LLMChat
v1.1.3.4.1
Bienvenue dans le référentiel LLMCHAT, une implémentation complète d'un serveur API construit avec Python Fastapi, et une belle frontend propulsée par Flutter. Ce projet est conçu pour offrir une expérience de chat sans couture avec le Chatgpt avancé et d'autres modèles LLM. ? Offrant une infrastructure moderne qui peut être facilement étendue lorsque les fonctionnalités multimodales et plugin de GPT-4 deviennent disponibles. Profitez de votre séjour!
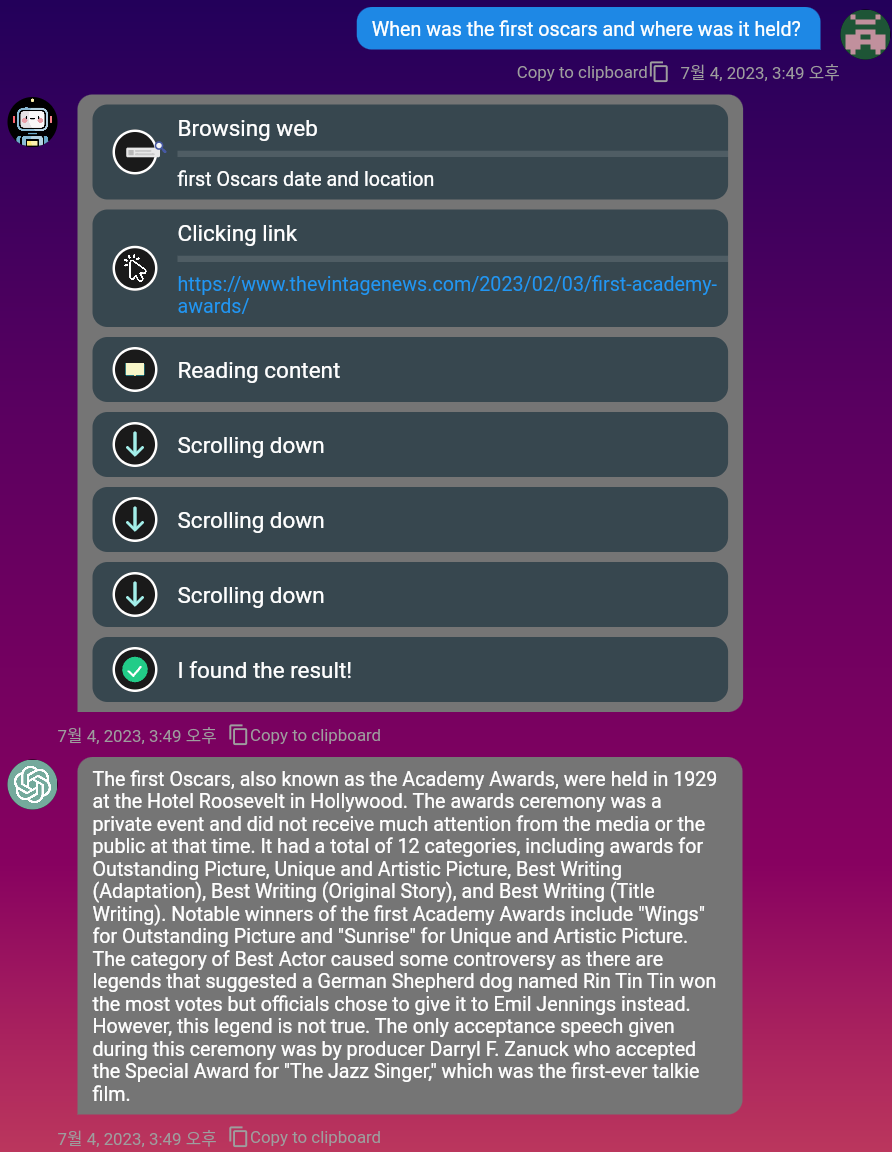
mobile et PC .Markdown est également pris en charge, vous pouvez donc l'utiliser pour formater vos messages.Vous pouvez utiliser le moteur de recherche DuckDuckgo pour trouver des informations pertinentes sur le Web. Activez simplement le bouton à bascule «Parcourir»!
