LLMChat
v1.1.3.4.1
LLMChatリポジトリ、Python Fastapiで構築されたAPIサーバーのフルスタック実装、およびFlutterを搭載した美しいフロントエンドを歓迎します。このプロジェクトは、高度なChatGPTおよびその他のLLMモデルでシームレスなチャットエクスペリエンスを提供するように設計されています。 ? GPT-4のマルチモーダルおよびプラグイン機能が利用可能になったときに簡単に拡張できる最新のインフラストラクチャを提供します。滞在をお楽しみください!
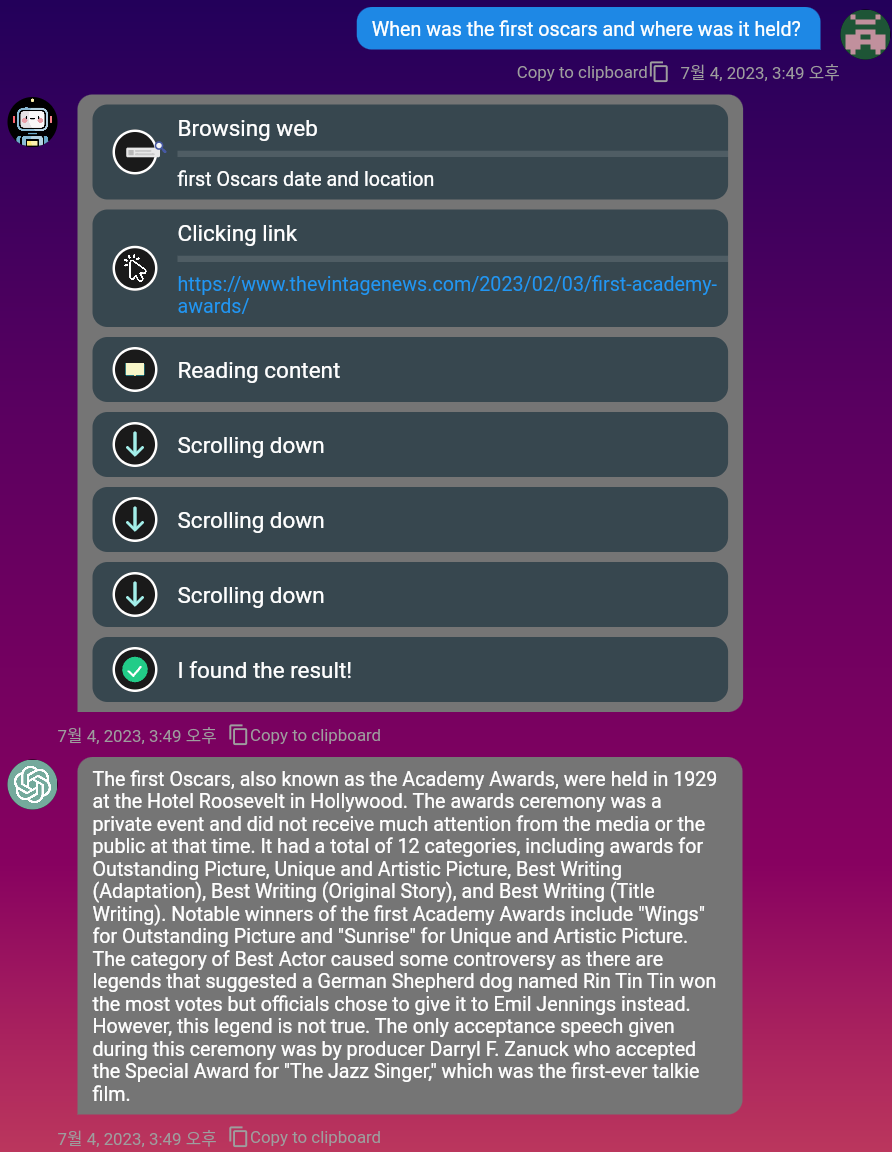
mobileとPC環境の両方をサポートします。Markdownもサポートされているため、メッセージをフォーマットするために使用できます。Duckduckgo検索エンジンを使用して、Web上の関連情報を見つけることができます。 「参照」トグルボタンをアクティブにするだけです!
