ELF
1.0.0
Elf est une plate-forme e xtsense, l i ightweights et flexible pour la recherche de jeux, en particulier pour les jeux de stratégie en temps réel (RTS). Du côté C ++, ELF héberge plusieurs jeux en parallèle avec le filetage C ++. Du côté de Python, Elf renvoie un lot d'état de jeu à la fois, ce qui le rend très amical pour RL moderne. En comparaison, d'autres plates-formes (par exemple, Openai Gym) enveloppent une seule instance de jeu avec une interface Python. Cela rend l'exécution de jeux simultanée un peu compliquée, ce qui est une exigence de nombreux algorithmes d'apprentissage de renforcement modernes.
En outre, Elf fournit désormais également une version Python pour exécuter des environnements de jeu simultanés, par multiprocessement Python avec la communication interprète Zeromq. Voir ./ex_elfpy.py pour un exemple simple.
Pour la recherche sur les jeux RTS, ELF est livré avec un moteur RTS rapide et trois environnements en béton: les minimies, capturez le drapeau et la défense de la tour. Minirts a toute la dynamique clé d'un jeu de stratégie en temps réel, notamment la collecte de ressources, la construction d'installations et les troupes, le dépistage des territoires inconnus en dehors des régions perceptibles et défendre / attaquer l'ennemi. L'utilisateur peut accéder à sa représentation interne et peut changer librement le paramètre de jeu.
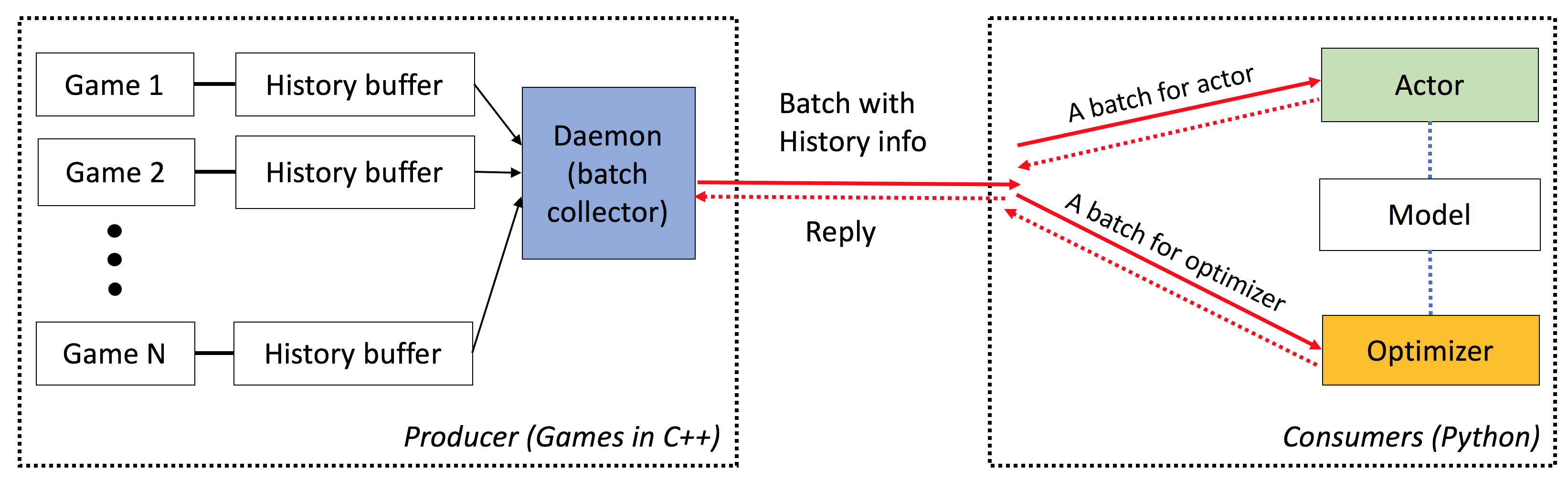
ELF a les caractéristiques suivantes:
De bout en bout : ELF propose une solution de bout en bout à la recherche sur le jeu. Il fournit des environnements de jeu de stratégie miniatures en temps réel, une simulation simultanée, des API intuitives, une visualité en ligne, et est également livré avec un backend d'apprentissage de renforcement habilité par Pytorch avec une exigence de ressources minimale.
