ELF
1.0.0
ELF ist eine E - xtive-Plattform für die Spiele, insbesondere für Echtzeit-Strategie (RTS) -Plattagen . Auf der C ++-Seite veranstaltet Elf mehrere Spiele parallel zum C ++-Threading. Auf der Python -Seite gibt Elf jeweils eine Menge Spielstatus zurück, was es für die moderne RL sehr freundlich macht. Im Vergleich dazu wickeln andere Plattformen (z. B. Openai Gym) eine einzige Spielinstanz mit einer Python -Schnittstelle. Dies macht die gleichzeitige Spielexekution etwas kompliziert, was viele moderne Algorithmen für Verstärkungslernen erfordert.
Außerdem bietet ELF nun auch eine Python-Version für die Ausführung von gleichzeitigen Spielumgebungen durch Python-Multiprocessing mit Zeromq Inter-Process Communication. Siehe ./ex_elfpy.py für ein einfaches Beispiel.
Für die Erforschung von RTS -Spielen verfügt Elf mit einem schnellen RTS -Engine und drei konkreten Umgebungen: Minirts, erfassen Sie die Flagge und die Turmverteidigung. Minirts verfügt über die wichtigste Dynamik eines Echtzeit-Strategiespiels, einschließlich des Sammelns von Ressourcen, Baueinrichtungen und -truppen, die Suche nach den unbekannten Gebieten außerhalb der wahrnehmbaren Regionen und verteidigen/greifen Sie den Feind an. Der Benutzer kann auf die interne Darstellung zugreifen und die Spieleinstellung frei ändern.
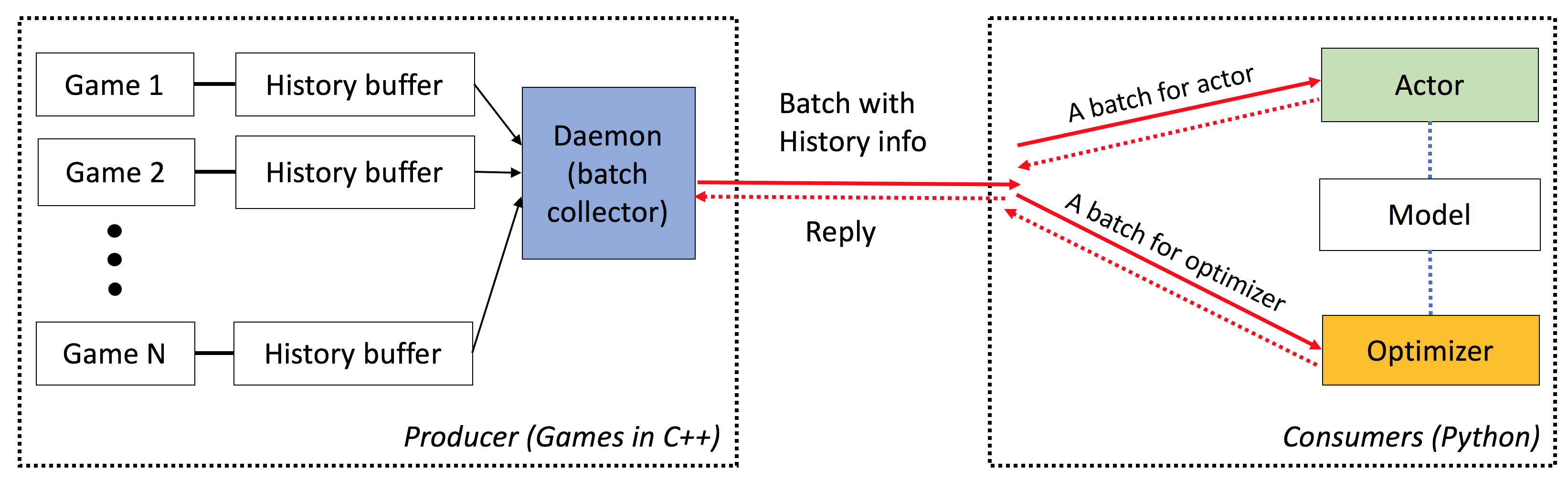
Elf hat die folgenden Eigenschaften:
End-to-End : ELF bietet eine End-to-End-Lösung für die Spieleforschung. Es bietet Miniatur-Spielumgebungen in Echtzeit-Strategie, gleichzeitige Simulation, intuitive APIs und webbasiertes VisualZation und verfügt außerdem über ein von Pytorch befähigtes Verstärkungslernen-Backend mit minimalem Ressourcenanforderungen.
