LLMChat
v1.1.3.4.1
ยินดีต้อนรับสู่ที่เก็บ LLMCHAT การใช้งานเต็มรูปแบบของเซิร์ฟเวอร์ API ที่สร้างขึ้นด้วย Python Fastapi และส่วนหน้าสวยงามขับเคลื่อนโดย Flutter โครงการนี้ได้รับการออกแบบมาเพื่อมอบประสบการณ์การแชทที่ไร้รอยต่อด้วย Advanced ChatGPT และรุ่น LLM อื่น ๆ - นำเสนอโครงสร้างพื้นฐานที่ทันสมัยซึ่งสามารถขยายได้อย่างง่ายดายเมื่อมีคุณสมบัติหลายรูปแบบและปลั๊กอินของ GPT-4 เพลิดเพลินกับการเข้าพัก!
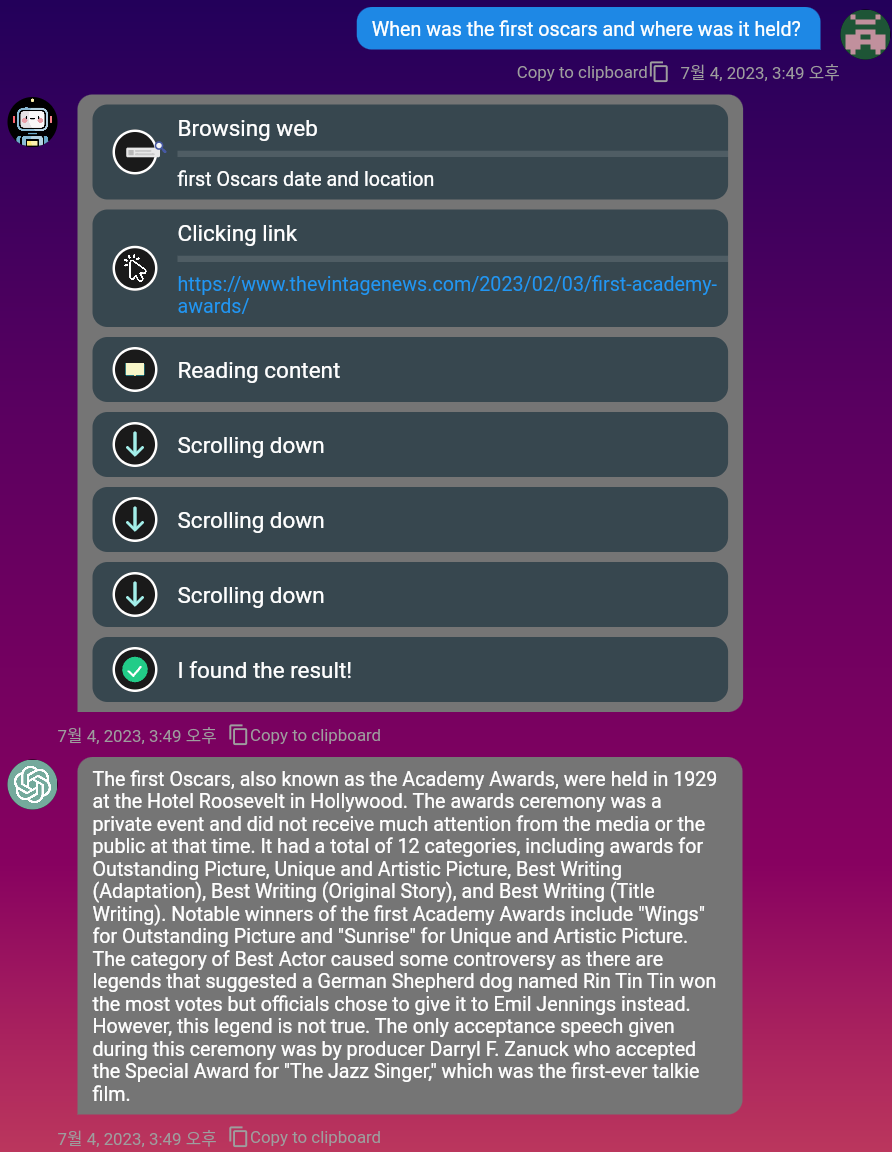
mobile และ PCMarkdown เพื่อให้คุณสามารถใช้เพื่อจัดรูปแบบข้อความของคุณคุณสามารถใช้เครื่องมือค้นหา Duckduckgo เพื่อค้นหาข้อมูลที่เกี่ยวข้องบนเว็บ เพียงเปิดใช้งานปุ่มสลับ 'เรียกดู'!
