LLMChat
v1.1.3.4.1
欢迎来到LLMCHAT存储库,这是由Python Fastapi构建的API服务器的全栈实现,以及由Flutter提供动力的美丽前端。该项目旨在与高级ChatGPT和其他LLM型号提供无缝的聊天体验。 ?提供现代基础架构,当GPT-4的多模式和插件功能可用时,可以轻松扩展。享受您的住宿!
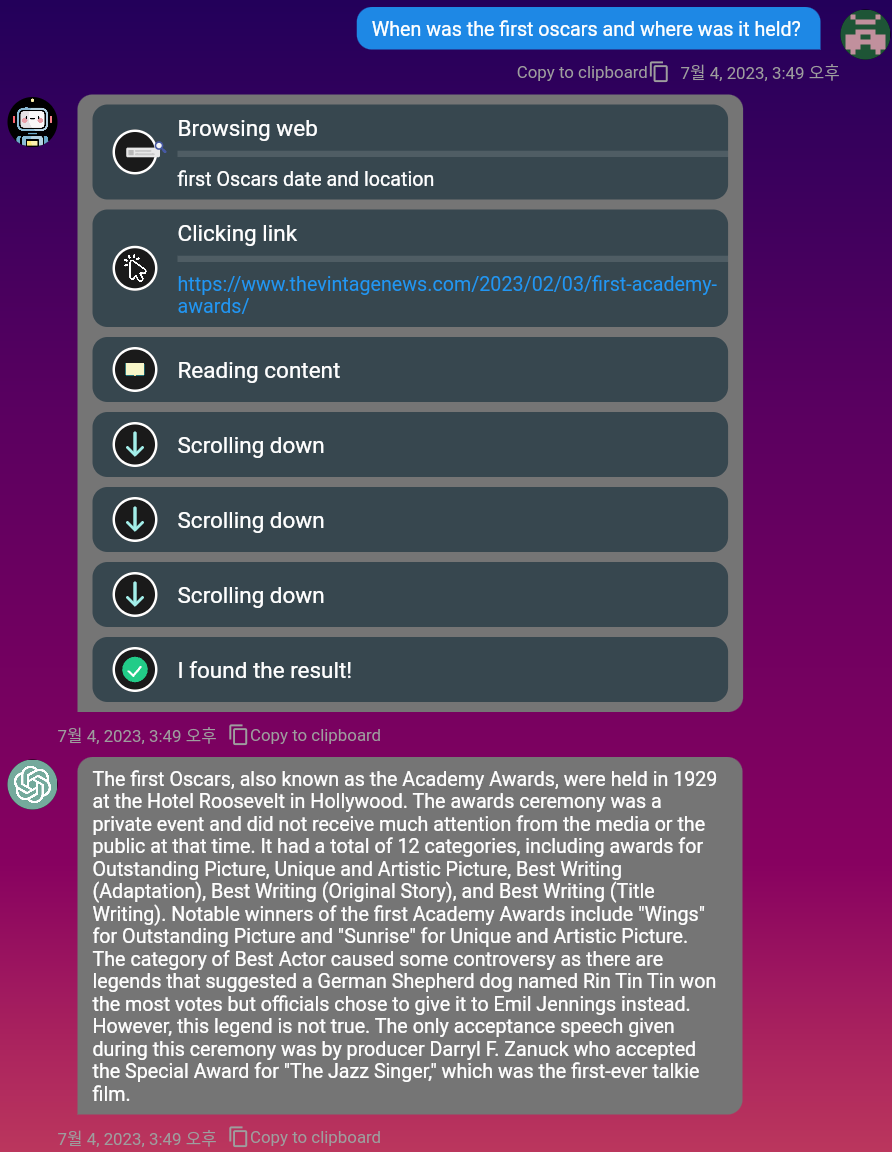
mobile环境和PC环境。Markdown ,因此您可以使用它来格式化消息。您可以使用DuckDuckgo搜索引擎在网络上找到相关信息。只需激活“浏览”切换按钮!