Umfangreich : Jedes Spiel mit C/C ++ - Schnittstelle kann durch Schreiben eines einfachen Wrappers in dieses Framework angeschlossen werden. Zum Beispiel integrieren wir bereits Atari-Spiele in unser Framework und zeigen, dass die Simulationsgeschwindigkeit pro Kern mit einer Einzelkernversion vergleichbar ist und daher viel schneller als die Implementierung unter Verwendung von Multiprozessing- oder Python-Multithreading ist. In Zukunft planen wir, mehr Umgebungen, z. B. Darkforest Go Engine, einzubeziehen.
Leichtes Gewicht : Elf läuft sehr schnell mit minimalem Overhead. Elf mit einem einfachen Spiel (Minirts), das auf RTS Engine aufgebaut ist, fährt 40.000 Rahmen pro Sekunde pro Kern auf einem MacBook Pro. Das Training eines Modells von Grund auf neu zu spielen Minirts dauert einen Tag bei 6 CPU + 1 GPU .
Flexibel : Die Paarung zwischen Umgebungen und Akteuren ist sehr flexibel, z. B. eine Umgebung mit einem Agenten (z. B. Vanille A3C), einer Umgebung mit mehreren Agenten (z. B. Selbstspiel/MCTs) oder mehreren Umgebungen mit einem Akteur (z. B. Batcha3C, GA3C). Außerdem bietet jedes Spiel, das auf der RTS -Engine aufgebaut ist, einen vollständigen Zugriff auf seine interne Darstellung und Dynamik. Neben effizienten Simulatoren bieten wir auch einen leichten, aber leistungsstarken Verstärkungslernenrahmen. In diesem Framework können die meisten vorhandenen RL -Algorithmen hosten. In dieser Open-Source-Veröffentlichung haben wir hochmoderne Schauspieler-kritische Algorithmen bereitgestellt, die in Pytorch geschrieben wurden.
Siehe hier.
Sie müssen cmake > = 3.8, gcc > = 4,9 und tbb (Linux libtbb-dev ) haben, um dieses Skript erfolgreich zu installieren.
# Download miniconda and install.
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -O $HOME/miniconda.sh
/bin/bash $HOME/miniconda.sh -b
$HOME/miniconda3/bin/conda update -y --all python=3
# Add the following to ~/.bash_profile (if you haven't already) and source it:
export PATH=$HOME/miniconda3/bin:$PATH
# Create a new conda environment and install the necessary packages:
conda create -n elf python=3
source activate elf
# If you use cuda 8.0
# conda install pytorch cuda80 -c soumith
conda install pytorch -c soumith
pip install --upgrade pip
pip install msgpack_numpy
conda install tqdm
conda install libgcc
# Install cmake >= 3.8, gcc >= 4.9 and libtbb-dev
# This is platform-dependent.
# Clone and build the repository:
cd ~
git clone https://github.com/facebookresearch/ELF
cd ELF/rts/
mkdir build && cd build
cmake .. -DPYTHON_EXECUTABLE=$HOME/miniconda3/bin/python
make
# Train the model
cd ../..
sh ./train_minirts.sh --gpu 0
Jedes Spiel mit C/C ++ - Schnittstelle kann durch das Schreiben eines einfachen Wrappers in dieses Framework angeschlossen werden. Derzeit haben wir die folgende Umgebung:
Minirts und seine Verlängerungen ( ./rts )
Ein Miniatur-Echtzeit-Strategiespiel, das die wichtigste Dynamik seines Genres erfasst, einschließlich des Aufbaus von Arbeitnehmern, dem Sammeln von Ressourcen, der Erforschung unsichtbarer Gebiete, verteidigen den Feind und greifen sie zurück. Das Spiel läuft extrem schnell (40.000 FPS pro Kern auf einem Laptop), um die Verwendung vieler vorhandener Lernansätze für die Verstärkung der Verstärkung zu erleichtern.
Atari Games ( ./atari )
Wir integrieren die Arcade -Lernumgebung (ALE) in ELF, damit Sie jedes ROM laden und 1000 gleichzeitige Spielinstanzen problemlos ausführen können.
Go Engine ( ./go )
Wir werden unseren Darkforest Go Engine in Elf -Plattform neu implementieren. Jetzt können Sie problemlos eine Reihe von .sgf -Dateien laden und Ihre eigene GO -KI mit minimalen Ressourcenanforderungen (dh eine einzelne GPU plus pro Woche) trainieren.