ดูวิดีโอตัวอย่างสำหรับการท่องเต็มรูปแบบ: https://www.youtube.com/watch?v=MJ_CVRWRS08
ด้วยคำสั่ง /embed คุณสามารถจัดเก็บข้อความได้อย่างไม่มีกำหนดในฐานข้อมูลเวกเตอร์ส่วนตัวของคุณเองและสอบถามในภายหลังได้ทุกเวลา หากคุณใช้คำสั่ง /share ข้อความจะถูกเก็บไว้ในฐานข้อมูลเวกเตอร์สาธารณะที่ทุกคนสามารถแบ่งปันได้ การเปิดใช้งานปุ่มสลับ Query หรือคำสั่ง /query ช่วยให้ AI สร้างคำตอบตามบริบทโดยการค้นหาข้อความที่คล้ายคลึงกันในฐานข้อมูลสาธารณะและส่วนตัว สิ่งนี้จะแก้ปัญหาข้อ จำกัด ที่ใหญ่ที่สุดอย่างหนึ่งของแบบจำลองภาษา: หน่วยความจำ
คุณสามารถฝังไฟล์ PDF ได้โดยคลิก Embed Document ที่ด้านล่างซ้าย ในไม่กี่วินาทีเนื้อหาข้อความของ PDF จะถูกแปลงเป็นเวกเตอร์และฝังเป็นแคช Redis
LLMModels ซึ่งอยู่ใน app/models/llms.py สำหรับ LLALAM LLMS ในท้องถิ่นจะถือว่าทำงานเฉพาะในสภาพแวดล้อมท้องถิ่นและใช้ http://localhost:8002/v1/completions มันตรวจสอบสถานะของเซิร์ฟเวอร์ LLAMA API อย่างต่อเนื่องโดยการเชื่อมต่อกับ http://localhost:8002/health หนึ่งครั้งที่สองเพื่อดูว่าการตอบกลับ 200 OK ถูกส่งคืนหรือไม่และถ้าไม่ใช่จะเรียกใช้กระบวนการแยกต่างหากโดยอัตโนมัติเพื่อสร้างเซิร์ฟเวอร์ API
เป้าหมายหลักของ LLAMA.CPP คือการเรียกใช้โมเดล LLAMA โดยใช้ GGML 4-bit quantization ด้วยการใช้งาน C/C ++ ธรรมดาโดยไม่ต้องพึ่งพา คุณต้องดาวน์โหลดไฟล์ ggml bin จาก HuggingFace และวางไว้ในโฟลเดอร์ llama_models/ggml และกำหนด LLMMODEL ใน app/models/llms.py มีตัวอย่างน้อยดังนั้นคุณสามารถกำหนดโมเดลของคุณเองได้อย่างง่ายดาย อ้างถึงพื้นที่เก็บข้อมูล llama.cpp สำหรับข้อมูลเพิ่มเติม: https://github.com/ggerganov/llama.cpp
การใช้ LLAMA แบบสแตนด์อโลน/C ++/CUDA สำหรับใช้กับน้ำหนัก GPTQ 4 บิตออกแบบให้เร็วและมีประสิทธิภาพในการใช้หน่วยความจำใน GPU ที่ทันสมัย มันใช้ pytorch และ sentencepiece เพื่อเรียกใช้โมเดล สันนิษฐานว่าทำงานเฉพาะในสภาพแวดล้อมท้องถิ่นและอย่างน้อยหนึ่ง NVIDIA CUDA GPU เป็นสิ่งจำเป็น คุณต้องดาวน์โหลดไฟล์ tokenizer, config และ gptq จาก HuggingFace และใส่ไว้ในโฟลเดอร์ llama_models/gptq/YOUR_MODEL_FOLDER และกำหนด llmmodel ใน app/models/llms.py มีตัวอย่างน้อยดังนั้นคุณสามารถกำหนดโมเดลของคุณเองได้อย่างง่ายดาย อ้างถึงที่เก็บ exllama สำหรับข้อมูลรายละเอียดเพิ่มเติม: https://github.com/turboderp/exllama
web framework ประสิทธิภาพสูงสำหรับการสร้าง API ด้วย PythonWebapp Frontend ด้วย UI ที่สวยงามและชุดวิดเจ็ตที่ปรับแต่งได้OpenAI API สำหรับการสร้างข้อความและการจัดการข้อความLlamaCpp และ Exllama ModelsReal-time สองทางกับ CHATGPT และรุ่น LLM อื่น ๆ พร้อม Flutter Frontend WebAppRedis และ Langchain จัดเก็บและดึงการฝังเวกเตอร์สำหรับการค้นหาที่คล้ายคลึงกัน มันจะช่วย AI ในการสร้างคำตอบที่เกี่ยวข้องมากขึ้นDuckduckgo เรียกดูเว็บและค้นหาข้อมูลที่เกี่ยวข้องasync / await Syntax สำหรับการเกิดขึ้นพร้อมกันและการขนานMySQL ดำเนินการสร้างสร้างอ่านอัปเดตและลบการกระทำได้อย่างง่ายดายด้วย sqlalchemy.asyncioRedis ด้วย Aioredis ดำเนินการสร้างสร้างอ่านอัปเดตและลบการกระทำด้วย aioredis ได้อย่างง่ายดาย ในการตั้งค่าบนเครื่องในพื้นที่ของคุณให้ทำตามขั้นตอนง่ายๆเหล่านี้ ก่อนที่คุณจะเริ่มตรวจสอบให้แน่ใจว่าคุณติดตั้ง docker และ docker-compose บนเครื่องของคุณ หากคุณต้องการเรียกใช้เซิร์ฟเวอร์โดยไม่มี Docker คุณต้องติดตั้ง Python 3.11 เพิ่มเติม แม้ว่าคุณจะต้องใช้ Docker เพื่อเรียกใช้เซิร์ฟเวอร์ DB
หากต้องการโคลน submodules ซ้ำเพื่อใช้รุ่น Exllama หรือ llama.cpp ใช้คำสั่งต่อไปนี้:
git clone --recurse-submodules https://github.com/c0sogi/llmchat.gitคุณต้องการใช้คุณสมบัติหลัก (openai) ใช้คำสั่งต่อไปนี้:
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.env ตั้งค่าไฟล์ env โดยอ้างถึงไฟล์ .env-sample ป้อนข้อมูลฐานข้อมูลเพื่อสร้างคีย์ OpenAI API และการกำหนดค่าที่จำเป็นอื่น ๆ ตัวเลือกไม่จำเป็นต้องปล่อยให้พวกเขาเหมือนพวกเขา
ดำเนินการเหล่านี้ อาจใช้เวลาไม่กี่นาทีในการเริ่มต้นเซิร์ฟเวอร์เป็นครั้งแรก:
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml down ตอนนี้คุณสามารถเข้าถึงเซิร์ฟเวอร์ได้ที่ http://localhost:8000/docs และฐานข้อมูลที่ db:3306 หรือ cache:6379 นอกจากนี้คุณยังสามารถเข้าถึงแอพได้ที่ http://localhost:8000/chat
