LLMChat
v1.1.3.4.1
Bem-vindo ao repositório LLMCHAT, uma implementação de pilha completa de um servidor de API construído com o Python Fastapi e um belo front-end movido pela Flutter. Este projeto foi projetado para oferecer uma experiência de bate -papo perfeita com o avançado ChatGPT e outros modelos LLM. ? Oferecendo uma infraestrutura moderna que pode ser facilmente estendida quando os recursos multimodais e plug-in do GPT-4 estiverem disponíveis. Aproveite a sua estadia!
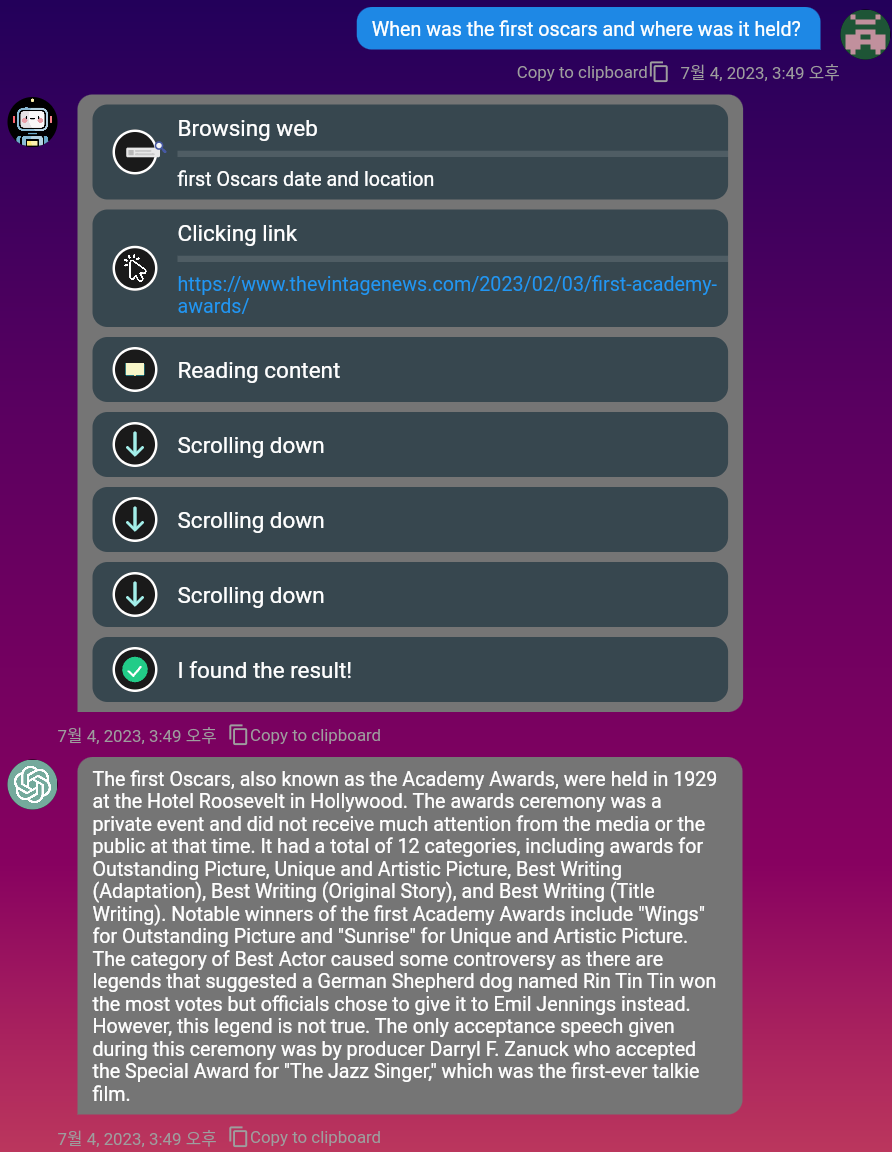
mobile e PC .Markdown também é suportado, para que você possa usá -lo para formatar suas mensagens.Você pode usar o mecanismo de pesquisa do DuckDuckgo para encontrar informações relevantes na web. Basta ativar o botão de alternância 'navegar'!