Wenn Sie ELF verwenden, verweisen Sie bitte auf das Papier mit dem folgenden Bibtex -Eintrag:
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Yuandong Tian, Qucheng Gong, Wenling Shang, Yuxin Wu, C. Lawrence Zitnick
NIPS 2017
@article{tian2017elf,
title={ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games},
author={Yuandong Tian and Qucheng Gong and Wenling Shang and Yuxin Wu and C. Lawrence Zitnick},
journal={Advances in Neural Information Processing Systems (NIPS)},
year={2017}
}
Folgen in ICML -Videospielen und maschinellem Lernen (VGML) Workshop.
Demo. Top-links ist ausgebildet, während der untere Recht regelbasierte Bot ist.
Weitere Informationen finden Sie in der detaillierten Dokumentation. Sie können Ihre Version auch mit sphinx in ./doc kompilieren.
Elf ist sehr einfach zu bedienen. Die Initialisierung sieht wie folgt aus:
# We run 1024 games concurrently.
num_games = 1024
# Wait for a batch of 256 games.
batchsize = 256
# The return states contain key 's', 'r' and 'terminal'
# The reply contains key 'a' to be filled from the Python side.
# The definitions of the keys are in the wrapper of the game.
input_spec = dict ( s = '' , r = '' , terminal = '' )
reply_spec = dict ( a = '' )
context = Init ( num_games , batchsize , input_spec , reply_spec )Die Hauptschleife ist auch sehr einfach:
# Start all game threads and enter main loop.
context . Start ()
while True :
# Wait for a batch of game states to be ready
# These games will be blocked, waiting for replies.
batch = context . Wait ()
# Apply a model to the game state. The output has key 'pi'
# You can do whatever you want here. E.g., applying your favorite RL algorithms.
output = model ( batch )
# Sample from the output to get the actions of this batch.
reply [ 'a' ][:] = SampleFromDistribution ( output )
# Resume games.
context . Steps ()
# Stop all game threads.
context . Stop () Bitte prüfen Sie, ob train.py und eval.py tatsächliche Runnable -Codes.
C ++ - Compiler mit C ++ 11 -Unterstützung (z. B. GCC> = 4,9) ist erforderlich. Die folgenden Bibliotheken sind tbb erforderlich. CMake> = 3,8 ist ebenfalls erforderlich.
Python 3.x ist erforderlich. Darüber hinaus müssen Sie das folgende Paket installieren: Pytorch -Version 0.2.0+, tqdm , zmq , msgpack , msgpack_numpy
Um ein Modell für Minirts zu trainieren, kompilieren Sie bitte zuerst ./rts/game_MC (siehe Anweisung in ./rts/ mit cmake ). Beachten Sie, dass eine Zusammenstellung von ./rts/backend für das Training nicht erforderlich ist, es sei denn, Sie möchten die Visualisierung sehen.
Bitte führen Sie die folgenden Befehle im aktuellen Verzeichnis aus (Sie können auch auf train_minirts.sh verweisen):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 train.py
--num_games 1024 --batchsize 128 # Set number of games to be 1024 and batchsize to be 128.
--freq_update 50 # Update behavior policy after 50 updates of the model.
--players " fs=50,type=AI_NN,args=backup/AI_SIMPLE|delay/0.99|start/500;fs=20,type=AI_SIMPLE " # Specify AI and its opponent, separated by semicolon. `fs` is frameskip that specifies How often your opponent makes a decision (e.g., fs=20 means it acts every 20 ticks)
# If `backup` is specified in `args`, then we use rule-based AI for the first `start` ticks, then trained AI takes over. `start` decays with rate `decay`.
--tqdm # Show progress bar.
--gpu 0 # Use first gpu. If you don't specify gpu, it will run on CPUs.
--T 20 # 20 step actor-critic
--additional_labels id,last_terminal
--trainer_stats winrate # If you want to see the winrate over iterations.
# Note that the winrate is computed when the action is sampled from the multinomial distribution (not greedy policy).
# To evaluate your model more accurately, please use eval.py. Beachten Sie, dass ein langer Horizont (z. B. --T 20 ) das Training viel schneller und (gleichzeitig) stabil machen könnte. Mit langem Horizont sollten Sie in der Lage sein, ihn innerhalb von 12 Stunden mit 16 cpu und 1gpu auf 70% Winrate zu trainieren. Sie können die Anzahl der im Training verwendeten CPUs mithilfe von taskset -c steuern.
Hier ist ein ausgebildetes Modell mit 80% Winrate gegen AI_SIMPLE für Frameskip = 50. Hier ist eine Spielreplay.