フルブラウジングのデモビデオをご覧ください:https://www.youtube.com/watch?v=mj_cvrwrs08
/embedコマンドを使用すると、テキストを独自のプライベートベクトルデータベースに無期限に保存し、いつでも後で照会できます。 /shareコマンドを使用すると、テキストは誰もが共有できるパブリックベクトルデータベースに保存されます。 Queryトグルボタンまたは/queryコマンドを有効にすると、パブリックデータベースとプライベートデータベースでテキストの類似性を検索することにより、AIがコンテキスト化された回答を生成するのに役立ちます。これにより、言語モデルの最大の制限の1つであるメモリが解決されます。
左下にEmbed Documentをクリックすると、PDFファイルを埋め込むことができます。数秒で、PDFのテキストコンテンツがベクトルに変換され、Redisキャッシュに埋め込まれます。
app/models/llms.pyにあるLLMModelsで使用するモデルを定義できます。 ローカルLLALAM LLMSの場合、ローカル環境でのみ動作し、 http://localhost:8002/v1/completionsエンドポイントを使用すると想定されています。 http://localhost:8002/healthに1秒1回接続することにより、Llama APIサーバーのステータスを継続的にチェックして、200 OK応答が返されるかどうかを確認します。
llama.cppの主な目標は、依存関係なしに平易なC/C ++実装を使用してGGML 4ビット量子化を使用してLLAMAモデルを実行することです。 HuggingfaceからGGML binファイルをダウンロードし、 llama_models/ggmlフォルダーに入れて、 app/models/llms.pyでllmmodelを定義する必要があります。例はほとんどないので、独自のモデルを簡単に定義できます。詳細については、 llama.cppリポジトリを参照してください:https://github.com/ggerganov/llama.cpp
最新のGPUで高速でメモリ効率の高いように設計された4ビットGPTQ重みで使用するためのLlamaのスタンドアロンPython/C ++/CUDA実装。 pytorchとsentencepieceを使用してモデルを実行します。ローカル環境でのみ機能すると想定されており、少なくとも1つのNVIDIA CUDA GPU必要です。 HuggingfaceからTokenizer、Config、およびGPTQファイルをダウンロードし、 llama_models/gptq/YOUR_MODEL_FOLDERフォルダーに入れて、 app/models/llms.pyでllmmodelを定義する必要があります。例はほとんどないので、独自のモデルを簡単に定義できます。詳細については、 exllamaリポジトリを参照してください:https://github.com/turboderp/exllama
web framework 。Webapp Frontend。OpenAI APIとのシームレスな統合。LlamaCpp 、 Exllamaモデルのsuart。Real-time 、双方向通信、およびその他のLLMモデル。RedisとLangchainを使用して、類似性検索のためにベクトル埋め込みを保存および取得します。 AIがより関連性の高い応答を生成するのに役立ちます。Duckduckgo検索エンジンを使用して、Webを閲覧して関連する情報を見つけます。async / await syntaxを使用した非同期プログラミング。MySQLクエリを実行します。 sqlalchemy.asyncioを使用して、アクションを作成、読み取り、更新、削除することを簡単に実行します。Redisクエリを実行します。 aioredisを使用して、アクションを作成、読み取り、更新、削除することを簡単に実行できます。 ローカルマシンにセットアップするには、これらの簡単な手順に従ってください。開始する前に、マシンにdockerとdocker-composeインストールされていることを確認してください。 Dockerなしでサーバーを実行する場合は、 Python 3.11追加でインストールする必要があります。ただし、DBサーバーを実行するにはDockerが必要です。
Exllamaまたはllama.cppモデルを使用するようにサブモジュールを再帰的にクローンするには、次のコマンドを使用します。
git clone --recurse-submodules https://github.com/c0sogi/llmchat.gitコア機能(openai)のみを使用する必要があります。次のコマンドを使用します。
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.envファイル.env-sampleファイルを参照して、envファイルをセットアップします。データベース情報を入力して、OpenAI APIキー、およびその他の必要な構成を作成します。オプションは必須ではありません。そのままにしておくだけです。
これらを実行します。サーバーを初めて起動するには数分かかる場合があります。
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml downこれで、 http://localhost:8000/docsでサーバーにアクセスし、 db:3306またはcache:6379のデータベースにアクセスできます。またhttp://localhost:8000/chatでアプリにアクセスすることもできます。
Dockerなしでサーバーを実行するには、 Dockerなしでサーバーを実行する場合は、 Python 3.11をさらにインストールする必要があります。ただし、DBサーバーを実行するにはDockerが必要です。 docker-compose -f docker-compose-local.yaml down apiで既に実行されているAPIサーバーをオフにします。 Dockerで他のDBサーバーを実行することを忘れないでください!次に、次のコマンドを実行します。