ในการเรียกใช้เซิร์ฟเวอร์โดยไม่ต้อง Docker หากคุณต้องการเรียกใช้เซิร์ฟเวอร์โดยไม่ต้อง Docker คุณต้องติดตั้ง Python 3.11 เพิ่มเติม แม้ว่าคุณจะต้องใช้ Docker เพื่อเรียกใช้เซิร์ฟเวอร์ DB ปิดเซิร์ฟเวอร์ API ที่ทำงานอยู่แล้วด้วย docker-compose -f docker-compose-local.yaml down api อย่าลืมเรียกใช้เซิร์ฟเวอร์ DB อื่น ๆ บน Docker! จากนั้นเรียกใช้คำสั่งต่อไปนี้:
python -m main เซิร์ฟเวอร์ของคุณควรเปิดใช้งานบน http://localhost:8001 ในกรณีนี้
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต MIT ซึ่งอนุญาตให้ใช้งานฟรีการดัดแปลงและการแจกจ่ายตราบใดที่ลิขสิทธิ์ดั้งเดิมและใบอนุญาตมีการแจ้งให้ทราบล่วงหน้าในสำเนาหรือส่วนสำคัญของซอฟต์แวร์
FastAPI เป็นกรอบเว็บที่ทันสมัยสำหรับการสร้าง API ด้วย Python - มันมีประสิทธิภาพสูงเรียนรู้ได้ง่ายเขียนโค้ดและพร้อมสำหรับการผลิต - หนึ่งในคุณสมบัติหลักของ FastAPI คือรองรับการเกิดขึ้นพร้อมกันและ async / await ไวยากรณ์ - ซึ่งหมายความว่าคุณสามารถเขียนโค้ดที่สามารถจัดการงานได้หลายงานในเวลาเดียวกันโดยไม่ต้องปิดกั้นซึ่งกันและกันโดยเฉพาะอย่างยิ่งเมื่อจัดการกับการดำเนินการที่ถูกผูกไว้ I/O เช่นคำขอเครือข่ายการสืบค้นฐานข้อมูลการดำเนินการไฟล์ ฯลฯ
Flutter เป็นชุดเครื่องมือ UI แบบโอเพ่นซอร์สที่พัฒนาโดย Google สำหรับการสร้างอินเทอร์เฟซผู้ใช้ดั้งเดิมสำหรับแพลตฟอร์มมือถือเว็บและเดสก์ท็อปจากรหัสฐานเดียว ? ใช้ Dart เป็นภาษาการเขียนโปรแกรมเชิงวัตถุที่ทันสมัยและให้ชุดวิดเจ็ตที่ปรับแต่งได้ซึ่งสามารถปรับให้เข้ากับการออกแบบใด ๆ
คุณสามารถเข้าถึง ChatGPT หรือ LlamaCpp ผ่านการเชื่อมต่อ WebSocket โดยใช้สองโมดูล: app/routers/websocket และ app/utils/chat/chat_stream_manager โมดูลเหล่านี้อำนวยความสะดวกในการสื่อสารระหว่างไคลเอนต์ Flutter และโมเดลแชทผ่าน WebSocket ด้วย WebSocket คุณสามารถสร้างช่องทางการสื่อสารแบบเรียลไทม์สองทางเพื่อโต้ตอบกับ LLM
ในการเริ่มต้นการสนทนาให้เชื่อมต่อกับเส้นทาง WebSocket /ws/chat/{api_key} ด้วยคีย์ API ที่ถูกต้องที่ลงทะเบียนในฐานข้อมูล โปรดทราบว่าคีย์ API นี้ไม่เหมือนกับคีย์ OpenAI API แต่มีให้สำหรับเซิร์ฟเวอร์ของคุณเท่านั้นที่จะตรวจสอบความถูกต้องของผู้ใช้ เมื่อเชื่อมต่อแล้วคุณสามารถส่งข้อความและคำสั่งเพื่อโต้ตอบกับโมเดล LLM WebSocket จะส่งคำตอบการแชทกลับแบบเรียลไทม์ การเชื่อมต่อ WebSocket นี้ถูกสร้างขึ้นผ่านแอป Flutter ซึ่งสามารถเข้าถึงได้ด้วย Endpoint /chat
websocket.py รับผิดชอบในการตั้งค่าการเชื่อมต่อ WebSocket และจัดการการตรวจสอบผู้ใช้ มันกำหนดเส้นทาง WebSocket /chat/{api_key} ที่ยอมรับ WebSocket และคีย์ API เป็นพารามิเตอร์
เมื่อไคลเอนต์เชื่อมต่อกับ WebSocket ให้ตรวจสอบคีย์ API ก่อนเพื่อตรวจสอบสิทธิ์ผู้ใช้ หากคีย์ API นั้นถูกต้องฟังก์ชั่น begin_chat() จะถูกเรียกจากโมดูล stream_manager.py เพื่อเริ่มการสนทนา
ในกรณีที่คีย์ API ที่ไม่ได้ลงทะเบียนหรือข้อผิดพลาดที่ไม่คาดคิดข้อความที่เหมาะสมจะถูกส่งไปยังไคลเอนต์และการเชื่อมต่อจะปิด
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.py รับผิดชอบในการจัดการการสนทนาและการจัดการข้อความผู้ใช้ มันกำหนดฟังก์ชั่น begin_chat() ซึ่งใช้ WebSocket รหัสผู้ใช้เป็นพารามิเตอร์
ฟังก์ชั่นแรกเริ่มต้นบริบทการแชทของผู้ใช้จาก Cache Manager จากนั้นจะส่งประวัติข้อความเริ่มต้นไปยังลูกค้าผ่าน WebSocket
บทสนทนาจะดำเนินต่อไปในลูปจนกว่าการเชื่อมต่อจะปิด ในระหว่างการสนทนาข้อความของผู้ใช้จะถูกประมวลผลและการตอบสนองของ GPT จะถูกสร้างขึ้นตามนั้น
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
... คลาส SendToWebsocket ใช้สำหรับการส่งข้อความและสตรีมไปยัง WebSocket มันมีสองวิธี: message() และ stream() เมธอด message() ส่งข้อความที่สมบูรณ์ไปยัง WebSocket ในขณะที่วิธี stream() ส่งสตรีมไปยัง WebSocket
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
... คลาส MessageHandler ยังจัดการกับการตอบสนอง AI วิธี ai() ส่งการตอบสนอง AI ไปยัง WebSocket หากเปิดใช้งานการแปลการตอบกลับจะถูกแปลโดยใช้ Google Translate API ก่อนที่จะส่งไปยังไคลเอนต์
class MessageHandler :
...