Extensif : tout jeu avec l'interface C / C ++ peut être branché sur ce cadre en écrivant un simple wrapper. Par exemple, nous incorporons déjà les jeux Atari dans notre cadre et montrons que la vitesse de simulation par noyau est comparable à la version à noyau unique, et est donc beaucoup plus rapide que la mise en œuvre en utilisant le multiprocessement ou le multithon python. À l'avenir, nous prévoyons d'incorporer plus d'environnements, par exemple, le moteur DarkForest Go.
Léger : l'elfe fonctionne très rapidement avec un minimum de frais généraux. Elfe avec un jeu simple (minimaux) construit sur le moteur RTS exécute un cadre 40k par seconde par noyau sur un MacBook Pro. La formation d'un modèle à partir de zéro pour jouer à des minimises prend une journée sur 6 CPU + 1 GPU .
Flexible : l'appariement entre les environnements et les acteurs est très flexible, par exemple, un environnement avec un seul agent (par exemple, vanille A3C), un environnement avec plusieurs agents (par exemple, auto-play / MCTS) ou un environnement multiple avec un acteur (par exemple, Batcha3c, GA3C). De plus, tout jeu construit sur le moteur RTS offre un accès complet à sa représentation interne et à sa dynamique. Outre les simulateurs efficaces, nous fournissons également un cadre d'apprentissage de renforcement léger mais puissant. Ce cadre peut héberger la plupart des algorithmes RL existants. Dans cette version open source, nous avons fourni des algorithmes acteurs-critiques de pointe, écrits en pytorch.
Voir ici.
Vous devez avoir cmake > = 3,8, gcc > = 4.9 et tbb (Linux libtbb-dev ) afin d'installer ce script avec succès.
# Download miniconda and install.
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -O $HOME/miniconda.sh
/bin/bash $HOME/miniconda.sh -b
$HOME/miniconda3/bin/conda update -y --all python=3
# Add the following to ~/.bash_profile (if you haven't already) and source it:
export PATH=$HOME/miniconda3/bin:$PATH
# Create a new conda environment and install the necessary packages:
conda create -n elf python=3
source activate elf
# If you use cuda 8.0
# conda install pytorch cuda80 -c soumith
conda install pytorch -c soumith
pip install --upgrade pip
pip install msgpack_numpy
conda install tqdm
conda install libgcc
# Install cmake >= 3.8, gcc >= 4.9 and libtbb-dev
# This is platform-dependent.
# Clone and build the repository:
cd ~
git clone https://github.com/facebookresearch/ELF
cd ELF/rts/
mkdir build && cd build
cmake .. -DPYTHON_EXECUTABLE=$HOME/miniconda3/bin/python
make
# Train the model
cd ../..
sh ./train_minirts.sh --gpu 0
Tout jeu avec l'interface C / C ++ peut être branché sur ce cadre en écrivant un simple wrapper. Actuellement, nous avons l'environnement suivant:
Minirts et ses extensions ( ./rts )
Un jeu de stratégie miniature en temps réel qui capture la dynamique clé de son genre, y compris les travailleurs de la construction, la collecte de ressources, l'exploration des territoires invisibles, défend l'ennemi et les attaquer. Le jeu fonctionne extrêmement rapide (40k ips par noyau sur un ordinateur portable) pour faciliter l'utilisation de nombreuses approches d'apprentissage de renforcement sur la politique existantes.
Games atari ( ./atari )
Nous incorporons Arcade Learning Environment (ALE) dans ELF afin que vous puissiez charger toute ROM et exécuter 1000 instances de jeu simultanées facilement.
Go Engine ( ./go )
Nous replions notre moteur GO Darkforest dans la plate-forme ELF. Maintenant, vous pouvez facilement charger un tas de fichiers .sgf et former votre propre AI GO avec des exigences de ressources minimales (c'est-à-dire un seul GPU plus une semaine).
