). На стороне C ++ ELF проводит несколько игр параллельно с потоком C ++. На стороне Python Elf возвращает одну партию игрового состояния за раз, что делает его очень дружелюбным для современного RL. Для сравнения, другие платформы (например, Gym Openai) завершают один экземпляр игры одним интерфейсом Python. Это делает одновременное выполнение игры немного сложным, что является требованием многих современных алгоритмов обучения подкреплению.
Кроме того, ELF теперь также предоставляет версию Python для запуска одновременных игровых среда, путем многопроцессы Python с помощью взаимодействия Zeromq. Смотрите ./ex_elfpy.py для простого примера.
Для исследований в области игр RTS ELF поставляется с быстрым двигателем RTS и тремя конкретными средами: министерства, захватывает защиту флага и башню. У Minirts есть вся ключевая динамика стратегической игры в реальном времени, в том числе сборы ресурсов, строительные объекты и войска, поиск неизвестных территорий за пределами воспринимаемых регионов и защищать/атаковать врага. Пользователь может получить доступ к своему внутреннему представлению и может свободно изменить настройку игры.
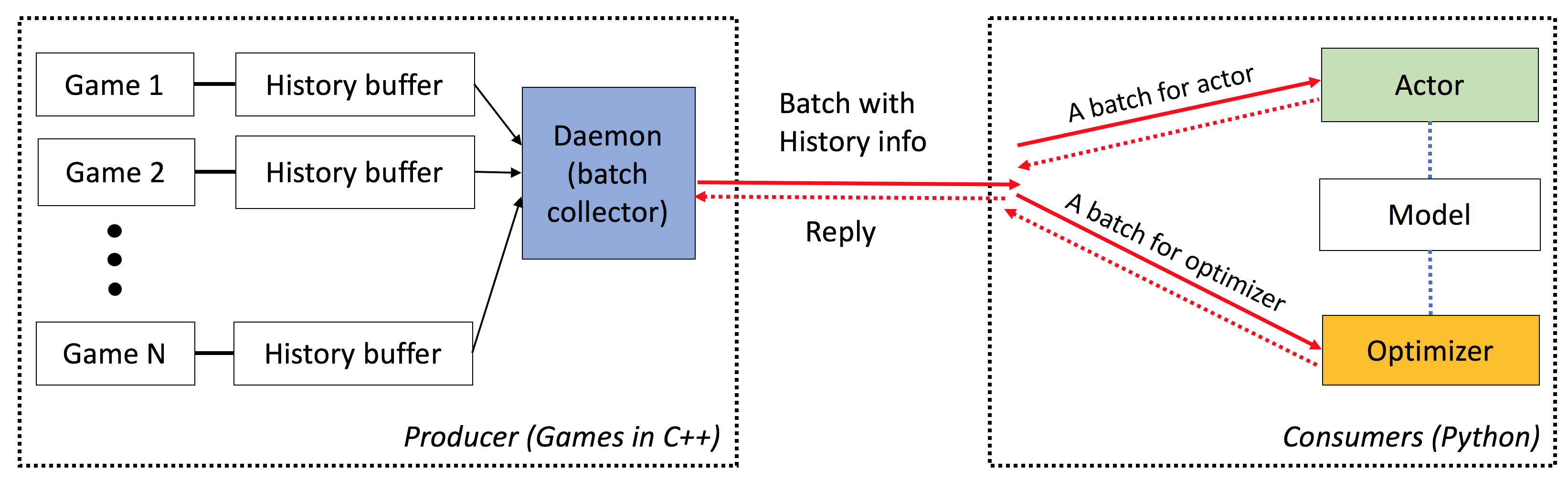
Эльф имеет следующие характеристики:
Следует : ELF предлагает сквозное решение для исследований игровых исследований. Он обеспечивает миниатюрную стратегическую игровую среду, одновременную моделирование, интуитивно понятные API, веб-визуализацию, а также поставляется с подкреплением обучения, уполномоченного Pytorch с минимальными ресурсами.
