ELF
1.0.0
ELF adalah platform extensive , l ightweight dan f lexible untuk riset game, khususnya untuk game strategi real-time (RTS). Di sisi C ++-ELF host beberapa game secara paralel dengan Threading C ++. Di sisi Python, Elf mengembalikan satu batch Game State sekaligus, membuatnya sangat ramah untuk RL modern. Sebagai perbandingan, platform lain (misalnya, Openai Gym) membungkus satu instance game tunggal dengan satu antarmuka Python. Ini membuat eksekusi game bersamaan agak rumit, yang merupakan persyaratan dari banyak algoritma pembelajaran penguatan modern.
Selain itu, ELF sekarang juga menyediakan versi Python untuk menjalankan lingkungan game bersamaan, dengan multiproses python dengan komunikasi antar-proses nolomq. Lihat ./ex_elfpy.py untuk contoh sederhana.
Untuk penelitian tentang game RTS, ELF dilengkapi dengan mesin RTS cepat, dan tiga lingkungan beton: Minirts, menangkap bendera dan pertahanan menara. Minirts memiliki semua dinamika kunci dari permainan strategi real-time, termasuk mengumpulkan sumber daya, fasilitas bangunan dan pasukan, mengintai wilayah yang tidak dikenal di luar daerah yang dapat dipahami, dan membela/menyerang musuh. Pengguna dapat mengakses representasi internalnya dan dapat dengan bebas mengubah pengaturan game.
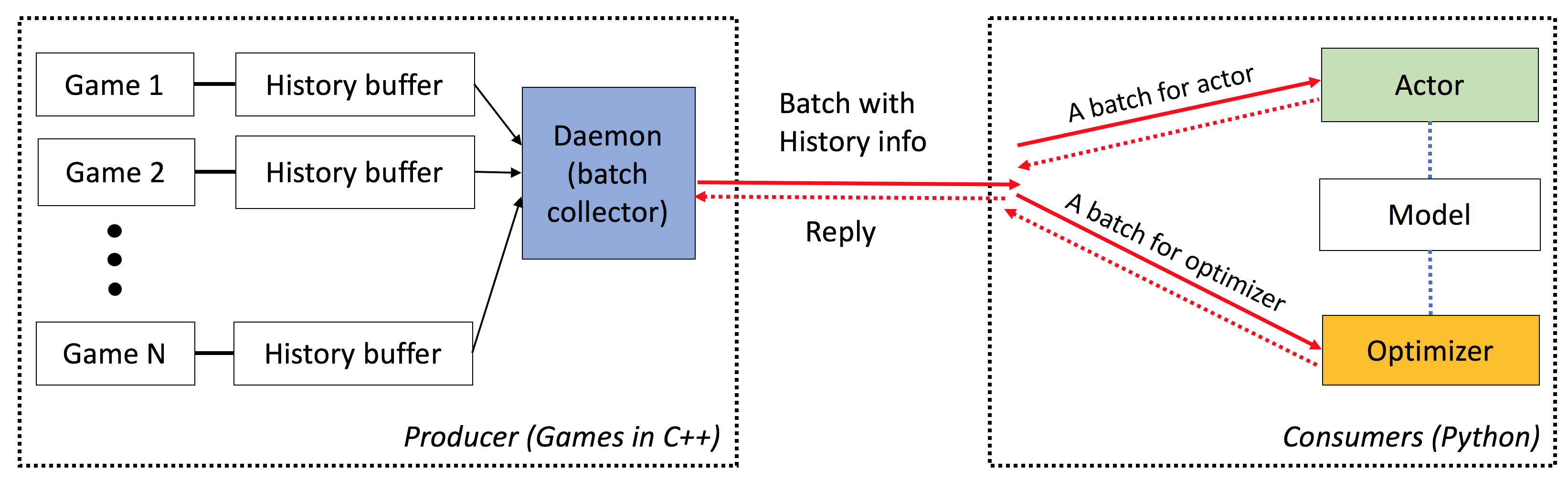
ELF memiliki karakteristik berikut:
End-to-end : ELF menawarkan solusi ujung ke ujung untuk riset game. Ini memberikan miniatur lingkungan permainan strategi real-time, simulasi bersamaan, API intuitif, visualzasi berbasis web, dan juga dilengkapi dengan penguatan pembelajaran backend yang diberdayakan oleh Pytorch dengan persyaratan sumber daya minimal.