Regardez la vidéo de démonstration pour la navigation complète: https://www.youtube.com/watch?v=MJ_CVRWRS08
Avec la commande /embed , vous pouvez stocker le texte indéfiniment dans votre propre base de données vectorielle privée et l'interroger plus tard, à tout moment. Si vous utilisez la commande /share , le texte est stocké dans une base de données de vecteur public que tout le monde peut partager. L'activation du bouton de bascule Query ou de la commande /query aide l'IA à générer des réponses contextualisées en recherchant des similitudes de texte dans les bases de données publiques et privées. Cela résout l'une des plus grandes limites des modèles de langue: la mémoire .
Vous pouvez intégrer le fichier PDF en cliquant sur Embed Document en bas à gauche. En quelques secondes, le contenu du texte de PDF sera converti en vecteurs et intégré à Redis Cache.
LLMModels qui se trouve dans app/models/llms.py Pour le LLALAM LLMS local, il est supposé ne fonctionner que dans l'environnement local et utilise le point de terminaison http://localhost:8002/v1/completions . Il vérifie en continu l'état du serveur API LLAMA en se connectant à http://localhost:8002/health une fois par seconde pour voir si une réponse de 200 OK est renvoyée, et sinon, il exécute automatiquement un processus distinct pour créer un serveur API.
L'objectif principal de Llama.cpp est d'exécuter le modèle LLAMA en utilisant la quantification GGML 4 bits avec une implémentation C / C ++ simple sans dépendances. Vous devez télécharger le fichier GGML bin à partir de HuggingFace et le mettre dans le dossier llama_models/ggml , et définir LLMModel dans app/models/llms.py Il existe peu d'exemples, vous pouvez donc facilement définir votre propre modèle. Reportez-vous au référentiel llama.cpp pour plus d'informations: https://github.com/ggerganov/llama.cpp
Une implémentation autonome Python / C ++ / CUDA de LLAMA pour une utilisation avec des poids GPTQ 4 bits, conçus pour être rapide et économe en mémoire sur les GPU modernes. Il utilise pytorch et sentencepiece pour exécuter le modèle. Il est supposé ne fonctionner que dans l'environnement local et au moins un NVIDIA CUDA GPU est nécessaire. Vous devez télécharger des fichiers Tokenizer, Config et GPTQ à partir de HuggingFace et le mettre dans le dossier llama_models/gptq/YOUR_MODEL_FOLDER , et définir LLMMODEL dans app/models/llms.py Il existe peu d'exemples, vous pouvez donc facilement définir votre propre modèle. Reportez-vous au référentiel exllama pour des informations plus détaillées: https://github.com/turboderp/exlma
web framework haute performance pour la création d'API avec Python.Webapp Frontend avec une belle interface utilisateur et un ensemble riche de widgets personnalisables.OpenAI API pour la génération de texte et la gestion des messages.LlamaCpp et Exllama .Real-time avec le Chatgpt et d'autres modèles LLM, avec Flutter Frontend WebApp.Redis et Langchain , stockez et récupérez des intégres vectoriels pour une recherche de similitude. Cela aidera l'IA à générer des réponses plus pertinentes.Duckduckgo , parcourez le Web et trouvez des informations pertinentes.async / await pour la concurrence et le parallélisme.MySQL . Effectuez facilement Créer, lire, mettre à jour et supprimer des actions, avec sqlalchemy.asyncioRedis avec Aioredis. Effectuez facilement Créer, lire, mettre à jour et supprimer des actions, avec aioredis . Pour configurer la machine locale, suivez ces étapes simples. Avant de commencer, assurez-vous que docker et docker-compose installés sur votre machine. Si vous souhaitez exécuter le serveur sans Docker, vous devez également installer Python 3.11 . Même si vous avez besoin Docker pour exécuter des serveurs DB.