Обширный : любая игра с интерфейсом C/C ++ может быть подключена к этой структуре, написав простую обертку. Например, мы уже включаем игры Atari в нашу структуру и показываем, что скорость моделирования на ядро сопоставимо с одноядерной версией и, следовательно, намного быстрее, чем реализация с использованием многопроцессорного или многопоточного чтения Python. В будущем мы планируем включить больше средств, например, DarkForest Go Engine.
Легкий : эльф работает очень быстро с минимальными накладными расходами. Эльф с простым игрой (миниртами), построенной на двигателе RTS, запускает 40 тыс. Кадр в секунду на ядро на MacBook Pro. Обучение модели с нуля, чтобы играть в Minirts, занимает день на 6 ЦП + 1 графический процессор .
Гибкое : сочетание между средами и актерами очень гибкое, например, одна среда с одним агентом (например, ванилью A3C), одна среда с несколькими агентами (например, самопостановка/MCT) или множество среды с одним актером (например, BatchA3C, GA3C). Кроме того, любая игра, построенная на вершине двигателя RTS, предлагает полный доступ к его внутреннему представлению и динамике. Помимо эффективных симуляторов, мы также предоставляем легкую, но мощную структуру обучения подкрепления. Эта структура может размещать большинство существующих алгоритмов RL. В этом выпуске с открытым исходным кодом мы предоставили современные актерские алгоритмы, написанные в Pytorch.
Смотрите здесь.
Вам нужно иметь cmake > = 3,8, gcc > = 4,9 и tbb (Linux libtbb-dev ), чтобы успешно установить этот скрипт.
# Download miniconda and install.
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -O $HOME/miniconda.sh
/bin/bash $HOME/miniconda.sh -b
$HOME/miniconda3/bin/conda update -y --all python=3
# Add the following to ~/.bash_profile (if you haven't already) and source it:
export PATH=$HOME/miniconda3/bin:$PATH
# Create a new conda environment and install the necessary packages:
conda create -n elf python=3
source activate elf
# If you use cuda 8.0
# conda install pytorch cuda80 -c soumith
conda install pytorch -c soumith
pip install --upgrade pip
pip install msgpack_numpy
conda install tqdm
conda install libgcc
# Install cmake >= 3.8, gcc >= 4.9 and libtbb-dev
# This is platform-dependent.
# Clone and build the repository:
cd ~
git clone https://github.com/facebookresearch/ELF
cd ELF/rts/
mkdir build && cd build
cmake .. -DPYTHON_EXECUTABLE=$HOME/miniconda3/bin/python
make
# Train the model
cd ../..
sh ./train_minirts.sh --gpu 0
Любая игра с интерфейсом C/C ++ может быть подключена к этой структуре, написав простую обертку. В настоящее время у нас есть следующая среда:
Минирты и его расширения ( ./rts )
Миниатюрная стратегическая игра в реальном времени, которая отражает ключевую динамику его жанра, включая строительства работников, сбор ресурсов, изучение невидимых территорий, защищает врага и атакует их. Игра работает чрезвычайно быстро (40 тыс. Фунтов на ядро на ноутбуке), чтобы способствовать использованию многих существующих подходов к подкреплению на политике.
Атари игры ( ./atari )
Мы включаем в эльф в ELF среду Arcade (ALE), чтобы вы могли легко загрузить любой ПЗУ и легко запустить 1000 одновременных игровых экземпляров.
Go Engine ( ./go )
Мы переосмысливаем наш двигатель DarkForest Go на платформе ELF. Теперь вы можете легко загрузить кучу файлов .sgf и обучить свой собственный AI с минимальными требованиями к ресурсам (т.е. один графический процессор плюс неделю).
