LLMChat
v1.1.3.4.1
Willkommen im LLMchat-Repository, einer vollständigen Implementierung eines API-Servers mit Python Fastapi und einem wunderschönen Frontend, der von Flattern angetrieben wird. Dieses Projekt soll ein nahtloses Chat -Erlebnis mit den erweiterten Chatgpt- und anderen LLM -Modellen bieten. ? Bieten einer modernen Infrastruktur, die leicht erweitert werden kann, wenn die multimodalen und Plugin-Funktionen von GPT-4 verfügbar sind. Genieße deinen Aufenthalt!
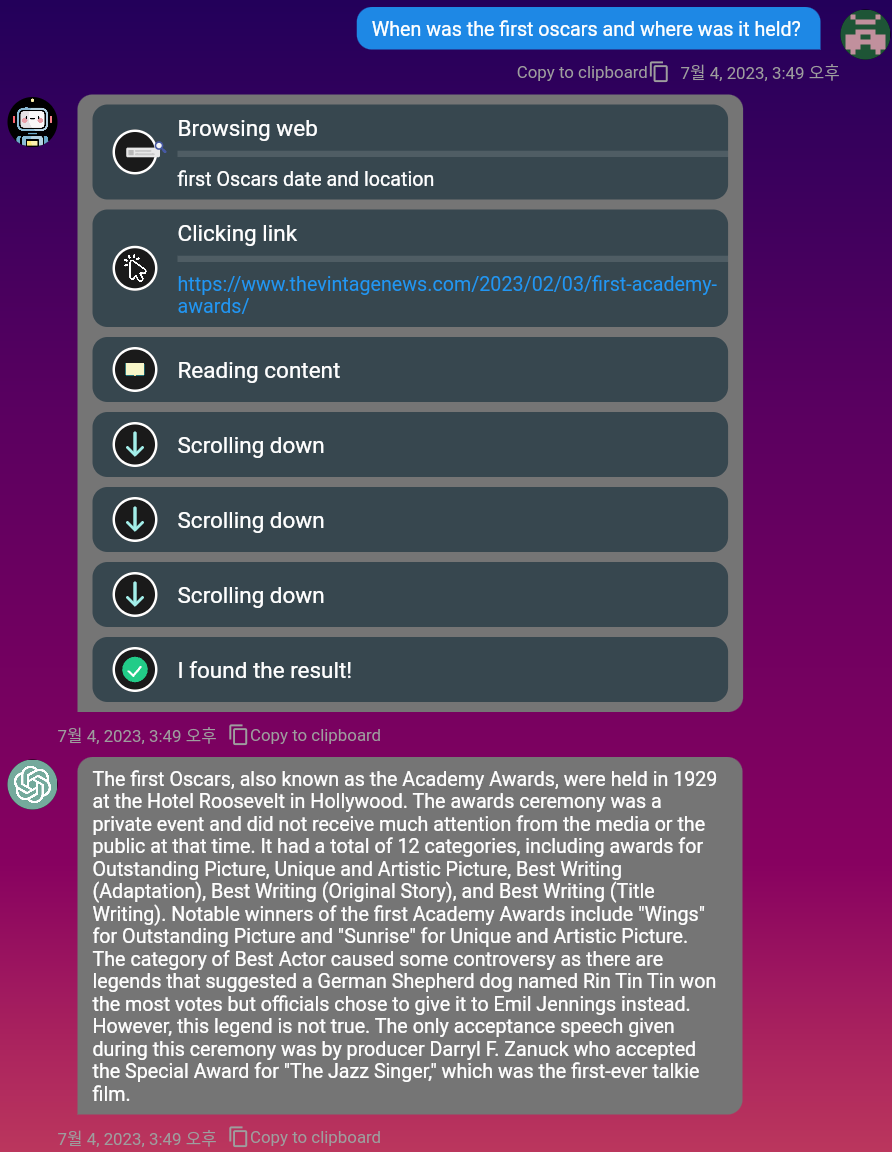
mobile als auch PC -Umgebungen.Markdown wird ebenfalls unterstützt, sodass Sie damit Ihre Nachrichten formatieren können.Sie können die DuckDuckgo -Suchmaschine verwenden, um relevante Informationen im Web zu finden. Aktivieren Sie einfach die Schaltfläche "Durchsuchen"!
Sehen Sie sich das Demo-Video für vollständige Browsing an: https://www.youtube.com/watch?v=mj_cvrwrs08
Mit dem Befehl /embed können Sie den Text auf unbestimmte Zeit in Ihrer eigenen privaten Vektordatenbank speichern und später und jederzeit abfragen. Wenn Sie den Befehl /share verwenden, wird der Text in einer öffentlichen Vektor -Datenbank gespeichert, die jeder teilen kann. Aktivieren Sie die Schaltfläche Query Abfragen" oder /query -Befehl" hilft der KI, kontextualisierte Antworten zu generieren, indem nach Textähnlichkeiten in öffentlichen und privaten Datenbanken gesucht wird. Dies löst eine der größten Einschränkungen von Sprachmodellen: Gedächtnis .