Luas : Permainan apa pun dengan antarmuka C/C ++ dapat dicolokkan ke dalam kerangka kerja ini dengan menulis pembungkus sederhana. Sebagai contoh, kami sudah memasukkan game Atari ke dalam kerangka kerja kami dan menunjukkan bahwa kecepatan simulasi per inti sebanding dengan versi inti tunggal, dan dengan demikian jauh lebih cepat daripada implementasi menggunakan multiprosesing atau multithreading Python. Di masa depan, kami berencana untuk menggabungkan lebih banyak lingkungan, misalnya, mesin go darkforest.
Ringan : Elf berjalan sangat cepat dengan overhead minimal. ELF dengan game sederhana (minirts) yang dibangun di atas mesin RTS menjalankan bingkai 40k per detik per inti pada MacBook Pro. Melatih model dari awal untuk bermain minirts membutuhkan waktu satu hari di 6 CPU + 1 GPU .
Fleksibel : Pemasangan antara lingkungan dan aktor sangat fleksibel, misalnya satu lingkungan dengan satu agen (misalnya, vanilla A3C), satu lingkungan dengan beberapa agen (misalnya, mandiri/MCT), atau beberapa lingkungan dengan satu aktor (misalnya, batcha3c, GA3C). Juga, permainan apa pun yang dibangun di atas mesin RTS menawarkan akses penuh ke representasi dan dinamika internal. Selain simulator yang efisien, kami juga memberikan kerangka pembelajaran penguatan yang ringan namun kuat. Kerangka kerja ini dapat meng -host sebagian besar algoritma RL yang ada. Dalam rilis open source ini, kami telah menyediakan algoritma aktor-kritik yang canggih, yang ditulis dalam Pytorch.
Lihat di sini.
Anda perlu memiliki cmake > = 3.8, gcc > = 4.9 dan tbb (linux libtbb-dev ) untuk menginstal skrip ini dengan sukses.
# Download miniconda and install.
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -O $HOME/miniconda.sh
/bin/bash $HOME/miniconda.sh -b
$HOME/miniconda3/bin/conda update -y --all python=3
# Add the following to ~/.bash_profile (if you haven't already) and source it:
export PATH=$HOME/miniconda3/bin:$PATH
# Create a new conda environment and install the necessary packages:
conda create -n elf python=3
source activate elf
# If you use cuda 8.0
# conda install pytorch cuda80 -c soumith
conda install pytorch -c soumith
pip install --upgrade pip
pip install msgpack_numpy
conda install tqdm
conda install libgcc
# Install cmake >= 3.8, gcc >= 4.9 and libtbb-dev
# This is platform-dependent.
# Clone and build the repository:
cd ~
git clone https://github.com/facebookresearch/ELF
cd ELF/rts/
mkdir build && cd build
cmake .. -DPYTHON_EXECUTABLE=$HOME/miniconda3/bin/python
make
# Train the model
cd ../..
sh ./train_minirts.sh --gpu 0
Game apa pun dengan antarmuka C/C ++ dapat dicolokkan ke dalam kerangka kerja ini dengan menulis pembungkus sederhana. Saat ini kami memiliki lingkungan berikut:
Minirts dan ekstensi ( ./rts )
Permainan strategi real-time miniatur yang menangkap dinamika kunci genre-nya, termasuk pekerja membangun, mengumpulkan sumber daya, menjelajahi wilayah yang tidak terlihat, membela musuh dan menyerang mereka kembali. Gim ini berjalan sangat cepat (40k fps per inti pada laptop) untuk memfasilitasi penggunaan banyak pendekatan pembelajaran penguatan-kebijakan yang ada.
Game Atari ( ./atari )
Kami menggabungkan Lingkungan Belajar Arcade (ALE) ke dalam ELF sehingga Anda dapat memuat ROM apa pun dan menjalankan 1000 instance game bersamaan dengan mudah.
Go Engine ( ./go )
Kami mengimplementasikan mesin go gelap kami di platform ELF. Sekarang Anda dapat dengan mudah memuat banyak file .sgf dan melatih AI Go sendiri dengan persyaratan sumber daya minimal (yaitu, satu GPU plus seminggu).