Когда вы используете ELF, обратитесь к бумаге со следующей записью Bibtex:
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Yuandong Tian, Qucheng Gong, Wenling Shang, Yuxin Wu, C. Lawrence Zitnick
NIPS 2017
@article{tian2017elf,
title={ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games},
author={Yuandong Tian and Qucheng Gong and Wenling Shang and Yuxin Wu and C. Lawrence Zitnick},
journal={Advances in Neural Information Processing Systems (NIPS)},
year={2017}
}
Слайды в видеоиграх ICML и семинаре машинного обучения (VGML).
Демо. Верхний левый-обученный бот, а правая нижняя-это бот, основанный на правилах.
Проверьте здесь подробную документацию. Вы также можете собрать свою версию в ./doc , используя sphinx .
Эльф очень прост в использовании. Инициализация выглядит как следующее:
# We run 1024 games concurrently.
num_games = 1024
# Wait for a batch of 256 games.
batchsize = 256
# The return states contain key 's', 'r' and 'terminal'
# The reply contains key 'a' to be filled from the Python side.
# The definitions of the keys are in the wrapper of the game.
input_spec = dict ( s = '' , r = '' , terminal = '' )
reply_spec = dict ( a = '' )
context = Init ( num_games , batchsize , input_spec , reply_spec )Основная петля также очень проста:
# Start all game threads and enter main loop.
context . Start ()
while True :
# Wait for a batch of game states to be ready
# These games will be blocked, waiting for replies.
batch = context . Wait ()
# Apply a model to the game state. The output has key 'pi'
# You can do whatever you want here. E.g., applying your favorite RL algorithms.
output = model ( batch )
# Sample from the output to get the actions of this batch.
reply [ 'a' ][:] = SampleFromDistribution ( output )
# Resume games.
context . Steps ()
# Stop all game threads.
context . Stop () Пожалуйста, проверьте train.py и eval.py для реальных запускаемых кодов.
Компилятор C ++ с поддержкой C ++ 11 (например, GCC> = 4,9) требуется. Следующие библиотеки требуются tbb . Cmake> = 3,8 также требуется.
Python 3.x требуется. Кроме того, вам необходимо установить следующий пакет: Pytorch версия 0.2.0+, tqdm , zmq , msgpack , msgpack_numpy
Чтобы обучить модель для министертов, пожалуйста, сначала компилируйте ./rts/game_MC (см. Инструкцию в ./rts/ с использованием cmake ). Обратите внимание, что компиляция ./rts/backend не требуется для обучения, если вы не хотите видеть визуализацию.
Затем, пожалуйста, запустите следующие команды в текущем каталоге (вы также можете ссылаться на train_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 train.py
--num_games 1024 --batchsize 128 # Set number of games to be 1024 and batchsize to be 128.
--freq_update 50 # Update behavior policy after 50 updates of the model.
--players " fs=50,type=AI_NN,args=backup/AI_SIMPLE|delay/0.99|start/500;fs=20,type=AI_SIMPLE " # Specify AI and its opponent, separated by semicolon. `fs` is frameskip that specifies How often your opponent makes a decision (e.g., fs=20 means it acts every 20 ticks)
# If `backup` is specified in `args`, then we use rule-based AI for the first `start` ticks, then trained AI takes over. `start` decays with rate `decay`.
--tqdm # Show progress bar.
--gpu 0 # Use first gpu. If you don't specify gpu, it will run on CPUs.
--T 20 # 20 step actor-critic
--additional_labels id,last_terminal
--trainer_stats winrate # If you want to see the winrate over iterations.
# Note that the winrate is computed when the action is sampled from the multinomial distribution (not greedy policy).
# To evaluate your model more accurately, please use eval.py. Обратите внимание, что Long Horizon (например, --T 20 ) может сделать обучение намного быстрее и (в то же время) стабильным. С Long Horizon вы должны быть в состоянии обучить его 70% WinRate в течение 12 часов с 16CPU и 1GPU. Вы можете контролировать количество процессоров, используемых в обучении, используя taskset -c .
Вот одна обученная модель с 80% WinRate против AI_SIMPLE для Frameskip = 50. Вот одно воспроизведение игры.