python -m mainこの場合、サーバーはhttp://localhost:8001で稼働している必要があります。
このプロジェクトは、元の著作権およびライセンス通知がソフトウェアのコピーまたはかなりの部分に含まれている限り、MITライセンスの下でライセンスされています。
FastAPI 、PythonでAPIを構築するための最新のWebフレームワークです。 ?パフォーマンスが高く、学習しやすく、コーディングが速く、生産の準備が整っています。 ? FastAPIの主な特徴の1つは、同時性とasync / await Syntaxをサポートすることです。 ?これは、特にネットワークリクエスト、データベースクエリ、ファイル操作など、I/Oバインド操作を扱う場合、互いにブロックすることなく複数のタスクを同時に処理できるコードを記述できることを意味します。
Flutter 、単一のコードベースからモバイル、Web、デスクトッププラットフォーム用のネイティブユーザーインターフェイスを構築するためにGoogleが開発したオープンソースUIツールキットです。 ?は、最新のオブジェクト指向プログラミング言語であるDartを使用し、あらゆるデザインに適応できるカスタマイズ可能なウィジェットの豊富なセットを提供します。
app/routers/websocketとapp/utils/chat/chat_stream_manager 2つのモジュールを使用して、 WebSocket Connectionを介してChatGPTまたはLlamaCppにアクセスできます。これらのモジュールは、WebSocketを介してFlutterクライアントとチャットモデル間の通信を容易にします。 WebSocketを使用すると、LLMと対話するためにリアルタイムの双方向通信チャネルを確立できます。
会話を開始するには、データベースに登録されている有効なAPIキーを使用して、WebSocket Route /ws/chat/{api_key}に接続します。このAPIキーはOpenai APIキーと同じではなく、サーバーがユーザーを検証するためにのみ利用可能であることに注意してください。接続したら、メッセージとコマンドを送信してLLMモデルと対話できます。 WebSocketは、チャット応答をリアルタイムで送信します。このWebSocket接続は、EndPoint /chatでアクセスできるFlutterアプリを介して確立されます。
websocket.pyは、WebSocket接続の設定とユーザー認証の処理を担当します。 WebSocket Route /chat/{api_key}を定義し、WebSocketとAPIキーをパラメーターとして受け入れます。
クライアントがWebSocketに接続すると、最初にAPIキーをチェックしてユーザーを認証します。 APIキーが有効な場合、 begin_chat()関数はstream_manager.pyモジュールから呼び出され、会話を開始します。
未登録のAPIキーまたは予期しないエラーの場合、適切なメッセージがクライアントに送信され、接続が閉じられます。
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.pyは、会話の管理とユーザーメッセージの処理を担当します。 WebSocket、ユーザーIDをパラメーターとして使用するbegin_chat()関数を定義します。
この関数は、最初にキャッシュマネージャーからのユーザーのチャットコンテキストを初期化します。次に、WebSocketを介して最初のメッセージ履歴をクライアントに送信します。
接続が閉じるまで、会話はループで続きます。会話中、ユーザーのメッセージが処理され、GPTの応答がそれに応じて生成されます。
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
...SendToWebsocketクラスは、WebSocketにメッセージとストリームを送信するために使用されます。 message()とstream() 2つの方法があります。 message()メソッドは完全なメッセージをWebSocketに送信し、 stream()メソッドはWebSocketにストリームを送信します。
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
...MessageHandlerクラスは、AI応答も処理します。 ai()メソッドは、WebSocketにAI応答を送信します。翻訳が有効になっている場合、クライアントに送信する前に、Google Translate APIを使用して応答が翻訳されます。
class MessageHandler :
...
@ staticmethod
async def ai (...):
...ユーザーメッセージは、 HandleMessageクラスを使用して処理されます。メッセージが/YOUR_CALLBACK_NAMEなどの/で始まる場合。それはコマンドとして扱われ、適切なコマンド応答が生成されます。それ以外の場合、ユーザーのメッセージが処理され、応答を生成するためにLLMモデルに送信されます。
コマンドは、 ChatCommandsクラスを使用して処理されます。コマンドに応じて、対応するコールバック関数を実行します。 app.utils.chat.chat_commandsからChatCommandsクラスにコールバックを追加するだけで、新しいコマンドを追加できます。
レディスを使用して会話のベクトル埋め込みを保存しますか?〜chatgptモデルを支援できますか?会話のコンテキストの効率的かつ迅速な検索など、いくつかの点で、大量のデータを処理し、ベクターの類似性検索を通じてより関連性の高い応答を提供しますか?