Saat Anda menggunakan ELF, silakan merujuk kertas dengan entri Bibtex berikut:
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Yuandong Tian, Qucheng Gong, Wenling Shang, Yuxin Wu, C. Lawrence Zitnick
NIPS 2017
@article{tian2017elf,
title={ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games},
author={Yuandong Tian and Qucheng Gong and Wenling Shang and Yuxin Wu and C. Lawrence Zitnick},
journal={Advances in Neural Information Processing Systems (NIPS)},
year={2017}
}
Slide di ICML Video Game dan Machine Learning (VGML) Workshop.
Demo. Left-left dilatih bot sedangkan kanan bawah adalah bot berbasis aturan.
Periksa di sini untuk dokumentasi terperinci. Anda juga dapat mengkompilasi versi Anda di ./doc menggunakan sphinx .
Elf sangat mudah digunakan. Inisialisasi terlihat seperti berikut:
# We run 1024 games concurrently.
num_games = 1024
# Wait for a batch of 256 games.
batchsize = 256
# The return states contain key 's', 'r' and 'terminal'
# The reply contains key 'a' to be filled from the Python side.
# The definitions of the keys are in the wrapper of the game.
input_spec = dict ( s = '' , r = '' , terminal = '' )
reply_spec = dict ( a = '' )
context = Init ( num_games , batchsize , input_spec , reply_spec )Loop utama juga sangat sederhana:
# Start all game threads and enter main loop.
context . Start ()
while True :
# Wait for a batch of game states to be ready
# These games will be blocked, waiting for replies.
batch = context . Wait ()
# Apply a model to the game state. The output has key 'pi'
# You can do whatever you want here. E.g., applying your favorite RL algorithms.
output = model ( batch )
# Sample from the output to get the actions of this batch.
reply [ 'a' ][:] = SampleFromDistribution ( output )
# Resume games.
context . Steps ()
# Stop all game threads.
context . Stop () Silakan periksa train.py dan eval.py untuk kode runnable yang sebenarnya.
Kompiler C ++ dengan dukungan C ++ 11 (misalnya, GCC> = 4.9) diperlukan. Perpustakaan berikut diperlukan tbb . CMake> = 3.8 juga diperlukan.
Python 3.x diperlukan. Selain itu, Anda perlu menginstal paket berikut: PyTorch Versi 0.2.0+, tqdm , zmq , msgpack , msgpack_numpy
Untuk melatih model untuk minirts, silakan kompilasi terlebih dahulu ./rts/game_MC (lihat instruksi di ./rts/ menggunakan cmake ). Perhatikan bahwa kompilasi ./rts/backend tidak diperlukan untuk pelatihan, kecuali jika Anda ingin melihat visualisasi.
Kemudian silakan jalankan perintah berikut di direktori saat ini (Anda juga dapat merujuk train_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 train.py
--num_games 1024 --batchsize 128 # Set number of games to be 1024 and batchsize to be 128.
--freq_update 50 # Update behavior policy after 50 updates of the model.
--players " fs=50,type=AI_NN,args=backup/AI_SIMPLE|delay/0.99|start/500;fs=20,type=AI_SIMPLE " # Specify AI and its opponent, separated by semicolon. `fs` is frameskip that specifies How often your opponent makes a decision (e.g., fs=20 means it acts every 20 ticks)
# If `backup` is specified in `args`, then we use rule-based AI for the first `start` ticks, then trained AI takes over. `start` decays with rate `decay`.
--tqdm # Show progress bar.
--gpu 0 # Use first gpu. If you don't specify gpu, it will run on CPUs.
--T 20 # 20 step actor-critic
--additional_labels id,last_terminal
--trainer_stats winrate # If you want to see the winrate over iterations.
# Note that the winrate is computed when the action is sampled from the multinomial distribution (not greedy policy).
# To evaluate your model more accurately, please use eval.py. Perhatikan bahwa cakrawala panjang (misalnya --T 20 ) dapat membuat pelatihan lebih cepat dan (pada saat yang sama) stabil. Dengan cakrawala panjang, Anda harus dapat melatihnya ke 70% winrate dalam waktu 12 jam dengan 16cpu dan 1GPU. Anda dapat mengontrol jumlah CPU yang digunakan dalam pelatihan menggunakan taskset -c .