Ниже приведен пример вывода во время обучения:
Version: bf1304010f9609b2114a1adff4aa2eb338695b9d_staged
Num Actions: 9
Num unittype: 6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5000/5000 [01:35<00:00, 52.37it/s]
[2017-07-12 09:04:13.212017][128] Iter[0]:
Train count: 820/5000, actor count: 4180/5000
Save to ./
Filename = ./save-820.bin
Command arguments run.py --batchsize 128 --freq_update 50 --fs_opponent 20 --latest_start 500 --latest_start_decay 0.99 --num_games 1024 --opponent_type AI_SIMPLE --tqdm
0:acc_reward[4100]: avg: -0.34079, min: -0.58232[1580], max: 0.25949[185]
0:cost[4100]: avg: 2.15912, min: 1.97886[2140], max: 2.31487[1173]
0:entropy_err[4100]: avg: -2.13493, min: -2.17945[438], max: -2.04809[1467]
0:init_reward[820]: avg: -0.34093, min: -0.56980[315], max: 0.26211[37]
0:policy_err[4100]: avg: 2.16714, min: 1.98384[1520], max: 2.31068[1176]
0:predict_reward[4100]: avg: -0.33676, min: -1.36083[1588], max: 0.39551[195]
0:reward[4100]: avg: -0.01153, min: -0.13281[1109], max: 0.04688[124]
0:rms_advantage[4100]: avg: 0.15646, min: 0.02189[800], max: 0.79827[564]
0:value_err[4100]: avg: 0.01333, min: 0.00024[800], max: 0.06569[1549]
86%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 4287/5000 [01:23<00:15, 46.97it/s]
Чтобы оценить модель для юниртов, попробуйте следующую команду (вы также можете ссылаться на eval_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 eval.py
--load [your model]
--batchsize 128
--players " fs=50,type=AI_NN;fs=20,type=AI_SIMPLE "
--num_games 1024
--num_eval 10000
--tqdm # Nice progress bar
--gpu 0 # Use GPU 0 as the evaluation gpu.
--additional_labels id # Tell the game environment to output additional dict entries.
--greedy # Use greedy policy to evaluate your model. If not specified, then it will sample from the action distributions. Вот пример вывода (требуется 1 мин 40 секунд, чтобы оценить 10K игр с 12 процессорами):
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
Load from ./save-212808.bin
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
100%|████████████████████████████████████████████████████████████████████████████████████████████| 10000/10000 [01:40<00:00, 99.94it/s]
str_acc_win_rate: Accumulated win rate: 0.735 [7295/2628/9923]
best_win_rate: 0.7351607376801297
new_record: True
count: 0
str_win_rate: [0] Win rate: 0.735 [7295/2628/9923], Best win rate: 0.735 [0]
Stop all game threads ...
Попробуйте следующий сценарий, если вы хотите самостоятельно выполнять самостоятельные работы в министерствах. Он начнется с двух ботов, оба начиная с предварительно обученной модели. Один бот будет обучаться с течением времени, а другой - фиксированным. Если вы просто хотите проверить их Winrate без обучения, попробуйте --actor_only .
sh ./selfplay_minirts.sh [your pre-trained model]
Чтобы визуализировать обученный бот, вы можете указать --save_replay_prefix [replay_file_prefix] при запуске eval.py для сохранения (много) повтор. Обратите внимание, что тот же флаг также может быть применен к обучению/самостоятельному самостоятельному.
Все файлы воспроизведения содержат последовательности действий, находятся в .rep и должны воспроизводить ту же игру при загрузке. Чтобы загрузить повтор в командной строке, используя следующее:
./minirts-backend replay --load_replay [your replay] --vis_after 0 и откройте веб -страницу ./rts/frontend/minirts.html чтобы проверить игру. Чтобы загрузить и запустить повтор только в командной строке (например, если вы просто хотите быстро увидеть, кто выиграет игру), попробуйте:
./minirts-backend replay_cmd --load_replay [your replay]

