ELF
1.0.0
ELF هي منصة e xtulars و L ightweight و f Lexible لأبحاث اللعبة ، لا سيما لألعاب الاستراتيجية في الوقت الفعلي (RTS). على الجانب C ++ ، يستضيف ELF ألعاب متعددة بالتوازي مع خيط C ++. على جانب Python ، يعيد Elf مجموعة واحدة من لعبة Game State في وقت واحد ، مما يجعلها ودية للغاية لـ RL Modern. وبالمقارنة ، تلتف المنصات الأخرى (على سبيل المثال ، Openai Gym) مثيل لعبة واحدة مع واجهة Python واحدة. هذا يجعل تنفيذ اللعبة المتزامن معقدًا بعض الشيء ، وهو مطلب من العديد من خوارزميات تعلم التعزيز الحديثة.
علاوة على ذلك ، يوفر ELF الآن أيضًا إصدار Python لتشغيل بيئات اللعبة المتزامنة ، عن طريق المعالجة المتعددة Python مع التواصل بين المعالجة Zeromq. انظر ./ex_elfpy.py للحصول على مثال بسيط.
للبحث في ألعاب RTS ، يأتي ELF مع محرك RTS سريعًا ، وثلاث بيئات ملموسة: التصوير ، والتقاط العلم والدفاع. لدى Minirts جميع الديناميات الرئيسية للعبة الإستراتيجية في الوقت الفعلي ، بما في ذلك جمع الموارد وبناء المرافق والقوات ، واستكشاف الأراضي غير المعروفة خارج المناطق التي يمكن إدراكها ، والدفاع/مهاجمة العدو. يمكن للمستخدم الوصول إلى تمثيله الداخلي ويمكنه تغيير إعداد اللعبة بحرية.
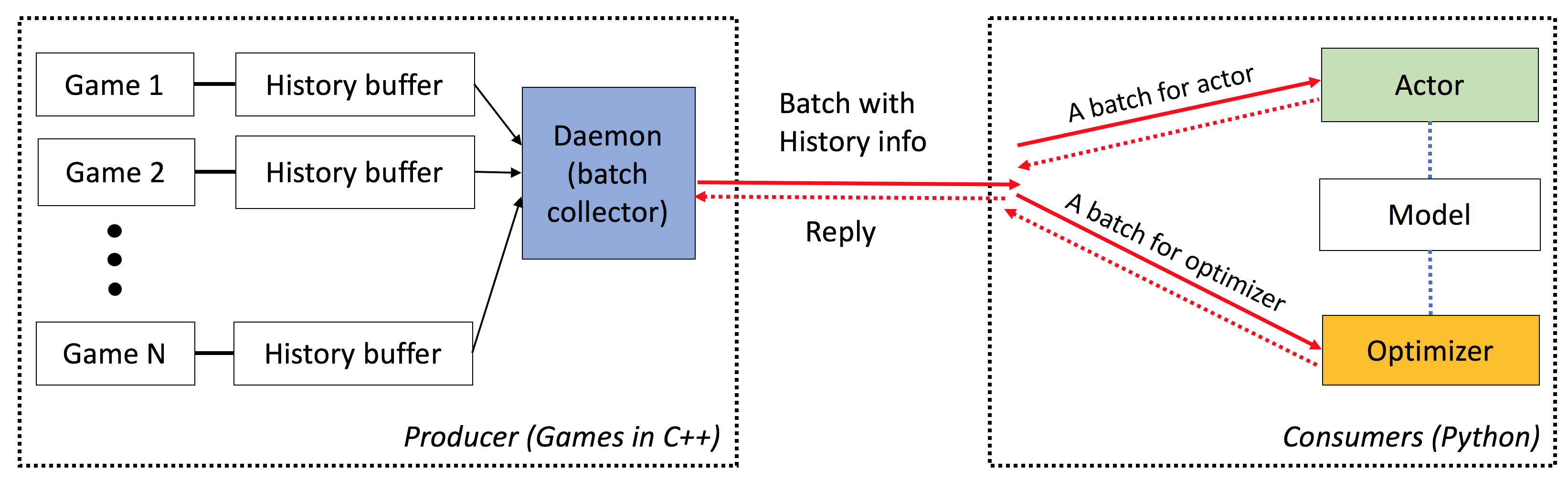
القزم لديه الخصائص التالية:
من طرف إلى طرف : يقدم ELF حلاً شاملاً لأبحاث اللعبة. إنه يوفر بيئات ألعاب الإستراتيجية المصغرة في الوقت الفعلي ، والمحاكاة المتزامنة ، وواجهة برمجة التطبيقات البديهية ، والبصرية المستندة إلى الويب ، وتأتي أيضًا مع الواجهة الخلفية للتعلم التعزيز التي يتم تمكينها بواسطة Pytorch مع الحد الأدنى من متطلبات الموارد.