Lorsque vous utilisez ELF, veuillez référencer le document avec l'entrée Bibtex suivante:
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Yuandong Tian, Qucheng Gong, Wenling Shang, Yuxin Wu, C. Lawrence Zitnick
NIPS 2017
@article{tian2017elf,
title={ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games},
author={Yuandong Tian and Qucheng Gong and Wenling Shang and Yuxin Wu and C. Lawrence Zitnick},
journal={Advances in Neural Information Processing Systems (NIPS)},
year={2017}
}
Diapositives dans les jeux vidéo ICML et l'atelier d'apprentissage automatique (VGML).
Démo. Top-gauche est un bot formé tandis que le bas-droit est un bot basé sur des règles.
Vérifiez ici pour une documentation détaillée. Vous pouvez également compiler votre version dans ./doc à l'aide de sphinx .
ELF est très facile à utiliser. L'initialisation ressemble à ce qui suit:
# We run 1024 games concurrently.
num_games = 1024
# Wait for a batch of 256 games.
batchsize = 256
# The return states contain key 's', 'r' and 'terminal'
# The reply contains key 'a' to be filled from the Python side.
# The definitions of the keys are in the wrapper of the game.
input_spec = dict ( s = '' , r = '' , terminal = '' )
reply_spec = dict ( a = '' )
context = Init ( num_games , batchsize , input_spec , reply_spec )La boucle principale est également très simple:
# Start all game threads and enter main loop.
context . Start ()
while True :
# Wait for a batch of game states to be ready
# These games will be blocked, waiting for replies.
batch = context . Wait ()
# Apply a model to the game state. The output has key 'pi'
# You can do whatever you want here. E.g., applying your favorite RL algorithms.
output = model ( batch )
# Sample from the output to get the actions of this batch.
reply [ 'a' ][:] = SampleFromDistribution ( output )
# Resume games.
context . Steps ()
# Stop all game threads.
context . Stop () Veuillez vérifier train.py et eval.py pour les codes de course réels.
Le compilateur C ++ avec le support C ++ 11 (par exemple, gcc> = 4.9) est requis. Les bibliothèques suivantes sont requises tbb . Cmake> = 3,8 est également requis.
Python 3.x est requis. De plus, vous devez installer le package suivant: Pytorch Version 0.2.0+, tqdm , zmq , msgpack , msgpack_numpy
Pour former un modèle pour les minimises, veuillez d'abord compiler ./rts/game_MC (voir l'instruction dans ./rts/ en utilisant cmake ). Notez qu'une compilation de ./rts/backend n'est pas nécessaire pour la formation, sauf si vous voulez voir la visualisation.
Ensuite, veuillez exécuter les commandes suivantes dans le répertoire actuel (vous pouvez également référencer train_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 train.py
--num_games 1024 --batchsize 128 # Set number of games to be 1024 and batchsize to be 128.
--freq_update 50 # Update behavior policy after 50 updates of the model.
--players " fs=50,type=AI_NN,args=backup/AI_SIMPLE|delay/0.99|start/500;fs=20,type=AI_SIMPLE " # Specify AI and its opponent, separated by semicolon. `fs` is frameskip that specifies How often your opponent makes a decision (e.g., fs=20 means it acts every 20 ticks)
# If `backup` is specified in `args`, then we use rule-based AI for the first `start` ticks, then trained AI takes over. `start` decays with rate `decay`.
--tqdm # Show progress bar.
--gpu 0 # Use first gpu. If you don't specify gpu, it will run on CPUs.
--T 20 # 20 step actor-critic
--additional_labels id,last_terminal
--trainer_stats winrate # If you want to see the winrate over iterations.
# Note that the winrate is computed when the action is sampled from the multinomial distribution (not greedy policy).
# To evaluate your model more accurately, please use eval.py. Notez qu'un long horizon (par exemple, --T 20 ) pourrait rendre la formation beaucoup plus rapide et (en même temps) stable. Avec Long Horizon, vous devriez être en mesure de l'entraîner à 70% de victoire dans les 12 heures avec 16 cpu et 1gpu. Vous pouvez contrôler le nombre de processeurs utilisés dans la formation à l'aide taskset -c .
Voici un modèle formé avec 80% de victimes contre AI_SIMPLE pour Frameskip = 50. Voici une relecture de jeu.