Sie können die PDF -Datei einbetten, indem Sie unten links auf Embed Document klicken. In wenigen Sekunden wird der Textinhalt von PDF in Vektoren umgewandelt und in Redis -Cache eingebettet.
LLMModels verwenden möchten, das sich in app/models/llms.py befindet. Für das lokale LLALAM LLMS wird angenommen, dass es nur in der lokalen Umgebung funktioniert und den Endpunkt http://localhost:8002/v1/completions verwendet. Es überprüft kontinuierlich den Status des LLAMA -API -Servers, indem Sie eine Verbindung zu http://localhost:8002/health herstellen, einmal eine Sekunde, um festzustellen, ob eine 200 -OK -Antwort zurückgegeben wird. Wenn nicht, wird automatisch einen separaten Vorgang ausgeführt, um einen API -Server zu erstellen.
Das Hauptziel von LLAMA.CPP ist es, das Lama-Modell mit GGML 4-Bit-Quantisierung mit einfacher C/C ++-Implementierung ohne Abhängigkeiten zu betreiben. Sie müssen die GGML bin -Datei von Huggingface herunterladen und in den Ordner llama_models/ggml einfügen und Llmmodel in app/models/llms.py definieren. Es gibt nur wenige Beispiele, sodass Sie Ihr eigenes Modell leicht definieren können. Weitere Informationen finden Sie im Repository llama.cpp : https://github.com/ggerganov/llama.cpp
Eine eigenständige Python/C ++/CUDA-Implementierung von Lama zur Verwendung mit 4-Bit- GPTQ Gewichten, die für die moderne GPUs schnell und speicherend ausgestattet sind. Es verwendet pytorch und sentencepiece um das Modell auszuführen. Es wird angenommen, dass es nur in der lokalen Umgebung funktioniert und mindestens eine NVIDIA CUDA GPU erforderlich ist. Sie müssen Tokenizer-, Konfigurations- und GPTQ -Dateien von Huggingface herunterladen und in den Ordner llama_models/gptq/YOUR_MODEL_FOLDER einfügen und Llmmodel in app/models/llms.py definieren. Es gibt nur wenige Beispiele, sodass Sie Ihr eigenes Modell leicht definieren können. Weitere Informationen finden Sie im exllama -Repository: https://github.com/turboderp/exllama
web framework zum Aufbau von APIs mit Python.Webapp Frontend mit wunderschöner Benutzeroberfläche und reichhaltiger anpassbarer Widgets.OpenAI API für Textgenerierung und Nachrichtenverwaltung.LlamaCpp und Exllama -Modelle.Real-time , Zwei-Wege-Kommunikation mit dem ChatGPT und anderen LLM-Modellen mit Flutter Frontend WebApp.Redis und Langchain , speichern und abrufen Vektor -Einbettungen für die Ähnlichkeitssuche. Es wird KI helfen, relevantere Antworten zu generieren.Duckduckgo Suchmaschine, durchsuchen Sie das Web und finden Sie relevante Informationen.async / await Syntax für Parallelität und Parallelität.MySQL -Abfragen ausführen. Mit sqlalchemy.asyncio problemlos Erstellen, Lesen, Aktionen und Löschen von Aktionen durchführenRedis -Abfragen mit Aioredis ausführen. Mit aioredis einfach Erstellen, Lesen, Aktualisieren und Löschen von Aktionen durchführen. Befolgen Sie diese einfachen Schritte, um die auf Ihrer lokalen Maschine eingerichtete Maschine einzurichten. Stellen Sie vor Beginn sicher, dass Sie docker und docker-compose auf Ihrem Computer installiert haben. Wenn Sie den Server ohne Docker ausführen möchten, müssen Sie Python 3.11 zusätzlich installieren. Obwohl Sie Docker brauchen, um DB -Server auszuführen.
Verwenden Sie den folgenden Befehl, um die Submodule für die Verwendung Exllama oder llama.cpp -Modellen rekursiv zu klonen:
git clone --recurse-submodules https://github.com/c0sogi/llmchat.gitSie möchten nur Kernfunktionen (OpenAI) verwenden, den folgenden Befehl verwenden:
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.env -Datei Richten Sie eine Env-Datei ein und beziehen sich auf die Datei .env-sample . Geben Sie Datenbankinformationen ein, um den API -Schlüssel und andere erforderliche Konfigurationen zu erstellen, zu öffnen. Optionen sind nicht erforderlich, lassen Sie sie einfach so, wie sie sind.