@ staticmethod
async def ai (...):
... ข้อความผู้ใช้ถูกประมวลผลโดยใช้คลาส HandleMessage หากข้อความเริ่มต้นด้วย / เช่น /YOUR_CALLBACK_NAME มันได้รับการปฏิบัติเป็นคำสั่งและการตอบสนองคำสั่งที่เหมาะสมถูกสร้างขึ้น มิฉะนั้นข้อความของผู้ใช้จะถูกประมวลผลและส่งไปยังโมเดล LLM เพื่อสร้างการตอบกลับ
คำสั่งได้รับการจัดการโดยใช้คลาส ChatCommands มันดำเนินการฟังก์ชันการโทรกลับที่สอดคล้องกันขึ้นอยู่กับคำสั่ง คุณสามารถเพิ่มคำสั่งใหม่ได้โดยเพียงแค่เพิ่มการโทรกลับในคลาส ChatCommands จาก app.utils.chat.chat_commands
การใช้ Redis สำหรับการจัดเก็บการฝังตัวของเวกเตอร์การสนทนา️สามารถช่วยโมเดล chatgpt ได้หรือไม่? ในหลายวิธีเช่นการดึงบริบทการสนทนาที่มีประสิทธิภาพและรวดเร็วและการจัดการข้อมูลจำนวนมากและให้การตอบสนองที่เกี่ยวข้องมากขึ้นผ่านการค้นหาความคล้ายคลึงกันของเวกเตอร์
ตัวอย่างสนุก ๆ ว่าสิ่งนี้สามารถทำงานในทางปฏิบัติได้อย่างไร:
/embed เมื่อผู้ใช้ป้อนคำสั่งในหน้าต่างแชทเช่น /embed <text_to_embed> วิธีการ VectorStoreManager.create_documents เรียกว่า วิธีนี้จะแปลงข้อความอินพุตเป็นเวกเตอร์โดยใช้โมเดล text-embedding-ada-002 และเก็บไว้ใน Redis Vectorstore
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../query เมื่อผู้ใช้ป้อนคำสั่ง /query <query> ฟังก์ชัน asimilarity_search จะใช้เพื่อค้นหาผลลัพธ์สูงสุดสามผลลัพธ์ที่มีความคล้ายคลึงกันของเวกเตอร์สูงสุดกับข้อมูลที่ฝังอยู่ใน Redis Vectorstore ผลลัพธ์เหล่านี้จะถูกเก็บไว้ชั่วคราวในบริบทของการแชทซึ่งช่วยให้ AI ตอบคำถามโดยอ้างถึงข้อมูลเหล่านี้
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
... เมื่อเรียกใช้ฟังก์ชั่น begin_chat หากผู้ใช้อัปโหลดไฟล์ที่มีข้อความ (เช่นไฟล์ PDF หรือ TXT) ข้อความจะถูกดึงออกมาจากไฟล์โดยอัตโนมัติและการฝังเวกเตอร์จะถูกบันทึกเป็น REDIS
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py ฟังก์ชันการทำงาน ในไฟล์ commands.py มีองค์ประกอบสำคัญหลายประการ:
command_response : คลาสนี้ใช้เพื่อตั้งค่ามัณฑนากรบนวิธีการคำสั่งเพื่อระบุการดำเนินการถัดไป ช่วยในการกำหนดประเภทการตอบกลับที่หลากหลายเช่นการส่งข้อความและหยุดส่งข้อความและดำเนินการต่อการจัดการอินพุตผู้ใช้จัดการการตอบสนอง AI และอื่น ๆcommand_handler : ฟังก์ชั่นนี้รับผิดชอบในการดำเนินการวิธีการโทรกลับคำสั่งตามข้อความที่ป้อนโดยผู้ใช้arguments_provider : ฟังก์ชั่นนี้จะจัดหาอาร์กิวเมนต์ที่ต้องการโดยวิธีคำสั่งโดยอัตโนมัติตามประเภทคำอธิบายประกอบของวิธีคำสั่งTask Triggering : คุณสมบัตินี้เปิดใช้งานเมื่อใดก็ตามที่ผู้ใช้พิมพ์ข้อความหรือ AI ตอบกลับด้วยข้อความ ณ จุดนี้งานสรุปอัตโนมัติจะถูกสร้างขึ้นเพื่อควบแน่นเนื้อหาข้อความ
การจัดเก็บงาน : งานอัตโนมัติ summarization จะถูกเก็บไว้ในแอตทริบิวต์ task_list ของ BufferUserChatContext สิ่งนี้ทำหน้าที่เป็นคิวสำหรับการจัดการงานที่เชื่อมโยงกับบริบทการแชทของผู้ใช้
การเก็บเกี่ยวงาน : หลังจากเสร็จสิ้นคำถามของผู้ใช้-AI และวงจรคำตอบโดย MessageHandler ฟังก์ชั่น harvest_done_tasks จะถูกเรียกใช้ ฟังก์ชั่นนี้รวบรวมผลลัพธ์ของงานสรุปทำให้แน่ใจว่าไม่มีอะไรเหลืออยู่