Berikut adalah satu model yang terlatih dengan 80% winrate melawan AI_SIMPLE untuk Frameskip = 50. Ini satu permainan replay.
Berikut ini adalah output sampel selama pelatihan:
Version: bf1304010f9609b2114a1adff4aa2eb338695b9d_staged
Num Actions: 9
Num unittype: 6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5000/5000 [01:35<00:00, 52.37it/s]
[2017-07-12 09:04:13.212017][128] Iter[0]:
Train count: 820/5000, actor count: 4180/5000
Save to ./
Filename = ./save-820.bin
Command arguments run.py --batchsize 128 --freq_update 50 --fs_opponent 20 --latest_start 500 --latest_start_decay 0.99 --num_games 1024 --opponent_type AI_SIMPLE --tqdm
0:acc_reward[4100]: avg: -0.34079, min: -0.58232[1580], max: 0.25949[185]
0:cost[4100]: avg: 2.15912, min: 1.97886[2140], max: 2.31487[1173]
0:entropy_err[4100]: avg: -2.13493, min: -2.17945[438], max: -2.04809[1467]
0:init_reward[820]: avg: -0.34093, min: -0.56980[315], max: 0.26211[37]
0:policy_err[4100]: avg: 2.16714, min: 1.98384[1520], max: 2.31068[1176]
0:predict_reward[4100]: avg: -0.33676, min: -1.36083[1588], max: 0.39551[195]
0:reward[4100]: avg: -0.01153, min: -0.13281[1109], max: 0.04688[124]
0:rms_advantage[4100]: avg: 0.15646, min: 0.02189[800], max: 0.79827[564]
0:value_err[4100]: avg: 0.01333, min: 0.00024[800], max: 0.06569[1549]
86%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 4287/5000 [01:23<00:15, 46.97it/s]
Untuk mengevaluasi model untuk minirts, coba perintah berikut (Anda juga dapat merujuk eval_minirts.sh ):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 eval.py
--load [your model]
--batchsize 128
--players " fs=50,type=AI_NN;fs=20,type=AI_SIMPLE "
--num_games 1024
--num_eval 10000
--tqdm # Nice progress bar
--gpu 0 # Use GPU 0 as the evaluation gpu.
--additional_labels id # Tell the game environment to output additional dict entries.
--greedy # Use greedy policy to evaluate your model. If not specified, then it will sample from the action distributions. Berikut adalah contoh output (dibutuhkan 1 menit 40 detik untuk mengevaluasi 10K game dengan 12 CPU):
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
Load from ./save-212808.bin
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
100%|████████████████████████████████████████████████████████████████████████████████████████████| 10000/10000 [01:40<00:00, 99.94it/s]
str_acc_win_rate: Accumulated win rate: 0.735 [7295/2628/9923]
best_win_rate: 0.7351607376801297
new_record: True
count: 0
str_win_rate: [0] Win rate: 0.735 [7295/2628/9923], Best win rate: 0.735 [0]
Stop all game threads ...
Cobalah skrip berikut jika Anda ingin bermain sendiri di Minirts. Ini akan dimulai dengan dua bot, keduanya dimulai dengan model pra-terlatih. Satu bot akan dilatih dari waktu ke waktu, sementara yang lain ditahan. Jika Anda hanya ingin memeriksa winrate mereka tanpa pelatihan, coba --actor_only .
sh ./selfplay_minirts.sh [your pre-trained model]
Untuk memvisualisasikan bot terlatih, Anda dapat menentukan --save_replay_prefix [replay_file_prefix] saat menjalankan eval.py untuk menyimpan (banyak) replay. Perhatikan bahwa bendera yang sama juga dapat diterapkan pada pelatihan/mandiri.
Semua file replay berisi urutan tindakan, berada di .rep dan harus mereproduksi game yang sama persis saat dimuat. Untuk memuat replay di baris perintah, menggunakan yang berikut:
./minirts-backend replay --load_replay [your replay] --vis_after 0 dan buka halaman web ./rts/frontend/minirts.html untuk memeriksa game. Untuk memuat dan menjalankan replay di baris perintah saja (misalnya, jika Anda hanya ingin dengan cepat melihat siapa yang memenangkan permainan), coba:
./minirts-backend replay_cmd --load_replay [your replay]