Pour cloner récursivement les sous-modules pour utiliser les modèles Exllama ou llama.cpp , utilisez la commande suivante:
git clone --recurse-submodules https://github.com/c0sogi/llmchat.gitVous souhaitez uniquement utiliser les fonctionnalités de base (OpenAI), utilisez la commande suivante:
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.env Configurez un fichier env, faisant référence au fichier .env-sample . Entrez les informations de base de données pour créer, la touche API OpenIA et d'autres configurations nécessaires. Les options ne sont pas nécessaires, laissez-les simplement comme ils le sont.
Les exécuter. Cela peut prendre quelques minutes pour démarrer le serveur pour la première fois:
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml down Vous pouvez désormais accéder au serveur sur http://localhost:8000/docs et la base de données à db:3306 ou cache:6379 . Vous pouvez également accéder à l'application sur http://localhost:8000/chat .
Pour exécuter le serveur sans Docker si vous souhaitez exécuter le serveur sans Docker, vous devez également installer Python 3.11 . Même si vous avez besoin Docker pour exécuter des serveurs DB. Éteignez le serveur API déjà en cours d'exécution avec docker-compose -f docker-compose-local.yaml down api . N'oubliez pas d'exécuter d'autres serveurs DB sur Docker! Ensuite, exécutez les commandes suivantes:
python -m main Votre serveur devrait maintenant être opérationnel sur http://localhost:8001 dans ce cas.
Ce projet est autorisé en vertu de la licence MIT, qui permet une utilisation, une modification et une distribution gratuites, tant que le droit d'auteur et l'avis de licence d'origine sont inclus dans toute copie ou partie substantielle du logiciel.
FastAPI est un cadre Web moderne pour créer des API avec Python. ? Il a des performances élevées, facile à apprendre, rapide à coder et prêt pour la production. ? L'une des principales caractéristiques de FastAPI est qu'elle prend en charge la concurrence et la syntaxe async / await . ? Cela signifie que vous pouvez écrire du code qui peut gérer plusieurs tâches en même temps sans se bloquer, en particulier lorsque vous traitez des opérations liées aux E / S, telles que les demandes de réseau, les requêtes de base de données, les opérations de fichiers, etc.
Flutter est une boîte à outils d'interface utilisateur open source développée par Google pour créer des interfaces utilisateur natives pour les plates-formes mobiles, Web et de bureau à partir d'une seule base de code. ? Il utilise Dart , un langage de programmation orienté objet moderne, et fournit un ensemble riche de widgets personnalisables qui peuvent s'adapter à n'importe quelle conception.
Vous pouvez accéder ChatGPT ou LlamaCpp via la connexion WebSocket à l'aide de deux modules: app/routers/websocket et app/utils/chat/chat_stream_manager . Ces modules facilitent la communication entre le client Flutter et le modèle de chat via un WebSocket. Avec le WebSocket, vous pouvez établir un canal de communication bidirectionnel en temps réel pour interagir avec le LLM.
Pour démarrer une conversation, connectez-vous à la route WebSocket /ws/chat/{api_key} avec une clé API valide enregistrée dans la base de données. Notez que cette clé API n'est pas la même que la clé API OpenAI, mais disponible uniquement pour votre serveur pour valider l'utilisateur. Une fois connecté, vous pouvez envoyer des messages et des commandes pour interagir avec le modèle LLM. Le WebSocket renverra les réponses de chat en temps réel. Cette connexion WebSocket est établie via Flutter App, qui peut accéder à Endpoint /chat .
websocket.py est responsable de la configuration d'une connexion WebSocket et de la gestion de l'authentification des utilisateurs. Il définit la route WebSocket /chat/{api_key} qui accepte une clé WebSocket et une clé API comme paramètres.
Lorsqu'un client se connecte à WebSocket, il vérifie d'abord la touche API pour authentifier l'utilisateur. Si la touche API est valide, la fonction begin_chat() est appelée du module stream_manager.py pour démarrer la conversation.
En cas d'une clé API non enregistrée ou d'une erreur inattendue, un message approprié est envoyé au client et la connexion est fermée.