Diese ausführen. Es kann einige Minuten dauern, bis der Server zum ersten Mal startet:
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml down Jetzt können Sie auf den Server unter http://localhost:8000/docs und die Datenbank unter db:3306 oder cache:6379 zugreifen. Sie können auch auf die App unter http://localhost:8000/chat zugreifen.
Um den Server ohne Docker auszuführen, wenn Sie den Server ohne Docker ausführen möchten, müssen Sie Python 3.11 zusätzlich installieren. Obwohl Sie Docker brauchen, um DB -Server auszuführen. Schalten Sie den API-Server aus, der bereits mit docker-compose -f docker-compose-local.yaml down api ausgeführt wird. Vergessen Sie nicht, andere DB -Server auf Docker zu betreiben! Führen Sie dann die folgenden Befehle aus:
python -m main Ihr Server sollte jetzt in http://localhost:8001 in diesem Fall ausgeführt werden.
Dieses Projekt ist unter der MIT -Lizenz lizenziert, die eine kostenlose Verwendung, Änderung und Verteilung ermöglicht, solange das ursprüngliche Urheberrecht und die Lizenzbenachrichtigung in einer Kopie oder einem wesentlichen Teil der Software enthalten sind.
FastAPI ist ein modernes Web -Framework zum Aufbau von APIs mit Python. ? Es hat eine hohe Leistung, leicht zu lernen, schnell zu codieren und produziert bereit zu sein. ? Eines der Hauptmerkmale von FastAPI ist, dass es Gleichzeitigkeit unterstützt und die Syntax async / await . ? Dies bedeutet, dass Sie Code schreiben können, mit dem mehrere Aufgaben gleichzeitig erledigt werden können, ohne sich gegenseitig zu blockieren, insbesondere wenn Sie mit E/A -gebundenen Vorgängen wie Netzwerkanforderungen, Datenbankabfragen, Dateioperationen usw. erledigen.
Flutter ist ein Open-Source-UI-Toolkit, das von Google entwickelt wurde, um native Benutzeroberflächen für mobile, Web- und Desktop-Plattformen aus einer einzigen Codebasis zu erstellen. Es verwendet Dart , eine moderne, objektorientierte Programmiersprache, und bietet eine Reihe anpassbarer Widgets, die sich an jedes Design anpassen können.
Sie können über zwei Module über WebSocket -Verbindung ChatGPT oder LlamaCpp zugreifen: app/routers/websocket und app/utils/chat/chat_stream_manager . Diese Module erleichtern die Kommunikation zwischen dem Flutter -Client und dem Chat -Modell über ein WebSocket. Mit dem WebSocket können Sie einen Echtzeit-Zwei-Wege-Kommunikationskanal einrichten, um mit dem LLM zu interagieren.
Um eine Konversation zu starten, stellen Sie eine Verbindung zur WebSocket -Route /ws/chat/{api_key} mit einer gültigen API -Taste in der Datenbank her. Beachten Sie, dass diese API -Taste nicht mit der OpenAI -API -Taste entspricht, sondern nur für Ihren Server verfügbar ist, um den Benutzer zu validieren. Sobald Sie verbunden sind, können Sie Nachrichten und Befehle senden, um mit dem LLM -Modell zu interagieren. Das WebSocket sendet in Echtzeit die Reaktionen der Chat zurück. Diese WebSocket -Verbindung wird über die Flutter -App hergestellt, auf die Endpunkt /chat zugegriffen werden kann.
websocket.py ist für die Einrichtung einer WebSocket -Verbindung und zur Bearbeitung der Benutzerauthentifizierung verantwortlich. Es definiert die WebSocket -Route /chat/{api_key} , die ein WebSocket und eine API -Schlüssel als Parameter akzeptiert.
Wenn ein Client eine Verbindung zum WebSocket herstellt, überprüft er zunächst den API -Schlüssel, um den Benutzer zu authentifizieren. Wenn die API -Taste gültig ist, wird die Funktion " begin_chat() aus dem Modul stream_manager.py aufgerufen, um die Konversation zu starten.
Im Falle eines nicht registrierten API -Schlüssels oder eines unerwarteten Fehlers wird eine geeignete Nachricht an den Client gesendet und die Verbindung geschlossen.
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.py ist für die Verwaltung der Konversation und den Umgang mit Benutzernachrichten verantwortlich. Es definiert die Funktion " begin_chat() , die eine Websocket, eine Benutzer -ID als Parameter, aufnimmt.
Die Funktion initialisiert zunächst den Chat -Kontext des Benutzers aus dem Cache -Manager. Anschließend sendet es den anfänglichen Nachrichtenverlauf über das WebSocket an den Client.