观看完整浏览的演示视频:https://www.youtube.com/watch?v=mj_cvrwrs08
使用/embed命令,您可以无限期地将文本存储在您自己的私人矢量数据库中,并随时以后查询。如果使用/share命令,则文本存储在每个人都可以共享的公共矢量数据库中。启用Query切换按钮或/query命令通过在公共和私人数据库中搜索文本相似性来帮助AI生成上下文化的答案。这解决了语言模型的最大局限性之一:内存。
您可以通过单击左下方的Embed Document来嵌入PDF文件。在几秒钟内,PDF的文本内容将转换为向量并嵌入到Redis Cache中。
app/models/llms.py中使用的LLMModels中使用的任何型号。 对于本地的Llalam LLM,假定它仅在本地环境中起作用,并使用http://localhost:8002/v1/completions端点。它通过连接到http://localhost:8002/health秒钟来查看是否返回200 OK响应,并且它会自动运行单独的进程以创建API服务器,从而不断地检查Llama API服务器的状态。
Llama.cpp的主要目标是使用GGML 4位量化使用普通的C/C ++实现,而无需依赖性。您必须从HuggingFace下载GGML bin文件,然后将其放入llama_models/ggml文件夹中,并在app/models/llms.py中定义LLMMODEL。很少有示例,因此您可以轻松地定义自己的模型。有关更多信息,请参阅llama.cpp存储库:https://github.com/ggerganov/llama.cpp
独立的Python/C ++/CUDA实现Llama,可与4位GPTQ权重一起使用,该重量是在现代GPU上快速且记忆效率的。它使用pytorch和sentencepiece来运行模型。假定它仅在当地环境中起作用,至少需要一个NVIDIA CUDA GPU 。您必须从HuggingFace下载Tokenizer,config和gptq文件,然后将其放入llama_models/gptq/YOUR_MODEL_FOLDER文件夹中,并在app/models/llms.py中定义llmmodel。很少有示例,因此您可以轻松地定义自己的模型。有关更多详细信息,请参阅exllama存储库:https://github.com/turboderp/exllama
web framework 。Webapp前端具有美丽的UI和丰富的可自定义小部件。OpenAI API无缝集成,用于文本生成和消息管理。LlamaCpp和Exllama模型。Real-time ,与Chatgpt的双向通信以及其他LLM型号。Redis和Langchain ,存储和检索矢量嵌入以进行相似性搜索。它将帮助AI产生更相关的响应。Duckduckgo搜索引擎,浏览网络并找到相关信息。async / await并发性和并行性的语法。MySQL查询。使用sqlalchemy.asyncio轻松执行创建,读取,更新和删除操作Redis查询。使用aioredis轻松地执行创建,读取,更新和删除操作。 要在本地计算机上设置该设置,请按照以下简单步骤操作。在开始之前,请确保您的机器上安装了docker和docker-compose 。如果您想在没有Docker的情况下运行服务器,则必须安装Python 3.11 。即使您需要Docker运行DB服务器。
要递归克隆用于使用Exllama或llama.cpp型号的子模型,请使用以下命令:
git clone --recurse-submodules https://github.com/c0sogi/llmchat.git您只想使用核心功能(OpenAI),使用以下命令:
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.env文件设置一个Env文件,参考.env-sample文件。输入数据库信息以创建,OpenAI API密钥以及其他必要的配置。不需要选择,只需将它们视为原样。
执行这些。首次启动服务器可能需要几分钟:
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml down现在,您可以通过http://localhost:8000/docs和数据库访问服务器db:3306或cache:6379 。您也可以通过http://localhost:8000/chat访问该应用程序。