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.py est responsable de la gestion de la conversation et de la gestion des messages utilisateur. Il définit la fonction begin_chat() , qui prend un WebSocket, un ID utilisateur comme paramètres.
La fonction initialise d'abord le contexte de chat de l'utilisateur à partir du gestionnaire de cache. Ensuite, il envoie l'historique des messages initial au client via le WebSocket.
La conversation se poursuit dans une boucle jusqu'à ce que la connexion soit fermée. Au cours de la conversation, les messages de l'utilisateur sont traités et les réponses de GPT sont générées en conséquence.
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
... La classe SendToWebsocket est utilisée pour envoyer des messages et des flux sur WebSocket. Il a deux méthodes: message() et stream() . La méthode message() envoie un message complet au WebSocket, tandis que la méthode stream() envoie un flux au WebSocket.
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
... La classe MessageHandler gère également les réponses AI. La méthode ai() envoie la réponse AI au WebSocket. Si la traduction est activée, la réponse est traduite à l'aide de l'API Google Translate avant de l'envoyer au client.
class MessageHandler :
...
@ staticmethod
async def ai (...):
... Les messages utilisateur sont traités à l'aide de la classe HandleMessage . Si le message commence par / , tel que /YOUR_CALLBACK_NAME . Il est traité comme une commande et la réponse de commande appropriée est générée. Sinon, le message de l'utilisateur est traité et envoyé au modèle LLM pour générer une réponse.
Les commandes sont gérées à l'aide de la classe ChatCommands . Il exécute la fonction de rappel correspondante en fonction de la commande. Vous pouvez ajouter de nouvelles commandes en ajoutant simplement un rappel dans la classe ChatCommands à partir d' app.utils.chat.chat_commands .
Utilisation de redis pour stocker des incorporations vectorielles de conversations? ️ Peut aider le modèle Chatgpt? De plusieurs manières, telles que la récupération efficace et rapide du contexte de la conversation ♀️, gérer de grandes quantités de données et fournir des réponses plus pertinentes grâce à la recherche de similitude vectorielle ?.
Quelques exemples amusants de la façon dont cela pourrait fonctionner dans la pratique:
/embed Lorsqu'un utilisateur entre dans une commande dans la fenêtre de chat comme /embed <text_to_embed> , la méthode VectorStoreManager.create_documents est appelée. Cette méthode convertit le texte d'entrée en un vecteur en utilisant le modèle text-embedding-ada-002 d'OpenAI et le stocke dans le VectorStore Redis.
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../query Lorsque l'utilisateur entre dans la commande /query <query> , la fonction asimilarity_search est utilisée pour trouver jusqu'à trois résultats avec la similitude vectorielle la plus élevée avec les données intégrées dans le Vectorstore Redis. Ces résultats sont temporairement stockés dans le contexte du chat, ce qui aide l'IA à répondre à la requête en faisant référence à ces données.
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
... Lors de l'exécution de la fonction begin_chat , si un utilisateur télécharge un fichier contenant du texte (par exemple, un fichier PDF ou TXT), le texte est automatiquement extrait du fichier et son intégration vectorielle est enregistrée sur Redis.
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py Fonctionnalité Dans le fichier commands.py , il existe plusieurs composants importants:
command_response : cette classe est utilisée pour définir un décorateur sur la méthode de commande pour spécifier la prochaine action. Il aide à définir divers types de réponse, tels que l'envoi d'un message et l'arrêt, l'envoi d'un message et la poursuite, la gestion des entrées des utilisateurs, la gestion des réponses d'IA, etc.command_handler : Cette fonction est responsable de l'exécution d'une méthode de rappel de commande basée sur le texte entré par l'utilisateur.arguments_provider : Cette fonction fournit automatiquement les arguments requis par la méthode de commande basée sur le type d'annotation de la méthode de commande.Déclenchement de la tâche : cette fonctionnalité est activée chaque fois qu'un utilisateur tape un message ou que l'IA répond par un message. À ce stade, une tâche de résumé automatique est générée pour condenser le contenu texte.