Das Gespräch wird in einer Schleife fortgesetzt, bis die Verbindung geschlossen ist. Während der Konversation werden die Nachrichten des Benutzers verarbeitet und die Antworten von GPT entsprechend generiert.
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
... Die SendToWebsocket -Klasse wird zum Senden von Nachrichten und Streams an das WebSocket verwendet. Es hat zwei Methoden: message() und stream() . Die message() -Methode sendet eine vollständige Nachricht an das WebSocket, während die stream() -Methode einen Stream an das WebSocket sendet.
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
... Die MessageHandler -Klasse übernimmt auch KI -Antworten. Die ai() -Methode sendet die AI -Antwort an das Websocket. Wenn die Übersetzung aktiviert ist, wird die Antwort mit der Google Translate API übersetzt, bevor sie an den Client gesendet wird.
class MessageHandler :
...
@ staticmethod
async def ai (...):
... Benutzernachrichten werden mit der HandleMessage -Klasse verarbeitet. Wenn die Nachricht mit / wie /YOUR_CALLBACK_NAME beginnt. Es wird als Befehl behandelt und die entsprechende Befehlsantwort wird generiert. Andernfalls wird die Nachricht des Benutzers verarbeitet und an das LLM -Modell zur Generierung einer Antwort gesendet.
Befehle werden mit der ChatCommands -Klasse behandelt. Es wird die entsprechende Rückruffunktion abhängig vom Befehl ausgeführt. Sie können neue Befehle hinzufügen, indem Sie einfach in der ChatCommands -Klasse von app.utils.chat.chat_commands zurückgezogen werden.
Verwenden von Redis zum Speichern von Vektor -Einbettungen von Gesprächen? ️ Kann das ChatGPT -Modell helfen? In mehrfacher Hinsicht, wie z. B. effizientes und schnelles Abrufen des Konversationskontexts ♀️, die Umgang mit großen Datenmengen und die Bereitstellung von relevanteren Antworten durch Vektorähnlichkeitssuche?
Einige lustige Beispiele dafür, wie dies in der Praxis funktionieren könnte:
/embed Wenn ein Benutzer einen Befehl in das Chat -Fenster wie /embed <text_to_embed> eingibt, wird die VectorStoreManager.create_documents -Methode aufgerufen. Diese Methode wandelt den Eingabetxt mithilfe von OpenAIs text-embedding-ada-002 -Modell in einen Vektor um und speichert es im Redis-Vectorstore.
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../query Wenn der Benutzer in den Befehl /query <query> eingibt, wird die Funktion asimilarity_search verwendet, um bis zu drei Ergebnisse mit der höchsten Vektor -Ähnlichkeit mit den eingebetteten Daten im Redis -Vectorstore zu finden. Diese Ergebnisse werden im Kontext des Chats vorübergehend gespeichert, was der KI hilft, die Abfrage zu beantworten, indem sie sich auf diese Daten beziehen.
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
... Wenn ein Benutzer eine Datei mit Text mit Text (z. B. eine PDF- oder TXT -Datei) begin_chat , wird der Text automatisch aus der Datei extrahiert und der Vektoreinbettung wird in Redis gespeichert.
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py Funktionalität In der Datei commands.py gibt es mehrere wichtige Komponenten:
command_response : Diese Klasse wird verwendet, um einen Dekorateur für die Befehlsmethode festzulegen, um die nächste Aktion anzugeben. Es hilft, verschiedene Antworttypen zu definieren, z. B. das Senden einer Nachricht und das Stoppen, das Senden einer Nachricht und das Fortsetzung, den Umgang mit Benutzereingaben, die Bearbeitung von AI -Antworten und vieles mehr.command_handler : Diese Funktion ist für die Durchführung einer Befehls -Rückrufmethode basierend auf dem vom Benutzer eingegebenen Text verantwortlich.arguments_provider : Diese Funktion liefert automatisch die Argumente, die von der Befehlsmethode basierend auf dem Annotationstyp der Befehlsmethode erforderlich sind.Aufgabenauslöser : Diese Funktion wird aktiviert, wenn ein Benutzer eine Nachricht eingibt oder die KI mit einer Nachricht antwortet. Zu diesem Zeitpunkt wird eine automatische Summaraufgabe generiert, um den Textinhalt zu verdichten.
Aufgabenspeicher : Die automatische Summarisierungsaufgabe wird dann im Attribut task_list des BufferUserChatContext gespeichert. Dies dient als Warteschlange für die Verwaltung von Aufgaben, die mit dem Chat -Kontext des Benutzers verknüpft sind.