แอปพลิเคชันการสรุป : หลังจากกระบวนการเก็บเกี่ยวผลลัพธ์ที่สรุปจะแทนที่ข้อความจริงเมื่อ chatbot ของเรากำลังร้องขอคำตอบจากรูปแบบการเรียนรู้ภาษา (LLMs) เช่น OpenAI และ LLAMA_CPP ด้วยการทำเช่นนั้นเราสามารถส่งพรอมต์ที่กระชับได้มากกว่าข้อความที่มีความยาวเริ่มต้น
ประสบการณ์ของผู้ใช้ : ที่สำคัญจากมุมมองของผู้ใช้พวกเขาเห็นเฉพาะข้อความต้นฉบับ เวอร์ชันสรุปของข้อความจะไม่แสดงต่อพวกเขารักษาความโปร่งใสและหลีกเลี่ยงความสับสนที่อาจเกิดขึ้น
งานพร้อมกัน : คุณลักษณะสำคัญอีกประการหนึ่งของงานการส่งสัญญาณอัตโนมัตินี้คือมันไม่ได้เป็นอุปสรรคต่องานอื่น ๆ กล่าวอีกนัยหนึ่งในขณะที่ chatbot กำลังยุ่งอยู่กับการสรุปข้อความงานอื่น ๆ ยังสามารถดำเนินการได้ดังนั้นจึงปรับปรุงประสิทธิภาพโดยรวมของ Chatbot ของเรา
ChatConfig ที่เก็บนี้มีแบบจำลอง LLM ที่แตกต่างกันซึ่งกำหนดไว้ใน llms.py คลาส LLM แต่ละคลาสสืบทอดมาจากคลาสพื้นฐาน LLMModel enum LLMModels เป็นคอลเลกชันของ LLMs เหล่านี้
การดำเนินการทั้งหมดได้รับการจัดการแบบอะซิงโครนัสโดยไม่ต้องขัดจังหวะเธรดหลัก อย่างไรก็ตาม LLM ในท้องถิ่นไม่สามารถจัดการกับคำขอหลายรายการได้ในเวลาเดียวกันเนื่องจากมีราคาแพงเกินไป ดังนั้น Semaphore จะใช้เพื่อ จำกัด จำนวนคำขอเป็น 1
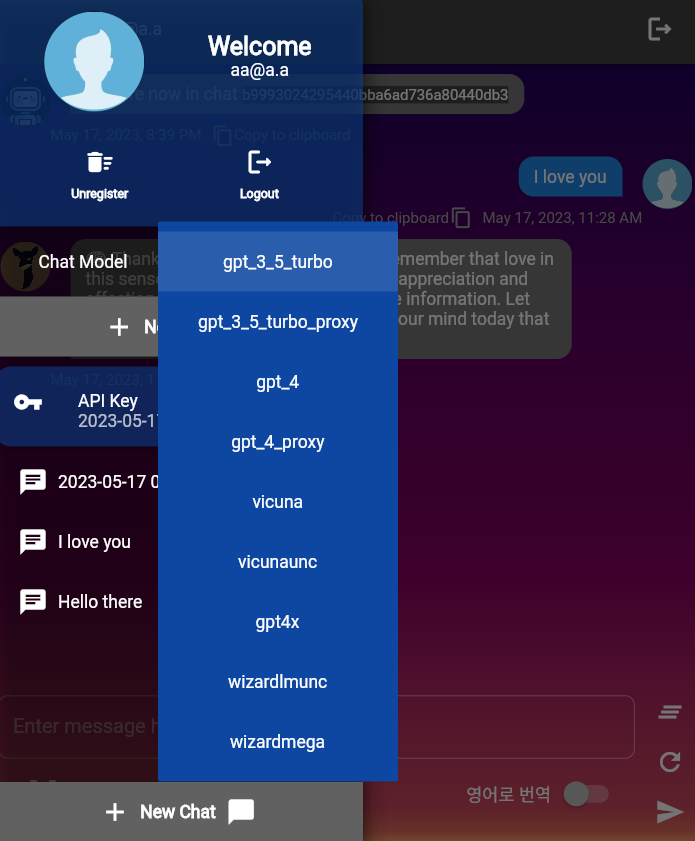
รุ่น LLM เริ่มต้นที่ใช้โดยผู้ใช้ผ่าน UserChatContext.construct_default คือ gpt-3.5-turbo คุณสามารถเปลี่ยนค่าเริ่มต้นสำหรับฟังก์ชั่นนั้น
OpenAIModel สร้างข้อความแบบอะซิงโครนัสโดยการขอแชทเสร็จสิ้นจากเซิร์ฟเวอร์ OpenAI มันต้องใช้คีย์ OpenAI API
LlamaCppModel อ่านโมเดล GGML ที่เก็บไว้ในท้องถิ่น รุ่น LLAMA.CPP GGML จะต้องใส่ในโฟลเดอร์ llama_models/ggml เป็นไฟล์ .bin ตัวอย่างเช่นหากคุณดาวน์โหลดโมเดล Q4_0 เชิงปริมาณจาก "https://huggingface.co/thebloke/robin-7b-v2-ggml" เส้นทางของโมเดลจะต้องเป็น "robin-7b.ggmlv3.q4_0.bin"
ExllamaModel อ่านรุ่น GPTQ ที่เก็บไว้ในเครื่อง รุ่น Exllama GPTQ จะต้องใส่ในโฟลเดอร์ llama_models/gptq เป็นโฟลเดอร์ ตัวอย่างเช่นหากคุณดาวน์โหลด 3 ไฟล์จาก "https://huggingface.co/thebloke/orca_mini_7b-gptq/tree/main"
จากนั้นคุณต้องใส่ไว้ในโฟลเดอร์ เส้นทางของโมเดลจะต้องเป็นชื่อโฟลเดอร์ สมมติว่า "orca_mini_7b" ซึ่งมี 3 ไฟล์
จัดการข้อยกเว้นที่อาจเกิดขึ้นระหว่างการสร้างข้อความ หากมีการโยน ChatLengthException มันจะดำเนินการตามปกติโดยอัตโนมัติเพื่อ จำกัด ข้อความให้อยู่ภายในจำนวนโทเค็นที่ จำกัด โดยฟังก์ชัน cutoff_message_histories และส่งต่อใหม่ สิ่งนี้ทำให้มั่นใจได้ว่าผู้ใช้มีประสบการณ์การแชทที่ราบรื่นโดยไม่คำนึงถึงขีด จำกัด ของโทเค็น
โครงการนี้มีจุดมุ่งหมายเพื่อสร้างแบ็กเอนด์ API เพื่อเปิดใช้งานบริการ Chatbot โมเดลภาษาขนาดใหญ่ มันใช้ตัวจัดการแคชเพื่อจัดเก็บข้อความและโปรไฟล์ผู้ใช้ใน Redis และตัวจัดการข้อความเพื่อแคชข้อความอย่างปลอดภัยเพื่อให้จำนวนโทเค็นไม่เกินขีด จำกัด ที่ยอมรับได้
Cache Manager ( CacheManager ) รับผิดชอบในการจัดการข้อมูลบริบทของผู้ใช้และประวัติข้อความ มันเก็บข้อมูลเหล่านี้ใน Redis เพื่อให้สามารถดึงและดัดแปลงได้ง่าย ผู้จัดการมีวิธีการหลายวิธีในการโต้ตอบกับแคชเช่น:
read_context_from_profile : อ่านบริบทการแชทของผู้ใช้จาก Redis ตามโปรไฟล์ของผู้ใช้create_context : สร้างบริบทการแชทผู้ใช้ใหม่ใน Redisreset_context : รีเซ็ตบริบทการแชทของผู้ใช้เป็นค่าเริ่มต้นupdate_message_histories : อัปเดตประวัติข้อความสำหรับบทบาทเฉพาะ (ผู้ใช้, AI หรือระบบ)lpop_message_history / rpop_message_history : ลบและส่งคืนประวัติข้อความจากด้านซ้ายหรือขวาของรายการappend_message_history : ผนวกประวัติข้อความไปยังจุดสิ้นสุดของรายการget_message_history : ดึงประวัติข้อความสำหรับบทบาทเฉพาะdelete_message_history : ลบประวัติข้อความสำหรับบทบาทเฉพาะset_message_history : ตั้งค่าประวัติข้อความเฉพาะสำหรับบทบาทและดัชนี ตัวจัดการข้อความ ( MessageManager ) ทำให้มั่นใจได้ว่าจำนวนโทเค็นในประวัติข้อความไม่เกินขีด จำกัด ที่ระบุ มันจัดการอย่างปลอดภัยการเพิ่มลบและการตั้งค่าประวัติข้อความในบริบทการแชทของผู้ใช้ในขณะที่ยังคงขีด จำกัด โทเค็น ผู้จัดการมีวิธีการหลายวิธีในการโต้ตอบกับประวัติข้อความเช่น:
add_message_history_safely : เพิ่มประวัติข้อความในบริบทการแชทของผู้ใช้เพื่อให้มั่นใจว่าไม่เกินขีด จำกัด โทเค็นpop_message_history_safely : ลบและส่งคืนประวัติข้อความจากส่วนท้ายของรายการในขณะที่อัปเดตจำนวนโทเค็นset_message_history_safely : ตั้งค่าประวัติข้อความเฉพาะในบริบทการแชทของผู้ใช้อัปเดตจำนวนโทเค็นและทำให้มั่นใจได้ว่าไม่เกินขีด จำกัด โทเค็น หากต้องการใช้ Cache Manager และ Message Manager ในโครงการของคุณนำเข้าดังนี้:
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManagerจากนั้นคุณสามารถใช้วิธีการของพวกเขาเพื่อโต้ตอบกับแคช Redis และจัดการประวัติข้อความตามความต้องการของคุณ
ตัวอย่างเช่นในการสร้างบริบทการแชทผู้ใช้ใหม่:
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )เพื่อเพิ่มประวัติข้อความในบริบทการแชทของผู้ใช้อย่างปลอดภัย:
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role ) โครงการนี้ใช้มิดเดิลแวร์ token_validator และมิดเดิลแวร์อื่น ๆ ที่ใช้ในแอปพลิเคชัน FASTAPI Middlewares เหล่านี้มีหน้าที่ควบคุมการเข้าถึง API เพื่อให้มั่นใจว่ามีการดำเนินการตามคำขอที่ได้รับอนุญาตและรับรองความถูกต้องเท่านั้น
Middlewares ต่อไปนี้จะถูกเพิ่มลงในแอปพลิเคชัน Fastapi:
มิดเดิลแวร์ควบคุมการเข้าถึงถูกกำหนดไว้ในไฟล์ token_validator.py มันมีหน้าที่ตรวจสอบการตรวจสอบคีย์ API และโทเค็น JWT
คลาส StateManager ใช้เพื่อเริ่มต้นตัวแปรสถานะการร้องขอ มันตั้งค่าเวลาการร้องขอเวลาเริ่มต้นที่อยู่ IP และโทเค็นผู้ใช้
คลาส AccessControl มีสองวิธีแบบคงที่สำหรับการตรวจสอบคีย์ API และโทเค็น JWT:
api_service : ตรวจสอบคีย์ API โดยตรวจสอบการมีอยู่ของพารามิเตอร์และส่วนหัวในการสืบค้นที่จำเป็นในคำขอ มันเรียกวิธี Validator.api_key เพื่อตรวจสอบคีย์ API ความลับและการประทับเวลาnon_api_service : ตรวจสอบโทเค็น JWT โดยตรวจสอบการมีอยู่ของส่วนหัว 'การอนุญาต' หรือ 'การอนุญาต' คุกกี้ในคำขอ มันเรียกวิธี Validator.jwt เพื่อถอดรหัสและตรวจสอบโทเค็น JWT คลาส Validator มีสองวิธีแบบคงที่สำหรับการตรวจสอบคีย์ API และโทเค็น JWT:
api_key : ตรวจสอบคีย์การเข้าถึง API ความลับแฮชและการประทับเวลา ส่งคืนวัตถุ UserToken หากการตรวจสอบความถูกต้องสำเร็จjwt : ถอดรหัสและตรวจสอบโทเค็น JWT ส่งคืนวัตถุ UserToken หากการตรวจสอบความถูกต้องสำเร็จ ฟังก์ชั่น access_control เป็นฟังก์ชั่นอะซิงโครนัสที่จัดการกับคำขอและการตอบสนองสำหรับมิดเดิลแวร์ มันเริ่มต้นสถานะการร้องขอโดยใช้คลาส StateManager กำหนดประเภทของการรับรองความถูกต้องที่จำเป็นสำหรับ URL ที่ร้องขอ (คีย์ API หรือโทเค็น JWT) และตรวจสอบการตรวจสอบความถูกต้องโดยใช้คลาส AccessControl หากเกิดข้อผิดพลาดในระหว่างกระบวนการตรวจสอบความถูกต้องจะมีการยกข้อยกเว้น HTTP ที่เหมาะสม
ยูทิลิตี้โทเค็นถูกกำหนดไว้ในไฟล์ token.py มันมีสองฟังก์ชั่น:
create_access_token : สร้างโทเค็น JWT ด้วยข้อมูลที่กำหนดและเวลาหมดอายุtoken_decode : ถอดรหัสและตรวจสอบโทเค็น JWT ยกข้อยกเว้นหากโทเค็นหมดอายุหรือไม่สามารถถอดรหัสได้ ไฟล์ params_utils.py มีฟังก์ชั่นยูทิลิตี้สำหรับพารามิเตอร์การสืบค้นแฮชและคีย์ลับโดยใช้ HMAC และ SHA256:
hash_params : ใช้พารามิเตอร์การสืบค้นและรหัสลับเป็นอินพุตและส่งคืนสตริงแฮชที่เข้ารหัส Base64 ไฟล์ date_utils.py มีคลาส UTC พร้อมฟังก์ชั่นยูทิลิตี้สำหรับการทำงานกับวันที่และการประทับเวลา:
now : ส่งคืน DateTime UTC ปัจจุบันด้วยความแตกต่างชั่วโมงเสริมtimestamp : ส่งคืนการประทับเวลา UTC ปัจจุบันด้วยความแตกต่างชั่วโมงเสริมtimestamp_to_datetime : แปลงการประทับเวลาเป็นวัตถุ dateTime ที่มีความแตกต่างชั่วโมงเสริม ไฟล์ logger.py มีคลาส ApiLogger ซึ่งบันทึกการร้องขอ API และข้อมูลการตอบกลับรวมถึง URL คำขอ, วิธี, รหัสสถานะ, ข้อมูลลูกค้า, เวลาในการประมวลผลและรายละเอียดข้อผิดพลาด (ถ้ามี) ฟังก์ชั่น Logger ถูกเรียกที่ส่วนท้ายของฟังก์ชัน access_control เพื่อเข้าสู่ระบบคำขอและการตอบสนองที่ประมวลผล
หากต้องการใช้มิดเดิลแวร์ token_validator ในแอปพลิเคชัน FASTAPI ของคุณเพียงแค่นำเข้าฟังก์ชั่น access_control และเพิ่มเป็นมิดเดิลแวร์ในอินสแตนซ์ fastapi ของคุณ:
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )ตรวจสอบให้แน่ใจว่าได้เพิ่ม CORS และ Host Middlewares ที่เชื่อถือได้สำหรับการควบคุมการเข้าถึงที่สมบูรณ์:
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
) ตอนนี้คำขอที่เข้ามาใด ๆ ไปยังแอปพลิเคชัน FASTAPI ของคุณจะถูกประมวลผลโดยมิดเดิลแวร์ token_validator และ MiddleWares อื่น ๆ เพื่อให้มั่นใจว่าจะดำเนินการตามคำขอที่ได้รับอนุญาตและรับรองความถูกต้องเท่านั้น
โมดูลนี้ app.database.connection ให้อินเทอร์เฟซที่ใช้งานง่ายสำหรับการจัดการการเชื่อมต่อฐานข้อมูลและดำเนินการสืบค้น SQL โดยใช้ SQLALCHEMY และ REDIS รองรับ MySQL และสามารถรวมเข้ากับโครงการนี้ได้อย่างง่ายดาย
ขั้นแรกให้นำเข้าคลาสที่ต้องการจากโมดูล:
from app . database . connection import MySQL , SQLAlchemy , CacheFactory ถัดไปสร้างอินสแตนซ์ของคลาส SQLAlchemy และกำหนดค่าด้วยการตั้งค่าฐานข้อมูลของคุณ:
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config ) ตอนนี้คุณสามารถใช้อินสแตนซ์ db เพื่อดำเนินการค้นหา SQL และจัดการเซสชัน:
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" ) หากต้องการใช้การแคช Redis ให้สร้างอินสแตนซ์ของคลาส CacheFactory และกำหนดค่าด้วยการตั้งค่า Redis ของคุณ:
cache = CacheFactory ()