Stockage des tâches : la tâche de sous-estime automatique est ensuite stockée dans l'attribut task_list du BufferUserChatContext . Cela sert de file d'attente pour gérer les tâches liées au contexte de chat de l'utilisateur.
Récolte de tâches : Après l'achèvement d'un cycle de questions et réponses de l'utilisateur par le MessageHandler , la fonction harvest_done_tasks est invoquée. Cette fonction recueille les résultats de la tâche de résumé, en s'assurant que rien n'est laissé de côté.
Application de résumé : Après le processus de récolte, les résultats résumés remplacent le message réel lorsque notre chatbot demande des réponses des modèles d'apprentissage des langues (LLMS), tels que OpenAI et llama_cpp. Ce faisant, nous pouvons envoyer des invites beaucoup plus succinctes que le long message initial.
Expérience utilisateur : surtout, du point de vue de l'utilisateur, ils ne voient que le message d'origine. La version résumée du message ne leur est pas montrée, en maintenant la transparence et en évitant la confusion potentielle.
Tâches simultanées : Une autre caractéristique clé de cette tâche de surévaluation automatique est qu'elle ne gêne pas d'autres tâches. En d'autres termes, alors que le chatbot est occupé à résumer le texte, d'autres tâches peuvent toujours être effectuées, améliorant ainsi l'efficacité globale de notre chatbot.
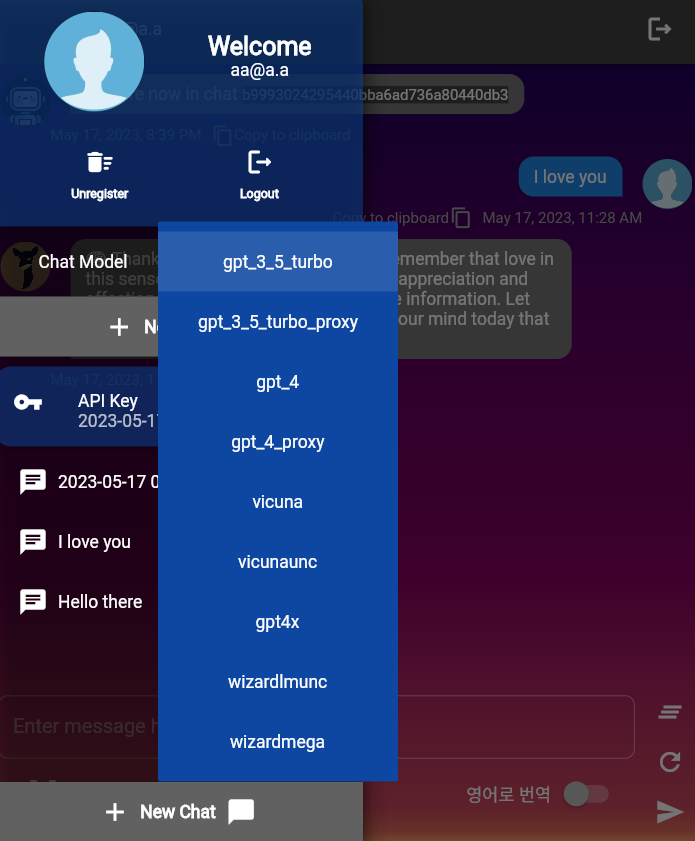
ChatConfig . Ce référentiel contient différents modèles LLM, définis dans llms.py Chaque classe de modèle LLM hérite de la classe de base LLMModel . L'énumération LLMModels est une collection de ces LLM.
Toutes les opérations sont manipulées de manière asynchrone sans enterrer le fil principal. Cependant, les LLM locaux ne sont pas en mesure de gérer plusieurs demandes en même temps, car elles sont trop coûteuses. Par conséquent, un Semaphore est utilisé pour limiter le nombre de demandes à 1.
Le modèle LLM par défaut utilisé par l'utilisateur via UserChatContext.construct_default est gpt-3.5-turbo . Vous pouvez modifier la valeur par défaut de cette fonction.