Assista ao vídeo de demonstração para navegação completa: https://www.youtube.com/watch?v=mj_cvrwrs08
Com o comando /embed , você pode armazenar o texto indefinidamente em seu próprio banco de dados de vetores privados e consultá -lo posteriormente, a qualquer momento. Se você usar o comando /share , o texto será armazenado em um banco de dados de vetores públicos que todos podem compartilhar. A ativação do comando de alternância Query ou /query ajuda a IA a gerar respostas contextualizadas pesquisando semelhanças com texto nos bancos de dados públicos e privados. Isso resolve uma das maiores limitações dos modelos de linguagem: memória .
Você pode incorporar o arquivo PDF clicando no Embed Document no canto inferior esquerdo. Em alguns segundos, o conteúdo de texto do PDF será convertido em vetores e incorporado ao cache redis.
LLMModels , localizado em app/models/llms.py . Para o Llalam LLMS local, supõe -se que funcione apenas no ambiente local e usa o terminal http://localhost:8002/v1/completions . Ele verifica continuamente o status do servidor API da LLAMA, conectando -se ao http://localhost:8002/health uma vez um segundo para ver se uma resposta de 200 OK é retornada e, se não, executa automaticamente um processo separado para criar um servidor de API.
O principal objetivo do llama.cpp é executar o modelo LLAMA usando quantização GGML de 4 bits com implementação simples de C/C ++ sem dependências. Você deve baixar o arquivo bin ggml do huggingface e colocá -lo na pasta llama_models/ggml e definir llmmodel no app/models/llms.py . Existem poucos exemplos, para que você possa definir facilmente seu próprio modelo. Consulte o repositório llama.cpp para obter mais informações: https://github.com/ggerganov/llama.cpp
Uma implementação independente de Python/C ++/CUDA para uso com pesos GPTQ de 4 bits, projetados para ser rápido e eficiente em termos de memória nas GPUs modernas. Ele usa pytorch e sentencepiece para executar o modelo. Presume -se que funcione apenas no ambiente local e pelo menos uma NVIDIA CUDA GPU é necessária. Você deve baixar arquivos Tokenizer, Config e GPTQ da HuggingFace e colocá -lo na pasta llama_models/gptq/YOUR_MODEL_FOLDER e definir LLMModel em app/models/llms.py . Existem poucos exemplos, para que você possa definir facilmente seu próprio modelo. Consulte o Repositório exllama para obter informações mais detalhadas: https://github.com/turboderp/exllama
web framework de alto desempenho para criar APIs com Python.Webapp com uma interface do usuário bonita e um rico conjunto de widgets personalizáveis.OpenAI API para geração de texto e gerenciamento de mensagens.LlamaCpp e Exllama .Real-time com o ChatGPT e outros modelos LLM, com o Flutter Frontend WebApp.Redis e Langchain , armazenar e recuperar incorporação de vetores para pesquisa de similaridade. Isso ajudará a IA a gerar respostas mais relevantes.Duckduckgo , navegue na web e encontre informações relevantes.async / await para simultaneidade e paralelismo.MySQL . Execute facilmente as ações de criação, leitura, atualização e exclusão, com sqlalchemy.asyncioRedis com Aioredis. Execute facilmente as ações de criação, leitura, atualização e exclusão, com aioredis . Para configurar a máquina local, siga estas etapas simples. Antes de começar, verifique se você tem docker e docker-compose instalados em sua máquina. Se você deseja executar o servidor sem o Docker, é necessário instalar Python 3.11 . Mesmo assim, você precisa Docker para executar servidores DB.
Para clonar recursivamente os submódulos para usar os modelos Exllama ou llama.cpp , use o seguinte comando:
git clone --recurse-submodules https://github.com/c0sogi/llmchat.gitVocê só deseja usar os recursos principais (OpenAI), use o seguinte comando:
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.env Configure um arquivo Env, referindo-se ao arquivo .env-sample . Digite as informações do banco de dados para criar, a chave da API Open e outras configurações necessárias. Não são necessários opcionais, apenas deixe -os como eles.
Execute estes. Pode levar alguns minutos para iniciar o servidor pela primeira vez:
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml down Agora você pode acessar o servidor em http://localhost:8000/docs e o banco de dados em db:3306 ou cache:6379 . Você também pode acessar o aplicativo em http://localhost:8000/chat .