これが実際にどのように機能するかのいくつかの楽しい例:
/embedコマンドを使用してテキストを埋め込みますユーザーがチャットウィンドウのようにコマンドを入力すると、 /embed <text_to_embed>ように、 VectorStoreManager.create_documentsメソッドが呼び出されます。このメソッドは、OpenAIのtext-embedding-ada-002モデルを使用して入力テキストをベクトルに変換し、Redis VectorStoreに保存します。
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../queryコマンドを使用して組み込みデータをクエリしますユーザーが/query <query>コマンドを入力すると、 asimilarity_search関数を使用して、redis vectorstoreの埋め込みデータと最高のベクトルの類似性を持つ最大3つの結果を見つけます。これらの結果は、チャットのコンテキストに一時的に保存されているため、AIはこれらのデータを参照してクエリに答えるのに役立ちます。
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
...begin_chat関数を実行すると、ユーザーがテキストを含むファイル(PDFまたはTXTファイルなど)をアップロードすると、テキストがファイルから自動的に抽出され、そのベクトル埋め込みがRedisに保存されます。
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py commands.pyファイルには、いくつかの重要なコンポーネントがあります。
command_response :このクラスは、次のアクションを指定するコマンドメソッドのデコレーターを設定するために使用されます。メッセージの送信や停止、メッセージの送信、継続、ユーザー入力の処理、AI応答の処理など、さまざまな応答タイプを定義するのに役立ちます。command_handler :この関数は、ユーザーが入力したテキストに基づいてコマンドコールバックメソッドを実行する責任があります。arguments_provider :この関数は、コマンドメソッドの注釈タイプに基づいてコマンドメソッドで必要な引数を自動的に提供します。タスクトリガー:この機能は、ユーザーがメッセージを入力するか、AIがメッセージで応答するたびにアクティブになります。この時点で、テキストコンテンツを凝縮するために自動要約タスクが生成されます。
タスクストレージ:自動腫瘍タスクは、 BufferUserChatContextのtask_list属性に保存されます。これは、ユーザーのチャットコンテキストにリンクされたタスクを管理するためのキューとして機能します。
タスクの収穫: MessageHandlerによるユーザーの質問と回答サイクルの完了後、 harvest_done_tasks関数が呼び出されます。この関数は、要約タスクの結果を収集し、何も除外されていないことを確認します。
要約アプリケーション:収穫プロセスの後、ChatbotがOpenaiやLlama_cppなどの言語学習モデル(LLM)から回答を要求しているときに、要約された結果は実際のメッセージを置き換えます。そうすることで、最初の長いメッセージよりもはるかに簡潔なプロンプトを送信することができます。
ユーザーエクスペリエンス:重要なことに、ユーザーの観点からは、元のメッセージのみが表示されます。メッセージの要約バージョンは彼らには表示されず、透明性を維持し、潜在的な混乱を回避します。
同時タスク:この自動腫瘍化タスクのもう1つの重要な機能は、他のタスクを妨げないことです。言い換えれば、チャットボットはテキストを要約するのに忙しい間、他のタスクを実行することができ、それによりチャットボットの全体的な効率を改善します。
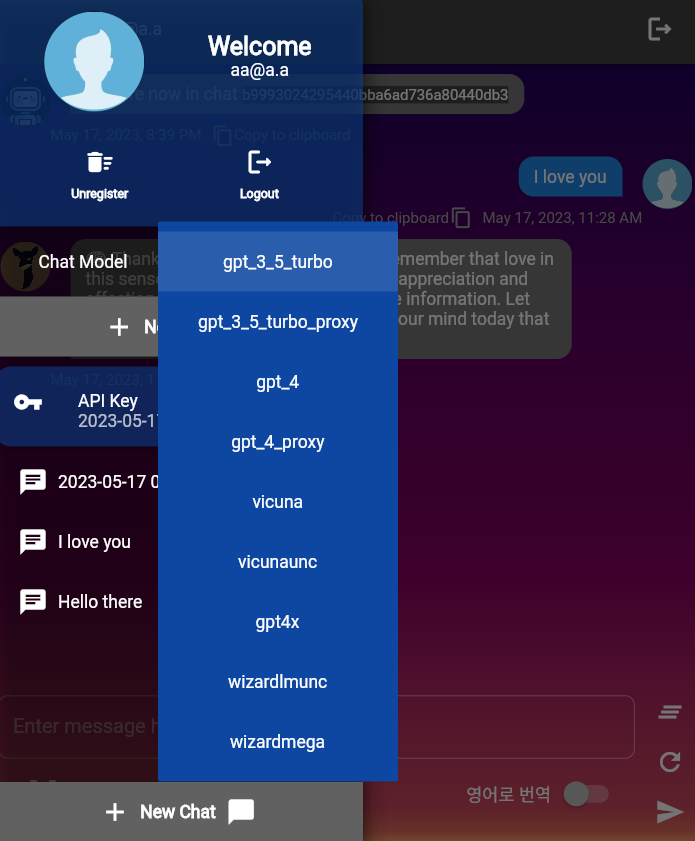
ChatConfigでしきい値を設定できます。このリポジトリには、 llms.pyで定義されたさまざまなLLMモデルが含まれています。各LLMモデルクラスは、基本クラスのLLMModelから継承されます。 LLMModels enumは、これらのLLMのコレクションです。
すべての操作は、メインスレッドを挿入することなく非同期に処理されます。ただし、ローカルLLMは、計算上高すぎるため、複数のリクエストを同時に処理することはできません。したがって、 Semaphore 、リクエストの数を1に制限するために使用されます。
ユーザーがUserChatContext.construct_defaultを介してユーザーが使用するデフォルトのLLMモデルはgpt-3.5-turboです。その機能のデフォルトを変更できます。
OpenAIModel 、OpenAIサーバーからチャットの完了を要求することにより、テキストを非同期に生成します。 Openai APIキーが必要です。