OpenAIModel génère du texte de manière asynchrone en demandant l'achèvement du chat à partir du serveur OpenAI. Il nécessite une clé API OpenAI.
LlamaCppModel lit un modèle GGML stocké localement. Le modèle LLAMA.CPP GGML doit être placé dans le dossier llama_models/ggml en tant que fichier .bin . Par exemple, si vous avez téléchargé un modèle quantifié Q4_0 à partir de "https://huggingface.co/thebloke/robin-7b-v2-ggml", le chemin du modèle doit être "Robin-7b.ggmlv3.q4_0.bin".
ExllamaModel Lire un modèle GPTQ stocké localement. Le modèle Exllama GPTQ doit être placé dans le dossier llama_models/gptq en tant que dossier. Par exemple, si vous avez téléchargé 3 fichiers à partir de "https://huggingface.co/thebloke/orca_mini_7b-gptq/tree/main":
Ensuite, vous devez les mettre dans un dossier. Le chemin du modèle doit être le nom du dossier. Disons "Orca_mini_7b", qui contient les 3 fichiers.
Gérer les exceptions qui peuvent survenir pendant la génération de texte. Si une ChatLengthException est lancée, elle effectue automatiquement une routine pour remettre le message au nombre de jetons limités par la fonction cutoff_message_histories et le renvoyer. Cela garantit que l'utilisateur a une expérience de chat en douceur quelle que soit la limite de jeton.
Ce projet vise à créer un backend API pour activer le service de chatbot de modèle de grande langue. Il utilise un gestionnaire de cache pour stocker des messages et des profils d'utilisateurs dans Redis, et un gestionnaire de messages pour mettre en sécurité les messages en toute sécurité afin que le nombre de jetons ne dépasse pas une limite acceptable.
Le Cache Manager ( CacheManager ) est responsable de la gestion des informations du contexte des utilisateurs et des histoires de messages. Il stocke ces données dans Redis, permettant une récupération et une modification faciles. Le gestionnaire fournit plusieurs méthodes pour interagir avec le cache, telles que:
read_context_from_profile : lit le contexte de chat de l'utilisateur à partir de redis, selon le profil de l'utilisateur.create_context : crée un nouveau contexte de chat utilisateur dans redis.reset_context : réinitialise le contexte de chat de l'utilisateur aux valeurs par défaut.update_message_histories : met à jour les histoires de messages pour un rôle spécifique (utilisateur, IA ou système).lpop_message_history / rpop_message_history : Supprime et renvoie l'historique des messages de l'extrémité gauche ou droite de la liste.append_message_history : Ajoute un historique de messages à la fin de la liste.get_message_history : récupère l'historique des messages pour un rôle spécifique.delete_message_history : Supprime l'historique des messages pour un rôle spécifique.set_message_history : Définit un historique de messages spécifique pour un rôle et un index. Le gestionnaire de messages ( MessageManager ) garantit que le nombre de jetons dans les histoires de messages ne dépasse pas la limite spécifiée. Il gère en toute sécurité l'ajout, la suppression et la définition d'histoires de messages dans le contexte de chat de l'utilisateur tout en maintenant les limites de jetons. Le gestionnaire fournit plusieurs méthodes pour interagir avec les histoires de messages, telles que:
add_message_history_safely : ajoute un historique de message au contexte de chat de l'utilisateur, garantissant que la limite de jeton n'est pas dépassée.pop_message_history_safely : supprime et renvoie l'historique des messages de l'extrémité droite de la liste lors de la mise à jour du nombre de jetons.set_message_history_safely : Définit un historique de messages spécifique dans le contexte de chat de l'utilisateur, mise à jour du nombre de jetons et garantissant que la limite de jeton n'est pas dépassée. Pour utiliser le gestionnaire de cache et le gestionnaire de messages dans votre projet, importez-les comme suit:
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManagerEnsuite, vous pouvez utiliser leurs méthodes pour interagir avec le cache Redis et gérer les antécédents de messages en fonction de vos exigences.