Para executar o servidor sem o Docker, se você deseja executar o servidor sem o Docker, você deve instalar Python 3.11 adicionalmente. Mesmo assim, você precisa Docker para executar servidores DB. Desligue o servidor da API já em execução com docker-compose -f docker-compose-local.yaml down api . Não se esqueça de executar outros servidores de banco de dados no Docker! Em seguida, execute os seguintes comandos:
python -m main Seu servidor agora deve estar em funcionamento em http://localhost:8001 neste caso.
Este projeto está licenciado sob a licença do MIT, que permite o uso, modificação e distribuição gratuitamente, desde que o aviso original de direitos autorais e licença esteja incluído em qualquer cópia ou parte substancial do software.
FastAPI é uma estrutura da web moderna para criar APIs com Python. ? Possui alto desempenho, fácil de aprender, rápido para codificar e pronto para a produção. ? Uma das principais características do FastAPI é que ele suporta simultaneidade e sintaxe async / await . ? Isso significa que você pode escrever código que pode lidar com várias tarefas ao mesmo tempo sem bloquear um ao outro, especialmente ao lidar com operações ligadas de E/S, como solicitações de rede, consultas de banco de dados, operações de arquivo etc.
Flutter é um kit de ferramentas de interface do usuário de código aberto desenvolvido pelo Google para criar interfaces de usuário nativo para plataformas móveis, web e de mesa a partir de uma única base de código. ? Utiliza Dart , uma linguagem de programação moderna orientada a objetos, e fornece um rico conjunto de widgets personalizáveis que podem se adaptar a qualquer design.
Você pode acessar ChatGPT ou LlamaCpp através da conexão WebSocket usando dois módulos: app/routers/websocket e app/utils/chat/chat_stream_manager . Esses módulos facilitam a comunicação entre o cliente Flutter e o modelo de bate -papo através de um WebSocket. Com o WebSocket, você pode estabelecer um canal de comunicação bidirecional em tempo real para interagir com o LLM.
Para iniciar uma conversa, conecte -se à rota WebSocket /ws/chat/{api_key} com uma chave de API válida registrada no banco de dados. Observe que essa chave da API não é a mesma que a tecla API OpenAI, mas disponível apenas para o seu servidor validar o usuário. Depois de conectado, você pode enviar mensagens e comandos para interagir com o modelo LLM. O WebSocket enviará respostas de bate-papo em tempo real. Esta conexão WebSocket é estabelecida via aplicativo Flutter, que pode ser acessado com terminal /chat .
websocket.py é responsável por configurar uma conexão WebSocket e lidar com a autenticação do usuário. Ele define a rota WebSocket /chat/{api_key} que aceita um WebSocket e uma chave da API como parâmetros.
Quando um cliente se conecta ao WebSocket, ele primeiro verifica a chave da API para autenticar o usuário. Se a chave da API for válida, a função begin_chat() será chamada do módulo stream_manager.py para iniciar a conversa.
No caso de uma chave API não registrada ou um erro inesperado, uma mensagem apropriada é enviada ao cliente e a conexão é fechada.
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.py é responsável por gerenciar a conversa e lidar com mensagens de usuário. Ele define a função begin_chat() , que leva um WebSocket, um ID de usuário como parâmetros.
A função inicialmente inicializa o contexto de bate -papo do usuário no Cache Manager. Em seguida, ele envia o histórico inicial de mensagens para o cliente através do WebSocket.
A conversa continua em um loop até que a conexão seja fechada. Durante a conversa, as mensagens do usuário são processadas e as respostas do GPT são geradas de acordo.
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
... A classe SendToWebsocket é usada para enviar mensagens e fluxos para o WebSocket. Possui dois métodos: message() e stream() . O método message() envia uma mensagem completa para o WebSocket, enquanto o método stream() envia um fluxo para o WebSocket.
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
... A classe MessageHandler também lida com respostas de IA. O método ai() envia a resposta da IA ao WebSocket. Se a tradução estiver ativada, a resposta será traduzida usando a API do Google Translate antes de enviá -la para o cliente.
class MessageHandler :
...
@ staticmethod
async def ai (...):
... As mensagens do usuário são processadas usando a classe HandleMessage . Se a mensagem começar com / , como /YOUR_CALLBACK_NAME . É tratado como um comando e a resposta de comando apropriada é gerada. Caso contrário, a mensagem do usuário é processada e enviada ao modelo LLM para gerar uma resposta.