واسعة : يمكن توصيل أي لعبة مع واجهة C/C ++ في هذا الإطار عن طريق كتابة غلاف بسيط. على سبيل المثال ، ندمج بالفعل ألعاب ATARI في إطارنا ونظهر أن سرعة المحاكاة لكل قلب قابلة للمقارنة مع إصدار أحادي النواة ، وبالتالي فهي أسرع بكثير من التنفيذ باستخدام إما المعالجة المتعددة أو Python MultiThreading. في المستقبل ، نخطط لدمج المزيد من البيئات ، على سبيل المثال ، محرك Darkforest Go.
خفيفة الوزن : ELF يعمل بسرعة كبيرة مع الحد الأدنى من النفقات العامة. يعمل ELF مع لعبة بسيطة (Minirts) المبنية على RTS Engine إطار 40K في الثانية الواحدة لكل نواة على جهاز MacBook Pro. يستغرق تدريب نموذج من نقطة الصفر للعب الصغرات يومًا على 6 وحدة المعالجة المركزية + 1 وحدة معالجة الرسومات .
مرن : الاقتران بين البيئات والممثلين مرن للغاية ، على سبيل المثال ، بيئة واحدة مع وكيل واحد (على سبيل المثال ، الفانيليا A3C) ، بيئة واحدة مع عوامل متعددة (على سبيل المثال ، لتلعب الذات/MCTS) ، أو بيئة متعددة مع ممثل واحد (على سبيل المثال ، Batcha3C ، GA3C). أيضًا ، توفر أي لعبة تم تصميمها على قمة محرك RTS الوصول الكامل إلى تمثيله الداخلي ودينامياته. إلى جانب أجهزة المحاكاة الفعالة ، فإننا نقدم أيضًا إطارًا خفيفًا لخفيف الوزن ولكنه قوي للتعلم. يمكن لهذا الإطار استضافة معظم خوارزميات RL الموجودة. في هذا الإصدار المفتوح المصدر ، قدمنا خوارزميات ممثقة مؤلفة من الأمام ، مكتوبة في Pytorch.
انظر هنا.
يجب أن يكون لديك cmake > = 3.8 و gcc > = 4.9 و tbb (Linux libtbb-dev ) من أجل تثبيت هذا البرنامج النصي بنجاح.
# Download miniconda and install.
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -O $HOME/miniconda.sh
/bin/bash $HOME/miniconda.sh -b
$HOME/miniconda3/bin/conda update -y --all python=3
# Add the following to ~/.bash_profile (if you haven't already) and source it:
export PATH=$HOME/miniconda3/bin:$PATH
# Create a new conda environment and install the necessary packages:
conda create -n elf python=3
source activate elf
# If you use cuda 8.0
# conda install pytorch cuda80 -c soumith
conda install pytorch -c soumith
pip install --upgrade pip
pip install msgpack_numpy
conda install tqdm
conda install libgcc
# Install cmake >= 3.8, gcc >= 4.9 and libtbb-dev
# This is platform-dependent.
# Clone and build the repository:
cd ~
git clone https://github.com/facebookresearch/ELF
cd ELF/rts/
mkdir build && cd build
cmake .. -DPYTHON_EXECUTABLE=$HOME/miniconda3/bin/python
make
# Train the model
cd ../..
sh ./train_minirts.sh --gpu 0
يمكن توصيل أي لعبة مع واجهة C/C ++ في هذا الإطار عن طريق كتابة غلاف بسيط. حاليا لدينا البيئة التالية:
تصفيفات وملحقاتها ( ./rts )
لعبة استراتيجية مصغرة في الوقت الفعلي تلتقط الديناميات الرئيسية لنوعها ، بما في ذلك بناء العمال ، وجمع الموارد ، واستكشاف الأراضي غير المرئية ، والدفاع عن العدو ومهاجمةهم. تعمل اللعبة بسرعة كبيرة (40K FPS لكل قلب على جهاز كمبيوتر محمول) لتسهيل استخدام العديد من أساليب التعلم المعززة على الجودة.
ألعاب أتاري ( ./atari )
ندمج بيئة التعلم الممرات (ALE) في ELF بحيث يمكنك تحميل أي ROM وتشغيل 1000 مثيلات اللعبة المتزامنة بسهولة.