Aufgabenernte : Nach Abschluss eines Benutzer-AI-Frage- und Antwortzyklus durch den MessageHandler wird die Funktion harvest_done_tasks aufgerufen. Diese Funktion sammelt die Ergebnisse der Summarierungsaufgabe und stellt sicher, dass nichts ausgelassen wird.
Zusammenfassung der Anwendung : Nach dem Ernteprozess ersetzen die zusammengefassten Ergebnisse die tatsächliche Nachricht, wenn unser Chatbot Antworten aus Sprachlernmodellen (LLMs) wie OpenAI und LLAMA_CPP anfordert. Auf diese Weise können wir viel prägnante Eingabeaufforderungen senden als die anfängliche langwierige Nachricht.
Benutzererfahrung : Wichtig ist aus Sicht des Benutzers nur die ursprüngliche Nachricht. Die zusammengefasste Version der Nachricht wird ihnen nicht angezeigt, wobei die Transparenz beibehält und potenzielle Verwirrung vermieden wird.
Gleichzeitige Aufgaben : Ein weiteres wichtiges Merkmal dieser automatischen Summarisierungsaufgabe ist, dass sie andere Aufgaben nicht behindert. Mit anderen Worten, während der Chatbot damit beschäftigt ist, den Text zusammenzufassen, können noch andere Aufgaben ausgeführt werden, wodurch die Gesamteffizienz unseres Chatbots verbessert wird.
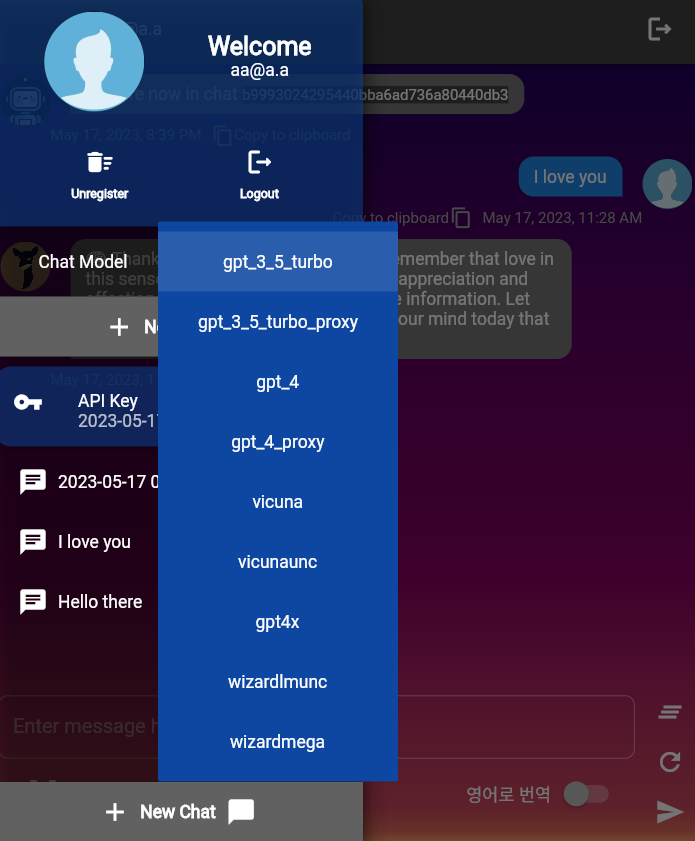
ChatConfig eingeschaltet werden. Dieses Repository enthält verschiedene LLM -Modelle, die in llms.py definiert sind. Jede LLM -Modellklasse erben aus der Basisklasse LLMModel . Die LLMModels Enum ist eine Sammlung dieser LLMs.
Alle Operationen werden asynchron behandelt, ohne den Hauptfaden zu unterbrechen. Lokale LLMs können jedoch nicht gleichzeitig mehrere Anforderungen bearbeiten, da sie zu rechenintensiv sind. Daher wird ein Semaphore verwendet, um die Anzahl der Anforderungen auf 1 zu beschränken.
Das vom Benutzer verwendete Standard-LLM-Modell über UserChatContext.construct_default ist gpt-3.5-turbo . Sie können die Standardeinstellung für diese Funktion ändern.
OpenAIModel generiert asynchron Text, indem er vom OpenAI -Server eine Chat -Fertigstellung beantragt. Es erfordert einen OpenAI -API -Schlüssel.
LlamaCppModel liest ein lokal gespeichertes GGML -Modell. Das LLAMA.CPP -GGML -Modell muss in den Ordner llama_models/ggml als .bin -Datei eingesetzt werden. Wenn Sie beispielsweise ein quantisiertes Modell von Q4_0 von "https://huggingface.co/theBloke/robin-7b-v2-gml" heruntergeladen haben, muss der Pfad des Modells "Robin-7b.ggmlv3.q4_0.bin" sein.