Os comandos são tratados usando a classe ChatCommands . Ele executa a função de retorno de chamada correspondente, dependendo do comando. Você pode adicionar novos comandos simplesmente adicionando retorno de chamada na classe ChatCommands do app.utils.chat.chat_commands .
Usando o Redis para armazenar incorporações de vetor de conversas? ️ pode ajudar o modelo ChatGPT? De várias maneiras, como uma recuperação eficiente e rápida do contexto da conversa ♀️, lidando com grandes quantidades de dados e fornecendo respostas mais relevantes por meio da pesquisa de similaridade vetorial?
Alguns exemplos divertidos de como isso poderia funcionar na prática:
/embed Quando um usuário insere um comando na janela de bate -papo como /embed <text_to_embed> , o método VectorStoreManager.create_documents é chamado. Este método converte o texto de entrada em um vetor usando o modelo text-embedding-ada-002 do OpenAI e o armazena no Redis VectorStore.
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../query Quando o usuário insere o comando /query <query> , a função asimilarity_search é usada para encontrar até três resultados com a maior similaridade vetorial com os dados incorporados no Redis Vectorstore. Esses resultados são temporariamente armazenados no contexto do bate -papo, o que ajuda a AI a responder à consulta, referindo -se a esses dados.
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
... Ao executar a função begin_chat , se um usuário enviar um arquivo que contém texto (por exemplo, um arquivo pdf ou txt), o texto será automaticamente extraído do arquivo e sua incorporação de vetor é salva ao Redis.
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py funcionalidade No arquivo commands.py , existem vários componentes importantes:
command_response : Esta classe é usada para definir um decorador no método de comando para especificar a próxima ação. Ajuda a definir vários tipos de resposta, como enviar uma mensagem e parar, enviar uma mensagem e continuar, lidar com a entrada do usuário, lidar com respostas de IA e muito mais.command_handler : Esta função é responsável por executar um método de retorno de chamada de comando com base no texto inserido pelo usuário.arguments_provider : Esta função fornece automaticamente os argumentos exigidos pelo método de comando com base no tipo de anotação do método de comando.TRANSPORTE DE TASK : Esse recurso é ativado sempre que um usuário digita uma mensagem ou a IA responde com uma mensagem. Neste ponto, uma tarefa de resumo automático é gerada para condensar o conteúdo do texto.
Armazenamento de tarefas : a tarefa de amosmarização automática é armazenada no atributo task_list do BufferUserChatContext . Isso serve como uma fila para gerenciar tarefas vinculadas ao contexto de bate -papo do usuário.
CHEPTING DE TAREGA : Após a conclusão de um ciclo de perguntas e respostas do usuário-AI pelo MessageHandler , a função harvest_done_tasks é invocada. Essa função coleta os resultados da tarefa de resumo, certificando -se de que nada seja deixado de fora.
Aplicação de resumo : Após o processo de colheita, os resultados resumidos substituem a mensagem real quando nosso chatbot estiver solicitando respostas dos Modelos de Aprendizagem de Idiomas (LLMS), como OpenAI e LLAMA_CPP. Ao fazer isso, podemos enviar instruções muito mais sucintas do que a longa mensagem inicial.
Experiência do usuário : É importante ressaltar que, da perspectiva do usuário, eles só veem a mensagem original. A versão resumida da mensagem não é mostrada a eles, mantendo a transparência e evitando possíveis confusão.
Tarefas simultâneas : outro recurso-chave dessa tarefa de humilização automática é que ela não impede outras tarefas. Em outras palavras, enquanto o chatbot está ocupado resumindo o texto, outras tarefas ainda podem ser realizadas, melhorando assim a eficiência geral do nosso chatbot.