اذهب للمحرك ( ./go )
نحن نعيد تنفيذ محرك Darkforest Go لدينا في منصة ELF. الآن يمكنك بسهولة تحميل مجموعة من ملفات .SGF وتدريب GO AI مع الحد الأدنى من متطلبات الموارد (أي ، وحدة معالجة الرسومات واحدة بالإضافة إلى أسبوع).
عند استخدام ELF ، يرجى الرجوع إلى الورقة مع إدخال Bibtex التالي:
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Yuandong Tian, Qucheng Gong, Wenling Shang, Yuxin Wu, C. Lawrence Zitnick
NIPS 2017
@article{tian2017elf,
title={ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games},
author={Yuandong Tian and Qucheng Gong and Wenling Shang and Yuxin Wu and C. Lawrence Zitnick},
journal={Advances in Neural Information Processing Systems (NIPS)},
year={2017}
}
الشرائح في ورشة عمل ألعاب الفيديو ICML وتعلم الآلة (VGML).
العرض التوضيحي. يتم تدريب أعلى اليسار على الروبوت في حين أن اليمين السفلي هو الروبوت القائم على القواعد.
تحقق هنا للحصول على وثائق مفصلة. يمكنك أيضًا تجميع نسختك في ./doc باستخدام sphinx .
قزم سهل الاستخدام للغاية. يبدو أن التهيئة ما يلي:
# We run 1024 games concurrently.
num_games = 1024
# Wait for a batch of 256 games.
batchsize = 256
# The return states contain key 's', 'r' and 'terminal'
# The reply contains key 'a' to be filled from the Python side.
# The definitions of the keys are in the wrapper of the game.
input_spec = dict ( s = '' , r = '' , terminal = '' )
reply_spec = dict ( a = '' )
context = Init ( num_games , batchsize , input_spec , reply_spec )الحلقة الرئيسية بسيطة للغاية أيضًا:
# Start all game threads and enter main loop.
context . Start ()
while True :
# Wait for a batch of game states to be ready
# These games will be blocked, waiting for replies.
batch = context . Wait ()
# Apply a model to the game state. The output has key 'pi'
# You can do whatever you want here. E.g., applying your favorite RL algorithms.
output = model ( batch )
# Sample from the output to get the actions of this batch.
reply [ 'a' ][:] = SampleFromDistribution ( output )
# Resume games.
context . Steps ()
# Stop all game threads.
context . Stop () يرجى التحقق من train.py و eval.py للرموز الفعلية القابلة للتشغيل.
مطلوب برنامج التحويل البرمجي C ++ مع دعم C ++ 11 (على سبيل المثال ، GCC> = 4.9). المكتبات التالية مطلوبة tbb . Cmake> = 3.8 مطلوب أيضا.
Python 3.x مطلوب. بالإضافة إلى ذلك ، تحتاج إلى تثبيت الحزمة التالية: إصدار Pytorch 0.2.0+ ، tqdm ، zmq ، msgpack ، msgpack_numpy
لتدريب نموذج للتنورات ، يرجى أولاً ترجمة ./rts/game_MC (راجع التعليمات في ./rts/ باستخدام cmake ). لاحظ أن تجميع ./rts/backend ليس ضروريًا للتدريب ، إلا إذا كنت ترغب في رؤية التصور.
ثم يرجى تشغيل الأوامر التالية في الدليل الحالي (يمكنك أيضًا مرجع train_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 train.py
--num_games 1024 --batchsize 128 # Set number of games to be 1024 and batchsize to be 128.
--freq_update 50 # Update behavior policy after 50 updates of the model.
--players " fs=50,type=AI_NN,args=backup/AI_SIMPLE|delay/0.99|start/500;fs=20,type=AI_SIMPLE " # Specify AI and its opponent, separated by semicolon. `fs` is frameskip that specifies How often your opponent makes a decision (e.g., fs=20 means it acts every 20 ticks)
# If `backup` is specified in `args`, then we use rule-based AI for the first `start` ticks, then trained AI takes over. `start` decays with rate `decay`.
--tqdm # Show progress bar.
--gpu 0 # Use first gpu. If you don't specify gpu, it will run on CPUs.
--T 20 # 20 step actor-critic
--additional_labels id,last_terminal
--trainer_stats winrate # If you want to see the winrate over iterations.
# Note that the winrate is computed when the action is sampled from the multinomial distribution (not greedy policy).
# To evaluate your model more accurately, please use eval.py. لاحظ أن Long Horizon (على سبيل المثال ، --T 20 ) يمكن أن يجعل التدريب أسرع بكثير و (في نفس الوقت) مستقر. مع Long Horizon ، يجب أن تكون قادرًا على تدريبه على الفوز بنسبة 70 ٪ في غضون 12 ساعة مع 16CPU و 1GPU. يمكنك التحكم في عدد وحدات المعالجة المركزية المستخدمة في التدريب باستخدام taskset -c .