Par exemple, pour créer un nouveau contexte de chat utilisateur:
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )Pour ajouter en toute sécurité un historique de messages au contexte de chat de l'utilisateur:
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role ) Ce projet utilise token_validator Middleware et autres Middlewares utilisés dans l'application FastAPI. Ces moyennes intermédiaires sont responsables du contrôle de l'accès à l'API, garantissant que seules les demandes autorisées et authentifiées sont traitées.
Les moyennes suivantes sont ajoutées à l'application Fastapi:
Le middleware de contrôle d'accès est défini dans le fichier token_validator.py . Il est responsable de la validation des clés API et des jetons JWT.
La classe StateManager est utilisée pour initialiser les variables d'état de demande. Il définit l'heure de demande, l'heure de début, l'adresse IP et le jeton utilisateur.
La classe AccessControl contient deux méthodes statiques pour valider les clés d'API et les jetons JWT:
api_service : valide les clés de l'API en vérifiant l'existence des paramètres de requête et des en-têtes requis dans la demande. Il appelle la méthode Validator.api_key pour vérifier la clé API, le secret et l'horodatage.non_api_service : valide les jetons JWT en vérifiant l'existence de l'en-tête «Autorisation» ou du cookie «Autorisation» dans la demande. Il appelle la méthode Validator.jwt pour décoder et vérifier le jeton JWT. La classe Validator contient deux méthodes statiques pour valider les clés d'API et les jetons JWT:
api_key : Vérifie la clé d'accès API, le secret haché et l'horodatage. Renvoie un objet UserToken si la validation est réussie.jwt : décode et vérifie le jeton JWT. Renvoie un objet UserToken si la validation est réussie. La fonction access_control est une fonction asynchrone qui gère le flux de demande et de réponse pour le middleware. Il initialise l'état de demande à l'aide de la classe StateManager , détermine le type d'authentification requis pour l'URL demandée (clé API ou jeton JWT) et valide l'authentification à l'aide de la classe AccessControl . Si une erreur se produit pendant le processus de validation, une exception HTTP appropriée est augmentée.
Les utilitaires de jeton sont définis dans le fichier token.py . Il contient deux fonctions:
create_access_token : crée un jeton JWT avec les données et le temps d'expiration donné.token_decode : décode et vérifie un jeton JWT. Soulève une exception si le jeton est expiré ou ne peut pas être décodé. Le fichier params_utils.py contient une fonction utilitaire pour les paramètres de requête de hachage et la clé secrète à l'aide de HMAC et SHA256:
hash_params : prend les paramètres de requête et la clé secrète en entrée et renvoie une chaîne hachée codée Base64. Le fichier date_utils.py contient la classe UTC avec des fonctions utilitaires pour travailler avec les dates et les horodatages:
now : renvoie la DateTime UTC actuelle avec une différence d'heure facultative.timestamp : renvoie l'horodatage UTC actuel avec une différence d'heure facultative.timestamp_to_datetime : convertit une horodatage en un objet DateTime avec une différence d'heure facultative. Le fichier logger.py contient la classe ApiLogger , qui enregistre les informations de demande et de réponse de l'API, y compris l'URL de demande, la méthode, le code d'état, les informations du client, le temps de traitement et les détails d'erreur (le cas échéant). La fonction Logger est appelée à la fin de la fonction access_control pour enregistrer la demande et la réponse traitées.
Pour utiliser le middleware token_validator dans votre application Fastapi, importez simplement la fonction access_control et ajoutez-les en middleware à votre instance Fastapi:
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )Assurez-vous également d'ajouter les COR et les moyens de confiance de fiabilité pour un contrôle d'accès complet:
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
) Désormais, toutes les demandes entrantes à votre application FastAPI seront traitées par le middleware token_validator et d'autres Middlewares, garantissant que seules les demandes autorisées et authentifiées sont traitées.
Ce module app.database.connection fournit une interface facile à utiliser pour gérer les connexions de la base de données et exécuter des requêtes SQL à l'aide de SQLALCHEMY et Redis. Il prend en charge MySQL et peut être facilement intégré à ce projet.