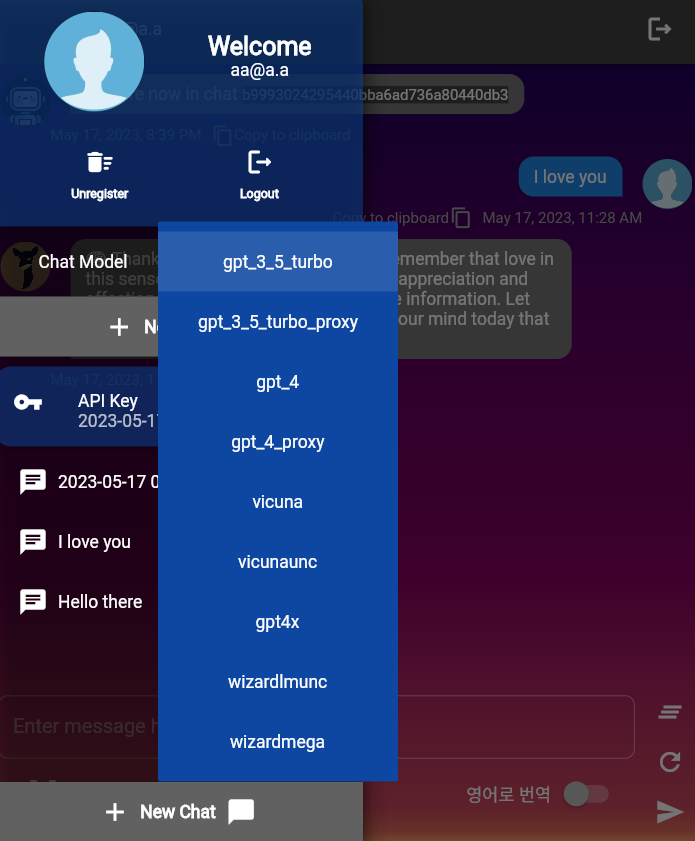
ChatConfig . Este repositório contém diferentes modelos LLM, definidos em llms.py Cada classe do modelo LLM herdou a partir da classe Base LLMModel . O LLMModels Enum é uma coleção desses LLMs.
Todas as operações são tratadas de forma assíncrona sem interromper o thread principal. No entanto, os LLMs locais não são capazes de lidar com várias solicitações ao mesmo tempo, pois são muito caras computacionalmente. Portanto, um Semaphore é usado para limitar o número de solicitações a 1.
O modelo LLM padrão usado pelo usuário via UserChatContext.construct_default é gpt-3.5-turbo . Você pode alterar o padrão para essa função.
OpenAIModel gera texto de forma assíncrona solicitando a conclusão do bate -papo no servidor OpenAI. Requer uma chave de API do OpenAI.
LlamaCppModel lê um modelo GGML armazenado localmente. O modelo LLAMA.CPP GGML deve ser colocado na pasta llama_models/ggml como um arquivo .bin . Por exemplo, se você baixou um modelo quantizado Q4_0 em "https://huggingface.co/thebloke/robin-7b-v2-ggml", o caminho do modelo deve ser "robin-7b.ggmlv3.q4_0.bin".
ExllamaModel leu um modelo GPTQ armazenado localmente. O modelo GPTQ exllama deve ser colocado na pasta llama_models/gptq como uma pasta. Por exemplo, se você baixou 3 arquivos de "https://huggingface.co/thebloke/orca_mini_7b-gptq/tree/main":
Então você precisa colocá -los em uma pasta. O caminho do modelo deve ser o nome da pasta. Digamos que "orca_mini_7b", que contém os 3 arquivos.
Lidar com exceções que podem ocorrer durante a geração de texto. Se uma ChatLengthException for lançada, ele executará automaticamente uma rotina para limitar a mensagem para dentro do número de tokens limitados pela função cutoff_message_histories e reenviá-la. Isso garante que o usuário tenha uma experiência de bate -papo suave, independentemente do limite do token.
Este projeto tem como objetivo criar um back -end da API para ativar o serviço de chatbot de modelo de idioma grande. Ele utiliza um gerenciador de cache para armazenar mensagens e perfis de usuário no Redis e um gerenciador de mensagens para cache com segurança mensagens para que o número de tokens não exceda um limite aceitável.