LlamaCppModel 、ローカルに保存されているGGMLモデルを読み取ります。 llama.cpp ggmlモデルは、 .binファイルとしてllama_models/ggmlフォルダーに配置する必要があります。たとえば、「https://huggingface.co/thebloke/robin-7b-v2-ggml」からQ4_0 Quantizedモデルをダウンロードした場合、モデルのパスは「robin-7b.ggmlv3.q4_0.bin」でなければなりません。
ExllamaModelローカルに保存されているGPTQモデルを読みます。 Exllama GPTQモデルは、フォルダーとしてllama_models/gptqフォルダーに配置する必要があります。たとえば、「https://huggingface.co/thebloke/orca_mini_7b-gptq/tree/main」から3つのファイルをダウンロードした場合:
その後、それらをフォルダーに入れる必要があります。モデルのパスはフォルダー名でなければなりません。 3つのファイルを含む「orca_mini_7b」としましょう。
テキスト生成中に発生する可能性のある例外を処理します。 ChatLengthExceptionがスローされた場合、 cutoff_message_histories関数によって制限されているトークンの数にメッセージを再結合するためのルーチンを自動的に実行し、再送信します。これにより、トークンの制限に関係なく、ユーザーがスムーズなチャットエクスペリエンスをすることが保証されます。
このプロジェクトは、大規模な言語モデルチャットボットサービスを有効にするためのAPIバックエンドを作成することを目的としています。キャッシュマネージャーを使用して、Redisにメッセージとユーザープロファイルを保存し、メッセージマネージャーを安全にキャッシュするためにメッセージマネージャーを保存して、トークンの数が許容できる制限を超えないようにします。
キャッシュマネージャー( CacheManager )は、ユーザーのコンテキスト情報とメッセージ履歴の処理を担当しています。これらのデータをRedisに保存し、簡単に検索と変更を可能にします。マネージャーは、次のようなキャッシュと対話するためのいくつかの方法を提供します。
read_context_from_profile :ユーザーのプロフィールに従って、redisからユーザーのチャットコンテキストを読み取ります。create_context :redisで新しいユーザーチャットコンテキストを作成します。reset_context :ユーザーのチャットコンテキストをデフォルト値にリセットします。update_message_histories :特定の役割(ユーザー、AI、またはシステム)のメッセージ履歴を更新します。lpop_message_history / rpop_message_history :リストの左端または右端からメッセージ履歴を削除して返します。append_message_history :リストの最後にメッセージ履歴を追加します。get_message_history :特定の役割についてメッセージ履歴を取得します。delete_message_history :特定の役割のメッセージ履歴を削除します。set_message_history :役割とインデックスに特定のメッセージ履歴を設定します。 メッセージマネージャー( MessageManager )は、メッセージ履歴のトークンの数が指定された制限を超えないことを保証します。トークンの制限を維持しながら、ユーザーのチャットコンテキストでメッセージ履歴の追加、削除、設定を安全に処理します。マネージャーは、次のようなメッセージ履歴と対話するためのいくつかの方法を提供します。
add_message_history_safely :ユーザーのチャットコンテキストにメッセージ履歴を追加し、トークン制限を超えないようにします。pop_message_history_safely :トークンカウントを更新しながら、リストの右端からメッセージ履歴を削除して返します。set_message_history_safely :ユーザーのチャットコンテキストで特定のメッセージ履歴を設定し、トークンカウントを更新し、トークン制限を超えないようにします。 プロジェクトでキャッシュマネージャーとメッセージマネージャーを使用するには、次のようにインポートします。
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManager次に、メソッドを使用して、Redisキャッシュと対話し、要件に応じてメッセージ履歴を管理できます。
たとえば、新しいユーザーチャットコンテキストを作成するには:
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )ユーザーのチャットコンテキストにメッセージ履歴を安全に追加するには:
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role )このプロジェクトでは、FastAPIアプリケーションで使用されるtoken_validatorミドルウェアやその他のミドルウェアを使用しています。これらのミドルウェアは、APIへのアクセスを制御する責任があり、許可され、認証されたリクエストのみが処理されるようにします。