ExllamaModel las ein lokal gespeichertes GPTQ -Modell. Das Exllama GPTQ -Modell muss in den Ordner llama_models/gptq als Ordner eingesetzt werden. Wenn Sie beispielsweise 3 Dateien von "https://huggingface.co/theBloke/orca_mini_7b-Gptq/tree/main" heruntergeladen haben:
Dann müssen Sie sie in einen Ordner legen. Der Pfad des Modells muss der Ordnername sein. Sagen wir "orca_mini_7b", die die 3 Dateien enthält.
Behandeln Sie Ausnahmen, die während der Textgenerierung auftreten können. Wenn eine ChatLengthException geworfen wird, führt sie automatisch eine Routine durch, um die Nachricht innerhalb der Anzahl der mit der Funktion cutoff_message_histories begrenzten Token zu belasten und neu zu senden. Dies stellt sicher, dass der Benutzer unabhängig von der Token -Grenze über ein reibungsloses Chat -Erlebnis verfügt.
Dieses Projekt zielt darauf ab, ein API -Backend zu erstellen, um den Chatbot -Dienst des großen Sprachmodells zu ermöglichen. Es verwendet einen Cache -Manager, um Nachrichten und Benutzerprofile in Redis zu speichern, sowie einen Message Manager, um Nachrichten sicher zu richten, sodass die Anzahl der Token ein akzeptables Grenzwert nicht überschreitet.
Der Cache -Manager ( CacheManager ) ist verantwortlich für den Umgang mit Benutzerkontextinformationen und Nachrichtengeschichten. Es speichert diese Daten in Redis und ermöglicht ein einfaches Abrufen und Modifikationen. Der Manager bietet verschiedene Methoden zur Interaktion mit dem Cache, wie z. B.:
read_context_from_profile : liest den Chat -Kontext des Benutzers aus Redis gemäß dem Profil des Benutzers.create_context : Erstellt einen neuen Benutzer -Chat -Kontext in Redis.reset_context : Setzt den Chat -Kontext des Benutzers in Standardwerte zurück.update_message_histories : Aktualisiert die Nachrichtengeschichte für eine bestimmte Rolle (Benutzer, AI oder System).lpop_message_history / rpop_message_history : Entfernt und gibt den Nachrichtenverlauf vom linken oder rechten Ende der Liste zurück.append_message_history : Findet einen Nachrichtenverlauf bis zum Ende der Liste an.get_message_history : Ruft den Nachrichtenverlauf für eine bestimmte Rolle ab.delete_message_history : Löscht den Nachrichtenverlauf für eine bestimmte Rolle.set_message_history : Legt einen bestimmten Nachrichtenverlauf für eine Rolle und einen Index fest. Der Message Manager ( MessageManager ) stellt sicher, dass die Anzahl der Token in Nachrichtengeschichten das angegebene Grenzwert nicht überschreitet. Es wird sicheres Hinzufügen, Entfernen und Einstellen von Nachrichtengeschichten im Chat -Kontext des Benutzers und bei der Beibehaltung der Token -Grenzen. Der Manager stellt verschiedene Methoden zur Interaktion mit Nachrichtengeschichten an, wie z. B.:
add_message_history_safely : Fügt dem Chat -Kontext des Benutzers einen Nachrichtenverlauf hinzu und stellt sicher, dass die Token -Grenze nicht überschritten wird.pop_message_history_safely : Entfernt und gibt den Nachrichtenverlauf vom richtigen Ende der Liste zurück, während die Token -Anzahl aktualisiert wird.set_message_history_safely : Legt einen bestimmten Nachrichtenverlauf im Chat -Kontext des Benutzers fest, aktualisiert die Token -Anzahl und stellt sicher, dass die Token -Grenze nicht überschritten wird. Um den Cache -Manager und den Message Manager in Ihrem Projekt zu verwenden, importieren Sie sie wie folgt:
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManagerAnschließend können Sie ihre Methoden verwenden, um mit dem Redis -Cache zu interagieren und Nachrichtengeschichten gemäß Ihren Anforderungen zu verwalten.
Zum Beispiel zum Erstellen eines neuen Benutzer -Chat -Kontextes:
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )So fügen Sie dem Chat -Kontext des Benutzers einen Nachrichtenverlauf hinzu:
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role ) In diesem Projekt wird token_validator Middleware und andere Middlewares verwendet, die in der Fastapi -Anwendung verwendet werden. Diese Middlewares sind für die Kontrolle des Zugriffs auf die API verantwortlich und stellen sicher, dass nur autorisierte und authentifizierte Anforderungen bearbeitet werden.
Die folgenden Middlewares werden der Fastapi -Anwendung hinzugefügt:
Die Access Control Middleware ist in der Datei token_validator.py definiert. Es ist für die Validierung von API -Schlüssel und JWT -Token verantwortlich.