要在没有Docker的情况下运行服务器,如果您想在没有Docker的情况下运行服务器,则必须安装Python 3.11 。即使您需要Docker运行DB服务器。关闭已经使用docker-compose -f docker-compose-local.yaml down api运行的API服务器。不要忘记在Docker上运行其他DB服务器!然后,运行以下命令:
python -m main现在,您的服务器应在http://localhost:8001上启动并运行。
该项目是根据MIT许可证获得许可的,该项目允许免费使用,修改和分发,只要原始版权和许可声明包含在软件的任何副本或大部分中。
FastAPI是一个现代的网络框架,用于使用Python构建API。 ?它具有高性能,易于学习,快速进行编码和准备生产。 ? FastAPI的主要特征之一是它支持并发和async / await语法。 ?这意味着您可以编写可以同时处理多个任务的代码,而不会互相阻止,尤其是在处理I/O绑定操作时,例如网络请求,数据库查询,文件操作等。
Flutter是由Google开发的开源UI工具包,用于从单个代码库中构建用于移动,Web和桌面平台的本机用户界面。 ?使用Dart ,一种现代的面向对象的编程语言,并提供了一组可自定义的小部件,可以适应任何设计。
您可以使用两个模块通过WebSocket连接访问ChatGPT或LlamaCpp : app/routers/websocket和app/utils/chat/chat_stream_manager 。这些模块通过Websocket促进了Flutter客户端和聊天模型之间的通信。使用Websocket,您可以建立一个实时的双向通信渠道与LLM互动。
要启动对话,请使用在数据库中注册的有效API密钥连接到Websocket /ws/chat/{api_key} 。请注意,此API密钥与OpenAI API密钥不同,但仅适用于服务器验证用户。连接后,您可以发送消息和命令与LLM模型进行交互。 Websocket将实时发送聊天响应。该Websocket连接是通过Flutter应用程序建立的,该应用程序可以使用端点/chat访问。
websocket.py负责设置Websocket连接和处理用户身份验证。它定义了接受Websocket和API密钥作为参数的Websocket路由/chat/{api_key} 。
当客户端连接到Websocket时,它首先检查API键以对用户进行身份验证。如果API键有效,则从stream_manager.py模块调用begin_chat()函数以启动对话。
如果有未注册的API密钥或出乎意料的错误,则将适当的消息发送给客户端并关闭连接。
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.py负责管理对话和处理用户消息。它定义了begin_chat()函数,该函数将websocket,一个用户ID作为参数。
该功能首先从CACHE MARAFER初始化用户的聊天上下文。然后,它通过Websocket将初始消息历史记录发送给客户端。
对话继续循环,直到连接关闭。在对话期间,处理用户的消息,并相应地生成GPT的响应。
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
... SendToWebsocket类用于将消息和流发送到Websocket。它有两种方法: message()和stream() 。 message()方法将完整的消息发送到Websocket,而stream()方法将流发送到Websocket。
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
...MessageHandler类还处理AI响应。 ai()方法将AI响应发送到Websocket。如果启用了翻译,则在将其发送给客户端之前,请使用Google Translate API进行翻译。
class MessageHandler :
...
@ staticmethod
async def ai (...):
...用户消息是使用HandleMessage类处理的。如果消息以/为开头,例如/YOUR_CALLBACK_NAME 。它被视为命令,并生成适当的命令响应。否则,将处理用户的消息并将其发送到LLM模型以生成响应。
使用ChatCommands类处理命令。它根据命令执行相应的回调函数。您可以通过在app.utils.chat.chat_commands中的ChatCommands类中添加回调来添加新命令。
使用redis存储对话的矢量嵌入吗?…可以帮助chatgpt模型吗?通过几种方式,例如对对话上下文的高效且快速检索♀️,处理大量数据,并通过向量相似性搜索提供更相关的响应?