次のMiddlewaresがFastapiアプリケーションに追加されます。
アクセス制御ミドルウェアは、 token_validator.pyファイルで定義されています。 APIキーとJWTトークンの検証を担当しています。
StateManagerクラスは、要求状態変数の初期化に使用されます。リクエスト時間、開始時間、IPアドレス、およびユーザートークンを設定します。
AccessControlクラスには、APIキーとJWTトークンを検証するための2つの静的な方法が含まれています。
api_service :リクエスト内の必要なクエリパラメーターとヘッダーの存在をチェックすることにより、APIキーを検証します。 APIキー、シークレット、およびタイムスタンプを検証するために、 Validator.api_keyメソッドを呼び出します。non_api_service :リクエストで「承認」ヘッダーまたは「承認」Cookieの存在をチェックすることにより、JWTトークンを検証します。 JWTトークンをデコードして検証するために、 Validator.jwtメソッドを呼び出します。 Validatorクラスには、APIキーとJWTトークンを検証するための2つの静的な方法が含まれています。
api_key :APIアクセスキー、ハッシュシークレット、およびタイムスタンプを検証します。検証が成功した場合、 UserTokenオブジェクトを返します。jwt :JWTトークンをデコードして検証します。検証が成功した場合、 UserTokenオブジェクトを返します。 access_control関数は、ミドルウェアのリクエストと応答フローを処理する非同期関数です。 StateManagerクラスを使用して要求状態を初期化し、要求されたURL(APIキーまたはJWTトークン)に必要な認証のタイプを決定し、 AccessControlクラスを使用して認証を検証します。検証プロセス中にエラーが発生した場合、適切なHTTP例外が発生します。
トークンユーティリティは、 token.pyファイルで定義されています。 2つの関数が含まれています。
create_access_token :指定されたデータと有効期限を備えたJWTトークンを作成します。token_decode :JWTトークンをデコードして検証します。トークンの有効期限が切れているか、デコードできない場合は例外を提起します。params_utils.pyファイルには、HMACとSHA256を使用して、クエリパラメーターをハッシュするためのユーティリティ関数とシークレットキーが含まれています。
hash_params :クエリパラメーターとシークレットキーを入力として取得し、base64エンコードされたハッシュ文字列を返します。date_utils.pyファイルには、日付とタイムスタンプを操作するためのユーティリティ関数を備えたUTCクラスが含まれています。
now :現在のUTCデータタイムをオプションの時間差で返します。timestamp :オプションの時間差で現在のUTCタイムスタンプを返します。timestamp_to_datetime :オプションの時間差でタイムスタンプをDateTimeオブジェクトに変換します。logger.pyファイルには、APIリクエストと応答情報を記録するApiLoggerクラスが含まれています。ロガー関数は、 access_control関数の最後に呼び出され、処理された要求と応答をログにします。
FastAPIアプリケーションでtoken_validatorミドルウェアを使用するには、 access_control関数をインポートして、FastAPIインスタンスにミドルウェアとして追加するだけです。
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )完全なアクセス制御のために、CORSと信頼できるホストMiddleWaresも追加してください。
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
)これで、FastAPIアプリケーションへの着信リクエストは、 token_validatorミドルウェアおよびその他のミドルウェアによって処理され、承認された認証されたリクエストのみが処理されるようにします。
このモジュールapp.database.connection 、データベース接続を管理し、sqlalchemyとredisを使用してSQLクエリを実行するための使いやすいインターフェイスを提供します。 MySQLをサポートし、このプロジェクトと簡単に統合できます。
まず、必要なクラスをモジュールからインポートします。
from app . database . connection import MySQL , SQLAlchemy , CacheFactory次に、 SQLAlchemyクラスのインスタンスを作成し、データベース設定で構成します。