O Cache Manager ( CacheManager ) é responsável por lidar com informações de contexto e históricos de mensagens de contexto do usuário. Ele armazena esses dados no Redis, permitindo fácil recuperação e modificação. O gerente fornece vários métodos para interagir com o cache, como:
read_context_from_profile : lê o contexto de bate -papo do usuário da Redis, de acordo com o perfil do usuário.create_context : cria um novo contexto de bate -papo do usuário no redis.reset_context : redefine o contexto de bate -papo do usuário para valores padrão.update_message_histories : atualiza os históricos de mensagens para uma função específica (usuário, IA ou sistema).lpop_message_history / rpop_message_history : remove e retorna o histórico da mensagem da extremidade esquerda ou direita da lista.append_message_history : anexa um histórico de mensagens ao final da lista.get_message_history : recupera o histórico de mensagens para uma função específica.delete_message_history : exclui o histórico de mensagens para uma função específica.set_message_history : define um histórico de mensagens específico para uma função e índice. O gerenciador de mensagens ( MessageManager ) garante que o número de tokens nos históricos de mensagens não exceda o limite especificado. Ele lida com segurança adicionando, removendo e definindo históricos de mensagens no contexto de bate -papo do usuário, mantendo os limites do token. O gerente fornece vários métodos para interagir com históricos de mensagens, como:
add_message_history_safely : adiciona um histórico de mensagens ao contexto de bate -papo do usuário, garantindo que o limite do token não seja excedido.pop_message_history_safely : Remove e retorna o histórico da mensagem da extremidade direita da lista enquanto atualiza a contagem de token.set_message_history_safely : define um histórico de mensagens específico no contexto de bate -papo do usuário, atualizando a contagem de token e garantindo que o limite do token não seja excedido. Para usar o gerenciador de cache e o gerenciador de mensagens em seu projeto, importe -os da seguinte forma:
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManagerEm seguida, você pode usar os métodos deles para interagir com o Cache Redis e gerenciar históricos de mensagens de acordo com seus requisitos.
Por exemplo, para criar um novo contexto de bate -papo do usuário:
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )Para adicionar um histórico de mensagens com segurança ao contexto de bate -papo do usuário:
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role ) Este projeto usa o Middleware token_validator e outros utensílios médios usados no aplicativo FASTAPI. Esses meios médios são responsáveis pelo controle do acesso à API, garantindo que apenas solicitações autorizadas e autenticadas sejam processadas.
Os seguintes produtos médios são adicionados ao aplicativo FASTAPI:
O middleware de controle de acesso é definido no arquivo token_validator.py . É responsável por validar as chaves da API e os tokens JWT.
A classe StateManager é usada para inicializar as variáveis de estado de solicitação. Ele define o tempo de solicitação, o horário de início, o endereço IP e o token do usuário.
A classe AccessControl contém dois métodos estáticos para validar as chaves da API e os tokens JWT:
api_service : valida as teclas da API, verificando a existência dos parâmetros e cabeçalhos de consulta necessários na solicitação. Ele chama o método Validator.api_key para verificar a chave da API, secreto e registro de data e hora.non_api_service : valida os tokens JWT, verificando a existência do cookie de 'autorização' ou 'autorização' na solicitação. Ele chama o método Validator.jwt para decodificar e verificar o token JWT. A classe Validator contém dois métodos estáticos para validar as chaves da API e os tokens JWT:
api_key : Verifica a chave de acesso da API, hashed segredo e registro de data e hora. Retorna um objeto UserToken se a validação for bem -sucedida.jwt : decodifica e verifica o token JWT. Retorna um objeto UserToken se a validação for bem -sucedida. A função access_control é uma função assíncrona que lida com o fluxo de solicitação e resposta para o middleware. Ele inicializa o estado de solicitação usando a classe StateManager , determina o tipo de autenticação necessária para a URL solicitada (chave da API ou token JWT) e valida a autenticação usando a classe AccessControl . Se ocorrer um erro durante o processo de validação, uma exceção HTTP apropriada será aumentada.
Os utilitários de token são definidos no arquivo token.py . Ele contém duas funções:
create_access_token : cria um token JWT com os dados e o tempo de validade fornecidos.token_decode : decodifica e verifica um token JWT. Levanta uma exceção se o token estiver expirado ou não puder ser decodificado. O arquivo params_utils.py contém uma função de utilidade para parâmetros de consulta de hash e chave secreta usando HMAC e SHA256:
hash_params : pega parâmetros de consulta e chave secreta como entrada e retorna uma string de hash codificada Base64. O arquivo date_utils.py contém a classe UTC com funções utilitárias para trabalhar com datas e registros de data e hora:
now : retorna o UTC DateTime atual com uma diferença de hora opcional.timestamp : Retorna o registro de data e hora atual do UTC com uma diferença de hora opcional.timestamp_to_datetime : converte um registro de data e hora em um objeto DateTime com uma diferença de hora opcional. O arquivo logger.py contém a classe ApiLogger , que registra informações de solicitação e resposta da API, incluindo o URL da solicitação, método, código de status, informações do cliente, tempo de processamento e detalhes de erro (se aplicável). A função do registrador é chamada no final da função access_control para registrar a solicitação e a resposta processados.