一些有趣的例子在实践中如何起作用:
/embed命令嵌入文本当用户在聊天窗口中输入命令(例如/embed <text_to_embed>时,调用了VectorStoreManager.create_documents方法。此方法使用OpenAI的text-embedding-ada-002型号将输入文本转换为向量,并将其存储在Redis VectorStore中。
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../query命令查询嵌入式数据当用户输入/query <query>命令时, asimilarity_search函数将用于查找与Redis VectorStore中嵌入式数据相似性最高的三个结果。这些结果暂时存储在聊天的上下文中,这可以通过参考这些数据来回答查询。
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
...在运行begin_chat函数时,如果用户上传包含文本的文件(例如,pdf或txt文件),则将自动从文件中提取文本,并将其向量嵌入将其保存到redis中。
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py功能在commands.py文件中,有几个重要组件:
command_response :此类用于在命令方法上设置装饰器,以指定下一个操作。它有助于定义各种响应类型,例如发送消息并停止,发送消息以及继续,处理用户输入,处理AI响应等等。command_handler :此功能负责基于用户输入的文本执行命令回调方法。arguments_provider :此功能会根据命令方法的注释类型自动提供命令方法所需的参数。任务触发:每当用户键入消息或AI响应消息时,就会激活此功能。此时,生成了自动摘要任务以凝结文本内容。
任务存储:然后将自动 - 夏线任务存储在BufferUserChatContext的task_list属性中。这是管理链接到用户聊天上下文的任务的队列。
任务收集:在MessageHandler完成用户问题和答案周期之后,调用了harvest_done_tasks功能。此功能收集了摘要任务的结果,确保没有遗漏。
摘要申请:收获过程后,汇总结果替换了我们的聊天机器人从语言学习模型(LLMS)(例如OpenAI和LLAMA_CPP)的答案时,替换了实际消息。通过这样做,我们可以发送比最初的冗长消息更多的简洁提示。
用户体验:重要的是,从用户的角度来看,他们只看到原始消息。该消息的摘要版本未显示给他们,保持透明度并避免潜在的混乱。
同时任务:此自动签到任务的另一个关键功能是它不会阻碍其他任务。换句话说,虽然聊天机器人忙于总结文本,但仍可以执行其他任务,从而提高我们的聊天机器人的整体效率。
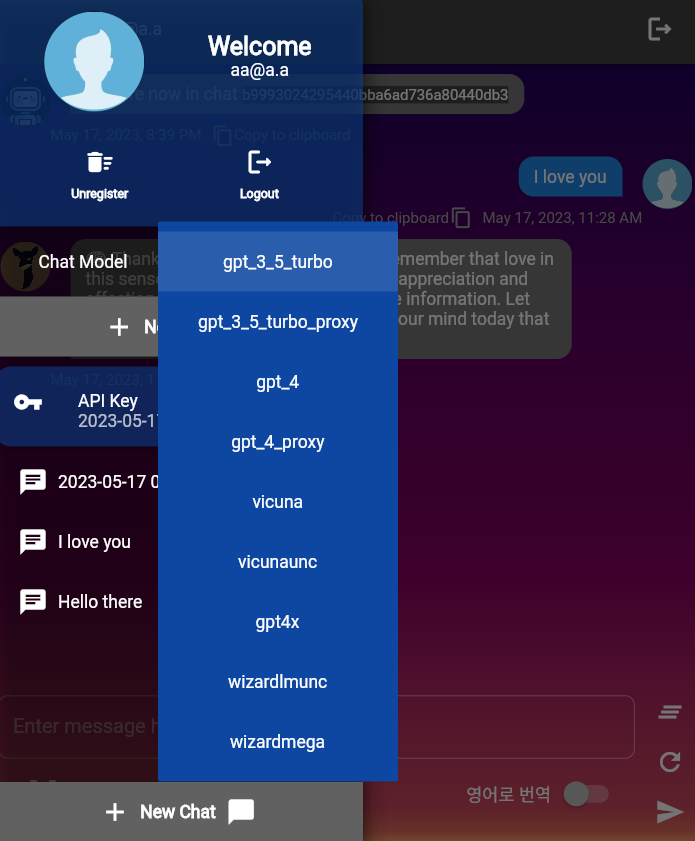
ChatConfig中设置了阈值。该存储库包含不同的LLM模型,该模型在llms.py中定义。每个LLM模型类都从基类LLMModel继承。 LLMModels枚举是这些LLM的集合。
所有操作均异步处理,而不会使主螺纹交织。但是,本地LLM无法同时处理多个请求,因为它们在计算上太昂贵。因此,使用Semaphore将请求数限制为1。
用户通过UserChatContext.construct_default使用的默认LLM模型为gpt-3.5-turbo 。您可以更改该功能的默认值。
OpenAIModel通过请求OpenAI服务器的聊天完成来使文本异步生成。它需要一个OpenAI API键。
LlamaCppModel读取本地存储的GGML模型。 Llama.cpp GGML模型必须以.bin文件为单位的llama_models/ggml文件夹中。例如,如果您从“ https://huggingface.co/thebloke/robin-7b-v2-ggml”下载了Q4_0量化的模型,则该模型的路径必须为“ Robin-7b.ggmlv3.q4_0.bin”。
ExllamaModel读取本地存储的GPTQ模型。 Exllama GPTQ模型必须以文件夹的形式放置在llama_models/gptq文件夹中。例如,如果您从“ https://huggingface.co/thebloke/orca_mini_7b-gptq/tree/main/main”下载了3个文件:
然后,您需要将它们放入文件夹中。模型的路径必须是文件夹名称。假设包含3个文件的“ orca_mini_7b”。
处理文本生成期间可能发生的例外。如果抛出了ChatLengthException ,它将自动执行一个例程,以将消息重新限制为cutoff_message_histories函数限制令牌内的消息,并将其重新发送。这可以确保用户具有平稳的聊天体验,而不管令牌限制如何。
该项目旨在创建API后端,以启用大型语言模型聊天机器人服务。它利用缓存管理器将消息和用户配置文件存储在REDIS中,以及消息管理器安全缓存消息,以使令牌数不超过可接受的限制。
缓存管理器( CacheManager )负责处理用户上下文信息和消息历史记录。它将这些数据存储在REDIS中,从而可以轻松检索和修改。经理提供了几种与缓存交互的方法,例如:
read_context_from_profile :根据用户的配置文件,从Redis读取用户的聊天上下文。create_context :在Redis中创建一个新的用户聊天上下文。reset_context :将用户的聊天上下文重置为默认值。update_message_histories :更新特定角色(用户,AI或系统)的消息历史记录。lpop_message_history / rpop_message_history :从列表的左侧或右端删除并返回消息历史记录。append_message_history :将消息历史记录附加到列表的末尾。get_message_history :检索特定角色的消息历史记录。delete_message_history :删除特定角色的消息历史记录。set_message_history :为角色和索引设置特定的消息历史记录。 消息管理器( MessageManager )确保消息历史记录中的令牌数不超过指定的限制。它可以安全地处理在用户的聊天上下文中添加,删除和设置消息历史,同时保持令牌限制。经理提供了几种与消息历史互动的方法,例如:
add_message_history_safely :将消息历史记录添加到用户的聊天上下文中,以确保不超过令牌限制。pop_message_history_safely :在更新令牌计数时从列表的右端删除并返回消息历史记录。set_message_history_safely :在用户聊天上下文中设置特定消息历史记录,更新令牌计数并确保不超过令牌限制。 要在您的项目中使用缓存管理器和消息管理器,请按以下方式导入它们:
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManager然后,您可以使用他们的方法与REDIS缓存进行交互,并根据您的要求管理消息历史记录。
例如,创建一个新的用户聊天上下文:
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )安全地将消息历史记录添加到用户的聊天上下文中:
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role )该项目使用token_validator中间件和FastAPI应用程序中使用的其他中间件。这些中间Wares负责控制对API的访问,确保仅处理授权和身份验证的请求。
以下中间件添加到FastAPI应用程序中:
访问控制中间软件是在token_validator.py文件中定义的。它负责验证API键和JWT令牌。
StateManager类用于初始化请求状态变量。它设置请求时间,开始时间,IP地址和用户令牌。
AccessControl类包含两个用于验证API键和JWT令牌的静态方法:
api_service :通过检查请求中所需的查询参数和标头的存在来验证API键。它调用Validator.api_key方法来验证API密钥,秘密和时间戳。non_api_service :通过在请求中检查“授权”标头或“授权” cookie的存在来验证JWT令牌。它调用Validator.jwt方法来解码和验证JWT令牌。 Validator类包含两个用于验证API密钥和JWT令牌的静态方法:
api_key :验证API访问密钥,Hashed Secret和时间戳。如果验证成功,则返回UserToken对象。jwt :解码和验证JWT令牌。如果验证成功,则返回UserToken对象。 access_control函数是一个异步函数,可处理中间件的请求和响应流。它使用StateManager类初始化了请求状态,确定请求URL(API键或JWT令牌)所需的身份验证类型,并使用AccessControl类验证身份验证。如果在验证过程中发生错误,则会提出适当的HTTP异常。
令牌实用程序在token.py文件中定义。它包含两个功能:
create_access_token :使用给定的数据和到期时间创建JWT令牌。token_decode :解码和验证JWT令牌。如果令牌已过期或无法解码,则会引起例外。params_utils.py文件包含使用HMAC和SHA256的哈希查询参数和秘密密钥的实用程序函数:
hash_params :以查询参数和秘密键为输入,并返回基本64编码的哈希德字符串。date_utils.py文件包含带有实用程序功能的UTC类,用于使用日期和时间戳:
now :以可选的小时差返回当前的UTC DateTime。timestamp :以可选的小时差返回当前的UTC时间戳。timestamp_to_datetime :将时间戳转换为具有可选小时差的DateTime对象。logger.py文件包含ApiLogger类,该类可记录API请求和响应信息,包括请求URL,方法,状态代码,客户端信息,处理时间和错误详细信息(如果适用)。在access_control函数的末尾调用记录器函数以记录已处理的请求和响应。
要在您的FastAPI应用程序中使用token_validator中间件,只需导入access_control函数,然后将其添加为中间件:
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )确保还添加CORS和受信任的主机中间Wares以进行完整的访问控制:
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
)现在, token_validator中间件和其他中间件将处理对您的FastAPI应用程序的任何传入请求,以确保仅处理授权和认证的请求。
此模块app.database.connection提供了一个易于使用的接口,用于使用SQLalchemy和Redis来管理数据库连接和执行SQL查询。它支持MySQL,并且可以轻松地与该项目集成。
首先,从模块导入所需类:
from app . database . connection import MySQL , SQLAlchemy , CacheFactory接下来,创建一个SQLAlchemy类的实例,并使用您的数据库设置进行配置:
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config )现在,您可以使用db实例执行SQL查询并管理会话:
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" )要使用redis缓存,请创建一个CacheFactory类的实例,然后使用您的redis设置进行配置:
cache = CacheFactory ()
cache . start ( config )您现在可以使用cache实例与Redis交互:
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" )实际上,在此项目中, MySQL类在应用程序启动时进行初始设置,并且所有数据库连接仅使用模块末尾的db和cache变量进行。 ?
所有DB设置将在app.common.app_settings中的create_app()中完成。例如, app.common.app_settings中的create_app()函数看起来像这样:
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_app该项目使用简单有效的方法来处理使用SQLalchemy和两个模块和路径的数据库CRUD(创建,读取,更新,删除)操作: app.database.models.schema和app.database.crud 。
schema.py模块负责使用SQLalchemy定义数据库模型及其关系。它包括一组从Base继承的类,该类别是declarative_base()的实例。每个类代表数据库中的表,其属性表示表中的列。这些类还从Mixin类中继承,该类提供了所有模型的一些常见方法和属性。
Mixin类为所有从中继承的类提供了一些常见的属性和方法。一些属性包括:
id :表的整数主键。created_at :dateTime创建记录的时间。updated_at :记录最后更新何时的日期时间。ip_address :创建或更新记录的客户端的IP地址。它还提供了多种使用SQLalchemy进行CRUD操作的类方法,例如:
add_all() :将多个记录添加到数据库中。add_one() :将单个记录添加到数据库中。update_where() :基于过滤器中数据库中的记录。fetchall_filtered_by() :从数据库中获取与提供过滤器相匹配的所有记录。one_filtered_by() :从数据库中获取与所提供过滤器匹配的单个记录。first_filtered_by() :从与提供过滤器匹配的数据库中获取第一个记录。one_or_none_filtered_by() :获取单个记录或如果没有记录匹配所提供的过滤器,则返回None 。 users.py和api_keys.py模块包含一组功能,使用schema.py中定义的类执行CRUD操作。这些功能使用Mixin类提供的类方法与数据库进行交互。
该模块中的某些功能包括:
create_api_key() :为用户创建一个新的API密钥。get_api_keys() :检索用户的所有API键。get_api_key_owner() :检索API密钥的所有者。get_api_key_and_owner() :检索API键及其所有者。update_api_key() :更新API密钥。delete_api_key() :删除API键。is_email_exist() :检查数据库中是否存在电子邮件。get_me() :根据用户ID检索用户信息。is_valid_api_key() :检查API键是否有效。register_new_user() :在数据库中注册新用户。find_matched_user() :在数据库中找到带有匹配电子邮件的用户。 要使用提供的CRUD操作,请从crud.py模块中导入相关功能,并使用所需的参数调用它们。例如:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())