Die StateManager -Klasse wird verwendet, um die Anforderungsstatusvariablen zu initialisieren. Es legt die Anforderungszeit, die Startzeit, die IP -Adresse und das Benutzer -Token fest.
Die AccessControl -Klasse enthält zwei statische Methoden zur Validierung von API -Schlüssel und JWT -Token:
api_service : Validiert die API -Schlüssel, indem Sie das Vorhandensein der erforderlichen Abfrageparameter und -Header in der Anforderung überprüfen. Es ruft die Methode Validator.api_key auf, um den API -Schlüssel, das Geheimnis und den Zeitstempel zu überprüfen.non_api_service : Validiert JWT -Token, indem Sie die Existenz des Headers oder der "Autorisierung" Cookie in der Anfrage überprüfen. Es ruft die Methode Validator.jwt auf, um das JWT -Token zu dekodieren und zu überprüfen. Die Validator -Klasse enthält zwei statische Methoden zur Validierung von API -Schlüssel und JWT -Token:
api_key : Überprüft den API -Zugriffsschlüssel, das Hashed Secret und den Zeitstempel. Gibt ein UserToken -Objekt zurück, wenn die Validierung erfolgreich ist.jwt : Decodiert und überprüft das JWT -Token. Gibt ein UserToken -Objekt zurück, wenn die Validierung erfolgreich ist. Die Funktion access_control ist eine asynchrone Funktion, die den Anforderungs- und Antwortfluss für die Middleware übernimmt. Es initialisiert den Anforderungsstatus mithilfe der StateManager -Klasse, bestimmt die Art der Authentifizierung, die für die angeforderte URL (API -Schlüssel oder JWT -Token) erforderlich ist, und validiert die Authentifizierung mithilfe der AccessControl -Klasse. Wenn während des Validierungsprozesses ein Fehler auftritt, wird eine geeignete HTTP -Ausnahme erhöht.
Token -Dienstprogramme sind in der token.py -Datei definiert. Es enthält zwei Funktionen:
create_access_token : Erstellt ein JWT -Token mit den angegebenen Daten und der Ablaufzeit.token_decode : decodes und überprüft ein JWT -Token. Erhöht eine Ausnahme, wenn das Token abgelaufen ist oder nicht dekodiert werden kann. Die Datei params_utils.py enthält eine Dienstprogrammfunktion für Hashing -Abfrageparameter und geheimen Schlüssel unter Verwendung von HMAC und SHA256:
hash_params : Nimmt Abfrageparameter und geheime Schlüssel als Eingabe an und gibt eine base64 codierte Hashed -Zeichenfolge zurück. Die Datei date_utils.py enthält die UTC -Klasse mit Dienstprogrammfunktionen für die Arbeit mit Daten und Zeitstempeln:
now : Gibt die aktuelle UTC -DateTime mit einem optionalen Stundenunterschied zurück.timestamp : Gibt den aktuellen UTC -Zeitstempel mit einem optionalen Stundenunterschied zurück.timestamp_to_datetime : Konvertiert einen Zeitstempel mit einem optionalen Stundenunterschied in ein DateTime -Objekt. Die Datei logger.py enthält die ApiLogger -Klasse, die die API -Anforderung und die Antwortinformationen anmelden, einschließlich der Anforderungs -URL-, Methode-, Statuscode-, Client -Informationen, -D -Zeit- und Fehlerdetails (falls zutreffend). Die Logger -Funktion wird am Ende der Funktion access_control aufgerufen, um die verarbeitete Anforderung und Antwort zu protokollieren.
Um die Middleware token_validator in Ihrer Fastapi -Anwendung zu verwenden, importieren Sie einfach die Funktion access_control und fügen Sie sie als Middleware zu Ihrer Fastapi -Instanz hinzu:
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )Stellen Sie sicher, dass Sie auch die CORs und vertrauenswürdigen Host -Middlewares hinzufügen, um eine vollständige Zugriffskontrolle zu erhalten:
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
) Jetzt werden alle eingehenden Anfragen an Ihre Fastapi -Anwendung von der MiddleWare und anderen Middlewares token_validator bearbeitet, um sicherzustellen, dass nur autorisierte und authentifizierte Anfragen bearbeitet werden.
Diese Modul- app.database.connection bietet eine benutzerfreundliche Schnittstelle für die Verwaltung von Datenbankverbindungen und die Ausführung von SQL-Abfragen mithilfe von SQLalchemy und Redis. Es unterstützt MySQL und kann leicht in dieses Projekt integriert werden.