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config )これで、 dbインスタンスを使用してSQLクエリを実行してセッションを管理できます。
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" ) Redisキャッシュを使用するには、 CacheFactoryクラスのインスタンスを作成し、Redis設定で構成します。
cache = CacheFactory ()
cache . start ( config )これで、 cacheインスタンスを使用してRedisと対話できます。
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" )実際、このプロジェクトでは、 MySQLクラスがアプリ起動時に初期セットアップを行い、すべてのデータベース接続はモジュールの最後に存在するdbとcache変数のみを使用して作成されます。 ?
すべてのDB設定は、 app.common.app_settingsのcreate_app()で行われます。たとえば、 app.common.app_settingsのcreate_app()関数は次のようになります。
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_appこのプロジェクトでは、SQLalchemyと2つのモジュールとパスを使用して、データベースCRUD(作成、読み取り、更新、削除)操作を処理するためのシンプルで効率的な方法を使用しますapp.database.models.schemaおよびapp.database.crud 。
schema.pyモジュールは、SQLalchemyを使用してデータベースモデルとその関係を定義する責任があります。 Baseから継承する一連のクラス、 declarative_base()のインスタンスが含まれます。各クラスはデータベース内のテーブルを表し、その属性はテーブル内の列を表します。これらのクラスは、すべてのモデルにいくつかの一般的な方法と属性を提供するMixinクラスからも継承します。
Mixinクラスは、そこから継承するすべてのクラスにいくつかの一般的な属性と方法を提供します。属性には次のものが含まれます。
id :テーブルの整数プライマリキー。created_at :レコードが作成されたときのdateTime。updated_at :レコードが最後に更新されたときのdateTime。ip_address :レコードを作成または更新したクライアントのIPアドレス。また、次のようなSQLalchemyを使用してCRUD操作を実行するいくつかのクラスの方法も提供します。
add_all() :データベースに複数のレコードを追加します。add_one() :データベースに単一のレコードを追加します。update_where() :フィルターに基づいてデータベース内のレコードを更新します。fetchall_filtered_by() :提供されたフィルターに一致するデータベースからすべてのレコードを取得します。one_filtered_by() :提供されたフィルターに一致するデータベースから単一のレコードを取得します。first_filtered_by() :提供されたフィルターに一致するデータベースから最初のレコードを取得します。one_or_none_filtered_by() :提供されたフィルターと一致しない場合、単一のレコードを取得するか、返品None返します。 users.pyおよびapi_keys.pyモジュールには、 schema.pyで定義されたクラスを使用してCRUD操作を実行する一連の関数が含まれています。これらの関数は、Mixinクラスが提供するクラスメソッドを使用して、データベースと対話します。
このモジュールの関数の一部は次のとおりです。
create_api_key() :ユーザーに新しいAPIキーを作成します。get_api_keys() :ユーザーのすべてのAPIキーを取得します。get_api_key_owner() :APIキーの所有者を取得します。get_api_key_and_owner() :APIキーとその所有者を取得します。update_api_key() :APIキーを更新します。delete_api_key() :APIキーを削除します。is_email_exist() :データベースにメールが存在するかどうかを確認します。get_me() :ユーザーIDに基づいてユーザー情報を取得します。is_valid_api_key() :APIキーが有効かどうかを確認します。register_new_user() :データベースに新しいユーザーを登録します。find_matched_user() :データベースに一致する電子メールがあるユーザーを見つけます。 提供されたCRUD操作を使用するには、 crud.pyモジュールから関連する関数をインポートし、必要なパラメーターでそれらを呼び出します。例えば:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())