Para usar o middleware token_validator no seu aplicativo FASTAPI, basta importar a função access_control e adicioná -lo como um middleware à sua instância do FASTAPI:
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )Certifique -se de adicionar também os Middlewares do CORS e o host confiável para controle completo de acesso:
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
) Agora, quaisquer solicitações recebidas para o seu aplicativo FASTAPI serão processadas pelo middleware token_validator e outros Middlewares, garantindo que apenas solicitações autorizadas e autenticadas sejam processadas.
Este módulo app.database.connection fornece uma interface fácil de usar para gerenciar conexões de banco de dados e executar consultas SQL usando SQLalChemy e Redis. Ele suporta MySQL e pode ser facilmente integrado a este projeto.
Primeiro, importe as classes necessárias do módulo:
from app . database . connection import MySQL , SQLAlchemy , CacheFactory Em seguida, crie uma instância da classe SQLAlchemy e configure -a com as configurações do seu banco de dados:
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config ) Agora você pode usar a instância db para executar consultas SQL e gerenciar sessões:
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" ) Para usar o Redis Caching, crie uma instância da classe CacheFactory e configure -a com suas configurações Redis:
cache = CacheFactory ()
cache . start ( config ) Agora você pode usar a instância cache para interagir com Redis:
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" ) De fato, neste projeto, a classe MySQL faz a configuração inicial na inicialização do aplicativo e todas as conexões de banco de dados são feitas apenas com as variáveis db e cache presentes no final do módulo. ?
Todas as configurações do banco de dados serão feitas em create_app() em app.common.app_settings . Por exemplo, a função create_app() em app.common.app_settings ficará assim:
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_app Este projeto usa operações simples e eficientes de lidar com o banco de dados CRUD (criar, ler, atualizar, excluir) operações usando sqlalchemy e dois módulos e caminho: app.database.models.schema e app.database.crud .
O módulo schema.py é responsável pela definição de modelos de banco de dados e seus relacionamentos usando o SQLalChemy. Inclui um conjunto de classes que herdam da Base , uma instância de declarative_base() . Cada classe representa uma tabela no banco de dados e seus atributos representam colunas na tabela. Essas classes também herdam de uma classe Mixin , que fornece alguns métodos e atributos comuns para todos os modelos.
A classe Mixin fornece alguns atributos e métodos comuns para todas as classes que herdam dela. Alguns dos atributos incluem:
id : Chave primária inteira para a tabela.created_at : DateTime para quando o registro foi criado.updated_at : DateTime para quando o registro foi atualizado pela última vez.ip_address : endereço IP do cliente que criou ou atualizou o registro.Ele também fornece vários métodos de classe que executam operações CRUD usando SQLalChemy, como:
add_all() : adiciona vários registros ao banco de dados.add_one() : adiciona um único registro ao banco de dados.update_where() : atualiza registros no banco de dados com base em um filtro.fetchall_filtered_by() : busca todos os registros do banco de dados que correspondem ao filtro fornecido.one_filtered_by() : busca um único registro do banco de dados que corresponde ao filtro fornecido.first_filtered_by() : busca o primeiro registro do banco de dados que corresponde ao filtro fornecido.one_or_none_filtered_by() : busca um único registro ou retorna None se nenhum registro corresponde ao filtro fornecido. O módulo users.py e api_keys.py contém um conjunto de funções que executam operações CRUD usando as classes definidas no schema.py . Essas funções usam os métodos de classe fornecidos pela classe Mixin para interagir com o banco de dados.
Algumas das funções deste módulo incluem:
create_api_key() : cria uma nova chave da API para um usuário.get_api_keys() : recupera todas as teclas da API para um usuário.get_api_key_owner() : Recupera o proprietário de uma chave da API.get_api_key_and_owner() : Recupera uma chave da API e seu proprietário.update_api_key() : atualiza uma chave da API.delete_api_key() : exclui uma chave da API.is_email_exist() : verifica se existe um email no banco de dados.get_me() : Recupera as informações do usuário com base no ID do usuário.is_valid_api_key() : verifica se uma chave da API é válida.register_new_user() : Registre um novo usuário no banco de dados.find_matched_user() : encontra um usuário com um email correspondente no banco de dados. Para usar as operações CRUD fornecidas, importe as funções relevantes do módulo crud.py e ligue para os parâmetros necessários. Por exemplo:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())