Importieren Sie zunächst die erforderlichen Klassen aus dem Modul:
from app . database . connection import MySQL , SQLAlchemy , CacheFactory Erstellen Sie als Nächstes eine Instanz der SQLAlchemy -Klasse und konfigurieren Sie sie mit Ihren Datenbankeinstellungen:
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config ) Jetzt können Sie die db -Instanz verwenden, um SQL -Abfragen auszuführen und Sitzungen zu verwalten:
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" ) Um Redis Caching zu verwenden, erstellen Sie eine Instanz der CacheFactory -Klasse und konfigurieren Sie sie mit Ihren Redis -Einstellungen:
cache = CacheFactory ()
cache . start ( config ) Sie können jetzt die cache -Instanz verwenden, um mit Redis zu interagieren:
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" ) In diesem Projekt führt die MySQL -Klasse das erste Setup beim App Startup durch, und alle Datenbankverbindungen werden nur mit den am Ende des Moduls vorhandenen db und cache -Variablen hergestellt. ?
Alle DB -Einstellungen werden in create_app() in app.common.app_settings erfolgen. Beispielsweise sieht die Funktion create_app() in app.common.app_settings so aus:
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_app Dieses Projekt verwendet eine einfache und effiziente Möglichkeit app.database.crud Datenbank -CRUD -Operationen mithilfe von app.database.models.schema sowie zwei Modul und Pfad zu verarbeiten (zu lesen, zu aktualisieren, zu löschen).
Das schema.py -Modul ist für die Definition von Datenbankmodellen und deren Beziehungen mithilfe von SQLALCHEMY verantwortlich. Es enthält eine Reihe von Klassen, die von Base erben, eine Instanz von declarative_base() . Jede Klasse repräsentiert eine Tabelle in der Datenbank und ihre Attribute stellen Spalten in der Tabelle dar. Diese Klassen erben auch aus einer Mixin -Klasse, die einige gemeinsame Methoden und Attribute für alle Modelle liefert.
Die Mixin -Klasse bietet einige gemeinsame Attribute und Methoden für alle Klassen, die daraus erben. Einige der Attribute umfassen:
id : Integer Primärschlüssel für die Tabelle.created_at : DateTime für wann der Datensatz erstellt wurde.updated_at : DateTime für den Zeitpunkt, an dem der Datensatz zuletzt aktualisiert wurde.ip_address : IP -Adresse des Clients, der den Datensatz erstellt oder aktualisiert hat.Es bietet auch mehrere Klassenmethoden, die CRUD -Operationen mit SQLAlchemy ausführen, z. B.:
add_all() : Fügt der Datenbank mehrere Datensätze hinzu.add_one() : Fügt der Datenbank einen einzelnen Datensatz hinzu.update_where() : Aktualisiert Datensätze in der Datenbank basierend auf einem Filter.fetchall_filtered_by() : Abret alle Datensätze aus der Datenbank, die mit dem bereitgestellten Filter übereinstimmt.one_filtered_by() : Ruft einen einzelnen Datensatz aus der Datenbank ab, die dem bereitgestellten Filter entspricht.first_filtered_by() : Ruft den ersten Datensatz aus der Datenbank ab, die dem bereitgestellten Filter entspricht.one_or_none_filtered_by() : Ruft einen einzelnen Datensatz ab oder gibt None zurück, wenn keine Datensätze mit dem angegebenen Filter übereinstimmen. Das Modul der users.py und api_keys.py enthält eine Reihe von Funktionen, die CRUD -Operationen unter Verwendung der in schema.py definierten Klassen ausführen. Diese Funktionen verwenden die von der Mixin -Klasse bereitgestellten Klassenmethoden, um mit der Datenbank zu interagieren.
Einige der Funktionen in diesem Modul umfassen:
create_api_key() : Erstellt einen neuen API -Schlüssel für einen Benutzer.get_api_keys() : Ruft alle API -Schlüssel für einen Benutzer ab.get_api_key_owner() : Ruft den Besitzer eines API -Schlüssels ab.get_api_key_and_owner() : Ruft einen API -Schlüssel und seinen Besitzer ab.update_api_key() : Aktualisiert einen API -Schlüssel.delete_api_key() : löscht einen API -Schlüssel.is_email_exist() : Überprüft, ob in der Datenbank eine E -Mail vorhanden ist.get_me() : Ruft Benutzerinformationen basierend auf der Benutzer -ID ab.is_valid_api_key() : Überprüft, ob ein API -Schlüssel gültig ist.register_new_user() : Registriert einen neuen Benutzer in der Datenbank.find_matched_user() : findet einen Benutzer mit einer passenden E -Mail in der Datenbank. Um die bereitgestellten CRUD -Operationen zu verwenden, importieren Sie die entsprechenden Funktionen aus dem crud.py -Modul und rufen Sie sie mit den erforderlichen Parametern auf. Zum Beispiel:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())