Tout d'abord, importez les classes requises du module:
from app . database . connection import MySQL , SQLAlchemy , CacheFactory Ensuite, créez une instance de la classe SQLAlchemy et configurez-la avec vos paramètres de base de données:
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config ) Vous pouvez maintenant utiliser l'instance db pour exécuter des requêtes SQL et gérer les sessions:
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" ) Pour utiliser la mise en cache Redis, créez une instance de la classe CacheFactory et configurez-la avec vos paramètres redis:
cache = CacheFactory ()
cache . start ( config ) Vous pouvez maintenant utiliser l'instance cache pour interagir avec Redis:
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" ) En fait, dans ce projet, la classe MySQL fait la configuration initiale au démarrage de l'APP, et toutes les connexions de la base de données sont effectuées uniquement avec les variables db et cache présentes à la fin du module. ?
Tous les paramètres DB seront effectués dans create_app() dans app.common.app_settings . Par exemple, la fonction create_app() dans app.common.app_settings ressemblera à ceci:
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_app Ce projet utilise un moyen simple et efficace de gérer les opérations CUD (créer, lire, mettre à jour, supprimer) à l'aide de sqlalchemy et de deux modules et chemin: app.database.models.schema et app.database.crud .
Le module schema.py est responsable de la définition des modèles de base de données et de leurs relations à l'aide de SQLALCHEMY. Il comprend un ensemble de classes qui héritent de Base , une instance de declarative_base() . Chaque classe représente une table dans la base de données, et ses attributs représentent des colonnes dans le tableau. Ces classes héritent également d'une classe Mixin , qui fournit des méthodes et des attributs communs pour tous les modèles.
La classe Mixin fournit quelques attributs et méthodes communs pour toutes les classes qui en héritent. Certains des attributs comprennent:
id : clé primaire entière pour le tableau.created_at : datetime pour le moment où l'enregistrement a été créé.updated_at : DateTime pour le moment où l'enregistrement a été mis à jour pour la dernière fois.ip_address : adresse IP du client qui a créé ou mis à jour l'enregistrement.Il fournit également plusieurs méthodes de classe qui effectuent des opérations CRUD à l'aide de Sqlalchemy, telles que:
add_all() : ajoute plusieurs enregistrements à la base de données.add_one() : ajoute un seul enregistrement à la base de données.update_where() : met à jour les enregistrements dans la base de données en fonction d'un filtre.fetchall_filtered_by() : récupère tous les enregistrements de la base de données qui correspondent au filtre fourni.one_filtered_by() : Repare un seul enregistrement de la base de données qui correspond au filtre fourni.first_filtered_by() : Récupère le premier enregistrement de la base de données qui correspond au filtre fourni.one_or_none_filtered_by() : récupère un seul enregistrement ou ne renvoie None si aucun enregistrement ne correspond au filtre fourni. Le module users.py et api_keys.py contient un ensemble de fonctions qui effectuent des opérations CRUD à l'aide des classes définies dans schema.py . Ces fonctions utilisent les méthodes de classe fournies par la classe de mixin pour interagir avec la base de données.
Certaines des fonctions de ce module comprennent:
create_api_key() : crée une nouvelle clé API pour un utilisateur.get_api_keys() : récupère toutes les clés de l'API pour un utilisateur.get_api_key_owner() : récupère le propriétaire d'une clé API.get_api_key_and_owner() : récupère une clé API et son propriétaire.update_api_key() : met à jour une clé API.delete_api_key() : supprime une clé API.is_email_exist() : vérifie si un e-mail existe dans la base de données.get_me() : récupère les informations utilisateur en fonction de l'ID utilisateur.is_valid_api_key() : vérifie si une clé API est valide.register_new_user() : enregistre un nouvel utilisateur dans la base de données.find_matched_user() : trouve un utilisateur avec un e-mail correspondant dans la base de données. Pour utiliser les opérations CRUD fournies, importez les fonctions pertinentes du module crud.py et appelez-les avec les paramètres requis. Par exemple:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())