Ce qui suit est un échantillon de sortie pendant la formation:
Version: bf1304010f9609b2114a1adff4aa2eb338695b9d_staged
Num Actions: 9
Num unittype: 6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5000/5000 [01:35<00:00, 52.37it/s]
[2017-07-12 09:04:13.212017][128] Iter[0]:
Train count: 820/5000, actor count: 4180/5000
Save to ./
Filename = ./save-820.bin
Command arguments run.py --batchsize 128 --freq_update 50 --fs_opponent 20 --latest_start 500 --latest_start_decay 0.99 --num_games 1024 --opponent_type AI_SIMPLE --tqdm
0:acc_reward[4100]: avg: -0.34079, min: -0.58232[1580], max: 0.25949[185]
0:cost[4100]: avg: 2.15912, min: 1.97886[2140], max: 2.31487[1173]
0:entropy_err[4100]: avg: -2.13493, min: -2.17945[438], max: -2.04809[1467]
0:init_reward[820]: avg: -0.34093, min: -0.56980[315], max: 0.26211[37]
0:policy_err[4100]: avg: 2.16714, min: 1.98384[1520], max: 2.31068[1176]
0:predict_reward[4100]: avg: -0.33676, min: -1.36083[1588], max: 0.39551[195]
0:reward[4100]: avg: -0.01153, min: -0.13281[1109], max: 0.04688[124]
0:rms_advantage[4100]: avg: 0.15646, min: 0.02189[800], max: 0.79827[564]
0:value_err[4100]: avg: 0.01333, min: 0.00024[800], max: 0.06569[1549]
86%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 4287/5000 [01:23<00:15, 46.97it/s]
Pour évaluer un modèle pour Minirts, essayez la commande suivante (vous pouvez également référencer eval_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 eval.py
--load [your model]
--batchsize 128
--players " fs=50,type=AI_NN;fs=20,type=AI_SIMPLE "
--num_games 1024
--num_eval 10000
--tqdm # Nice progress bar
--gpu 0 # Use GPU 0 as the evaluation gpu.
--additional_labels id # Tell the game environment to output additional dict entries.
--greedy # Use greedy policy to evaluate your model. If not specified, then it will sample from the action distributions. Voici un exemple de sortie (il faut 1 min 40 secondes pour évaluer les jeux 10k avec 12 CPU):
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
Load from ./save-212808.bin
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
100%|████████████████████████████████████████████████████████████████████████████████████████████| 10000/10000 [01:40<00:00, 99.94it/s]
str_acc_win_rate: Accumulated win rate: 0.735 [7295/2628/9923]
best_win_rate: 0.7351607376801297
new_record: True
count: 0
str_win_rate: [0] Win rate: 0.735 [7295/2628/9923], Best win rate: 0.735 [0]
Stop all game threads ...
Essayez le script suivant si vous voulez faire de l'auto-play dans Minirts. Il commencera avec deux robots, tous deux à commencer par le modèle pré-formé. Un bot sera formé au fil du temps, tandis que l'autre est tenu fixe. Si vous voulez simplement vérifier leur Winrate sans vous entraîner, essayez --actor_only .
sh ./selfplay_minirts.sh [your pre-trained model]
Pour visualiser un bot formé, vous pouvez spécifier --save_replay_prefix [replay_file_prefix] lors de l'exécution eval.py pour enregistrer (beaucoup de) rediffusions. Notez que le même drapeau peut également être appliqué à la formation / à l'auto-jeu.
Tous les fichiers de relecture contiennent des séquences d'action, sont dans .rep et doivent reproduire exactement le même jeu lorsqu'ils sont chargés. Pour charger la rediffusion dans la ligne de commande, en utilisant les éléments suivants:
./minirts-backend replay --load_replay [your replay] --vis_after 0 et ouvrez la page Web ./rts/frontend/minirts.html pour vérifier le jeu. Pour charger et exécuter la rediffusion dans la ligne de commande uniquement (par exemple, si vous voulez juste voir rapidement qui gagner le jeu), essayez:
./minirts-backend replay_cmd --load_replay [your replay]