هنا نموذج واحد مدرب مع 80 ٪ winrate ضد AI_SIMPLE ل frameskip = 50. هنا إعادة لعبة واحدة.
فيما يلي عينة ناتج أثناء التدريب:
Version: bf1304010f9609b2114a1adff4aa2eb338695b9d_staged
Num Actions: 9
Num unittype: 6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5000/5000 [01:35<00:00, 52.37it/s]
[2017-07-12 09:04:13.212017][128] Iter[0]:
Train count: 820/5000, actor count: 4180/5000
Save to ./
Filename = ./save-820.bin
Command arguments run.py --batchsize 128 --freq_update 50 --fs_opponent 20 --latest_start 500 --latest_start_decay 0.99 --num_games 1024 --opponent_type AI_SIMPLE --tqdm
0:acc_reward[4100]: avg: -0.34079, min: -0.58232[1580], max: 0.25949[185]
0:cost[4100]: avg: 2.15912, min: 1.97886[2140], max: 2.31487[1173]
0:entropy_err[4100]: avg: -2.13493, min: -2.17945[438], max: -2.04809[1467]
0:init_reward[820]: avg: -0.34093, min: -0.56980[315], max: 0.26211[37]
0:policy_err[4100]: avg: 2.16714, min: 1.98384[1520], max: 2.31068[1176]
0:predict_reward[4100]: avg: -0.33676, min: -1.36083[1588], max: 0.39551[195]
0:reward[4100]: avg: -0.01153, min: -0.13281[1109], max: 0.04688[124]
0:rms_advantage[4100]: avg: 0.15646, min: 0.02189[800], max: 0.79827[564]
0:value_err[4100]: avg: 0.01333, min: 0.00024[800], max: 0.06569[1549]
86%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 4287/5000 [01:23<00:15, 46.97it/s]
لتقييم نموذج للتنورات ، جرب الأمر التالي (يمكنك أيضًا الرجوع إلى eval_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 eval.py
--load [your model]
--batchsize 128
--players " fs=50,type=AI_NN;fs=20,type=AI_SIMPLE "
--num_games 1024
--num_eval 10000
--tqdm # Nice progress bar
--gpu 0 # Use GPU 0 as the evaluation gpu.
--additional_labels id # Tell the game environment to output additional dict entries.
--greedy # Use greedy policy to evaluate your model. If not specified, then it will sample from the action distributions. فيما يلي مثال على الإخراج (يستغرق 1 دقيقة 40 ثانية لتقييم 10K ألعاب مع 12 وحدة المعالجة المركزية):
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
Load from ./save-212808.bin
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
100%|████████████████████████████████████████████████████████████████████████████████████████████| 10000/10000 [01:40<00:00, 99.94it/s]
str_acc_win_rate: Accumulated win rate: 0.735 [7295/2628/9923]
best_win_rate: 0.7351607376801297
new_record: True
count: 0
str_win_rate: [0] Win rate: 0.735 [7295/2628/9923], Best win rate: 0.735 [0]
Stop all game threads ...
جرب البرنامج النصي التالي إذا كنت ترغب في القيام بالتشغيل الذاتي في التصوير. سيبدأ مع اثنين من الروبوتات ، كلاهما بدءا من النموذج الذي تم تدريبه مسبقًا. سيتم تدريب واحد من الروبوت مع مرور الوقت ، بينما يتم تثبيت الآخر. إذا كنت ترغب فقط في التحقق من Winrate دون تدريب ، حاول --actor_only .
sh ./selfplay_minirts.sh [your pre-trained model]
لتصور روبوت مدرب ، يمكنك تحديد --save_replay_prefix [replay_file_prefix] عند تشغيل eval.py لحفظ (الكثير من) إعادة. لاحظ أنه يمكن أيضًا تطبيق العلم نفسه على التدريب/اللعب بنفسه.
تحتوي جميع ملفات إعادة التشغيل على تسلسلات عمل ، في .rep ويجب إعادة إنتاج نفس اللعبة بالضبط عند تحميلها. لتحميل إعادة التشغيل في سطر الأوامر ، باستخدام ما يلي:
./minirts-backend replay --load_replay [your replay] --vis_after 0 وافتح صفحة الويب ./rts/frontend/minirts.html للتحقق من اللعبة. لتحميل وتشغيل إعادة التشغيل في سطر الأوامر فقط (على سبيل المثال ، إذا كنت تريد فقط معرفة من يفوز في اللعبة) ، حاول:
./minirts-backend replay_cmd --load_replay [your replay]