Das Folgende ist eine Beispielausgabe während des Trainings:
Version: bf1304010f9609b2114a1adff4aa2eb338695b9d_staged
Num Actions: 9
Num unittype: 6
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5000/5000 [01:35<00:00, 52.37it/s]
[2017-07-12 09:04:13.212017][128] Iter[0]:
Train count: 820/5000, actor count: 4180/5000
Save to ./
Filename = ./save-820.bin
Command arguments run.py --batchsize 128 --freq_update 50 --fs_opponent 20 --latest_start 500 --latest_start_decay 0.99 --num_games 1024 --opponent_type AI_SIMPLE --tqdm
0:acc_reward[4100]: avg: -0.34079, min: -0.58232[1580], max: 0.25949[185]
0:cost[4100]: avg: 2.15912, min: 1.97886[2140], max: 2.31487[1173]
0:entropy_err[4100]: avg: -2.13493, min: -2.17945[438], max: -2.04809[1467]
0:init_reward[820]: avg: -0.34093, min: -0.56980[315], max: 0.26211[37]
0:policy_err[4100]: avg: 2.16714, min: 1.98384[1520], max: 2.31068[1176]
0:predict_reward[4100]: avg: -0.33676, min: -1.36083[1588], max: 0.39551[195]
0:reward[4100]: avg: -0.01153, min: -0.13281[1109], max: 0.04688[124]
0:rms_advantage[4100]: avg: 0.15646, min: 0.02189[800], max: 0.79827[564]
0:value_err[4100]: avg: 0.01333, min: 0.00024[800], max: 0.06569[1549]
86%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 4287/5000 [01:23<00:15, 46.97it/s]
Um ein Modell für Minirts zu bewerten, probieren Sie den folgenden Befehl aus (Sie können auch eval_minirts.sh referenzieren):
game=./rts/game_MC/game model=actor_critic model_file=./rts/game_MC/model
python3 eval.py
--load [your model]
--batchsize 128
--players " fs=50,type=AI_NN;fs=20,type=AI_SIMPLE "
--num_games 1024
--num_eval 10000
--tqdm # Nice progress bar
--gpu 0 # Use GPU 0 as the evaluation gpu.
--additional_labels id # Tell the game environment to output additional dict entries.
--greedy # Use greedy policy to evaluate your model. If not specified, then it will sample from the action distributions. Hier ist ein Beispielausgang (es dauert 1 min 40 Sekunden, um 10k -Spiele mit 12 CPUs zu bewerten):
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
Load from ./save-212808.bin
Version: dc895b8ea7df8ef7f98a1a031c3224ce878d52f0_
Num Actions: 9
Num unittype: 6
100%|████████████████████████████████████████████████████████████████████████████████████████████| 10000/10000 [01:40<00:00, 99.94it/s]
str_acc_win_rate: Accumulated win rate: 0.735 [7295/2628/9923]
best_win_rate: 0.7351607376801297
new_record: True
count: 0
str_win_rate: [0] Win rate: 0.735 [7295/2628/9923], Best win rate: 0.735 [0]
Stop all game threads ...
Probieren Sie das folgende Skript aus, wenn Sie in Minirts Selbst spielend machen möchten. Es beginnt mit zwei Bots, beide beginnend mit dem vorgebildeten Modell. Ein Bot wird im Laufe der Zeit geschult, während der andere festgehalten wird. Wenn Sie nur ihre Winrate ohne Training überprüfen möchten, versuchen Sie es --actor_only .
sh ./selfplay_minirts.sh [your pre-trained model]
Um einen trainierten Bot zu visualisieren, können Sie beim Ausführen von eval.py --save_replay_prefix [replay_file_prefix] angeben, um (viele) Wiederholungen zu speichern. Beachten Sie, dass das gleiche Flag auch auf Training/Selbstspiel angewendet werden kann.
Alle Wiederholungsdateien enthalten Aktionssequenzen, sind in .rep und sollten beim Laden genau das gleiche Spiel reproduzieren. So laden Sie die Wiederholung in der Befehlszeile unter Verwendung der folgenden:
./minirts-backend replay --load_replay [your replay] --vis_after 0 und öffnen Sie die Webseite ./rts/frontend/minirts.html um das Spiel zu überprüfen. Versuchen Sie: Wenn Sie nur schnell sehen möchten, wer das Spiel gewinnt), versuchen Sie es, nur in der Befehlszeile zu laden und auszuführen), versuchen Sie es mit:
./minirts-backend replay_cmd --load_replay [your replay]