cache . start ( config ) ตอนนี้คุณสามารถใช้อินสแตนซ์ cache เพื่อโต้ตอบกับ Redis:
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" ) ในความเป็นจริงในโครงการนี้คลาส MySQL จะทำการตั้งค่าเริ่มต้นที่ App Startup และการเชื่อมต่อฐานข้อมูลทั้งหมดทำด้วยตัวแปร db และ cache เท่านั้นที่มีอยู่ในตอนท้ายของโมดูล -
การตั้งค่า DB ทั้งหมดจะทำใน create_app() ใน app.common.app_settings ตัวอย่างเช่นฟังก์ชั่น create_app() ใน app.common.app_settings จะมีลักษณะเช่นนี้:
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_app โครงการนี้ใช้วิธีที่ง่ายและมีประสิทธิภาพในการจัดการฐานข้อมูล CRUD (สร้าง, อ่าน, อัปเดต, ลบ) การดำเนินงานโดยใช้ SQLALCHEMY และสองโมดูลและเส้นทาง: app.database.models.schema และ app.database.crud
โมดูล schema.py รับผิดชอบในการกำหนดรูปแบบฐานข้อมูลและความสัมพันธ์ของพวกเขาโดยใช้ sqlalchemy มันมีชุดคลาสที่สืบทอดมาจาก Base อินสแตนซ์ของ declarative_base() แต่ละคลาสแสดงถึงตารางในฐานข้อมูลและแอตทริบิวต์แสดงถึงคอลัมน์ในตาราง คลาสเหล่านี้ยังสืบทอดมาจากคลาส Mixin ซึ่งให้วิธีการทั่วไปและแอตทริบิวต์สำหรับทุกรุ่น
คลาส Mixin ให้คุณลักษณะและวิธีการทั่วไปสำหรับคลาสทั้งหมดที่สืบทอดมาจากมัน คุณลักษณะบางอย่างรวมถึง:
id : คีย์หลักจำนวนเต็มสำหรับตารางcreated_at : DateTime เมื่อมีการสร้างระเบียนupdated_at : DateTime สำหรับเมื่อบันทึกได้รับการอัปเดตล่าสุดip_address : ที่อยู่ IP ของไคลเอนต์ที่สร้างหรืออัปเดตบันทึกนอกจากนี้ยังมีวิธีการเรียนหลายวิธีที่ดำเนินการ CRUD โดยใช้ sqlalchemy เช่น:
add_all() : เพิ่มหลายระเบียนลงในฐานข้อมูลadd_one() : เพิ่มระเบียนเดียวในฐานข้อมูลupdate_where() : อัปเดตบันทึกในฐานข้อมูลตามตัวกรองfetchall_filtered_by() : ดึงข้อมูลทั้งหมดจากฐานข้อมูลที่ตรงกับตัวกรองที่ให้ไว้one_filtered_by() : ดึงข้อมูลบันทึกเดียวจากฐานข้อมูลที่ตรงกับตัวกรองที่ให้ไว้first_filtered_by() : ดึงข้อมูลบันทึกแรกจากฐานข้อมูลที่ตรงกับตัวกรองที่ให้ไว้one_or_none_filtered_by() : ดึงข้อมูลบันทึกเดียวหรือส่งคืน None ถ้าไม่มีระเบียนที่ตรงกับตัวกรองที่ให้ไว้ users.py และ api_keys.py โมดูลมีชุดของฟังก์ชั่นที่ดำเนินการ CRUD โดยใช้คลาสที่กำหนดไว้ใน schema.py ฟังก์ชั่นเหล่านี้ใช้วิธีการคลาสที่จัดทำโดยคลาส Mixin เพื่อโต้ตอบกับฐานข้อมูล
ฟังก์ชั่นบางอย่างในโมดูลนี้รวมถึง:
create_api_key() : สร้างคีย์ API ใหม่สำหรับผู้ใช้get_api_keys() : ดึงปุ่ม API ทั้งหมดสำหรับผู้ใช้get_api_key_owner() : ดึงเจ้าของคีย์ APIget_api_key_and_owner() : ดึงรหัส API และเจ้าของupdate_api_key() : อัปเดตคีย์ APIdelete_api_key() : ลบคีย์ APIis_email_exist() : ตรวจสอบว่ามีอีเมลอยู่ในฐานข้อมูลหรือไม่get_me() : ดึงข้อมูลผู้ใช้ตามรหัสผู้ใช้is_valid_api_key() : ตรวจสอบว่าคีย์ API นั้นถูกต้องหรือไม่register_new_user() : ลงทะเบียนผู้ใช้ใหม่ในฐานข้อมูลfind_matched_user() : ค้นหาผู้ใช้ที่มีอีเมลที่ตรงกันในฐานข้อมูล ในการใช้การดำเนินการ CRUD ที่ให้ไว้ให้นำเข้าฟังก์ชั่นที่เกี่ยวข้องจากโมดูล crud.py และเรียกพวกเขาด้วยพารามิเตอร์ที่ต้องการ ตัวอย่างเช่น:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())