LLMChat
v1.1.3.4.1
Selamat datang di Repositori Llmchat, implementasi full-stack dari server API yang dibangun dengan Python Fastapi, dan frontend yang indah ditenagai oleh Flutter. Proyek ini dirancang untuk memberikan pengalaman obrolan yang mulus dengan chatgpt canggih dan model LLM lainnya. ? Menawarkan infrastruktur modern yang dapat dengan mudah diperluas ketika fitur multimodal dan plugin GPT-4 tersedia. Nikmati masa tinggal Anda!
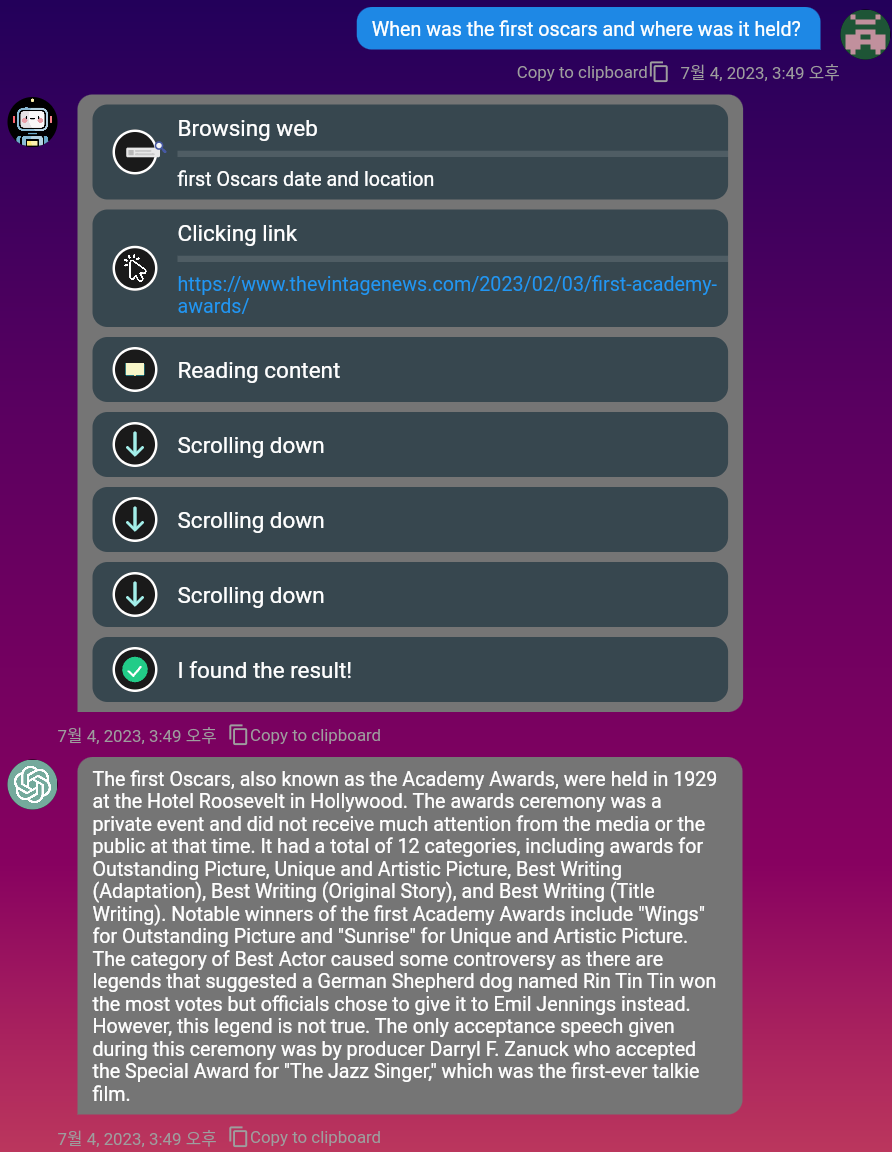
mobile dan PC .Markdown juga didukung, sehingga Anda dapat menggunakannya untuk memformat pesan Anda.Anda dapat menggunakan mesin pencari Duckduckgo untuk menemukan informasi yang relevan di web. Aktifkan saja tombol sakelar 'Jelajahi'!
Tonton Video Demo untuk Penjajakan Penuh: https://www.youtube.com/watch?v=MJ_CVRWRS08
Dengan perintah /embed , Anda dapat menyimpan teks tanpa batas waktu di database vektor pribadi Anda dan menanyakannya nanti, kapan saja. Jika Anda menggunakan perintah /share , teks disimpan dalam database vektor publik yang dapat dibagikan semua orang. Mengaktifkan tombol sakelar Query atau /query membantu AI menghasilkan jawaban kontekstual dengan mencari kesamaan teks dalam database publik dan pribadi. Ini memecahkan salah satu batasan terbesar model bahasa: memori .
Anda dapat menyematkan file pdf dengan mengklik Embed Document di kiri bawah. Dalam beberapa detik, konten teks PDF akan dikonversi menjadi vektor dan tertanam ke redis cache.
LLMModels yang terletak di app/models/llms.py . Untuk llalam llalam lokal, diasumsikan hanya bekerja di lingkungan lokal dan menggunakan http://localhost:8002/v1/completions titik akhir. Ini terus -menerus memeriksa status server API LLAMA dengan menghubungkan ke http://localhost:8002/health sekali sebentar untuk melihat apakah respons 200 OK dikembalikan, dan jika tidak, secara otomatis menjalankan proses terpisah untuk membuat server API.
Tujuan utama llama.cpp adalah menjalankan model LLAMA menggunakan kuantisasi 4-bit GGML dengan implementasi C/C ++ biasa tanpa dependensi. Anda harus mengunduh file bin GGML dari HuggingFace dan memasukkannya ke dalam folder llama_models/ggml , dan tentukan LLMModel di app/models/llms.py . Ada beberapa contoh, sehingga Anda dapat dengan mudah mendefinisikan model Anda sendiri. Lihat Repositori llama.cpp untuk informasi lebih lanjut: https://github.com/ggerganov/llama.cpp
Implementasi Llama Python/C ++/CUDA yang mandiri untuk digunakan dengan bobot GPTQ 4-bit, yang dirancang untuk menjadi cepat dan efisien memori pada GPU modern. Menggunakan pytorch dan sentencepiece untuk menjalankan model. Diasumsikan hanya bekerja di lingkungan setempat dan setidaknya satu NVIDIA CUDA GPU diperlukan. Anda harus mengunduh file Tokenizer, Config, dan GPTQ dari HuggingFace dan memasukkannya ke dalam folder llama_models/gptq/YOUR_MODEL_FOLDER , dan tentukan LLMModel di app/models/llms.py . Ada beberapa contoh, sehingga Anda dapat dengan mudah mendefinisikan model Anda sendiri. Lihat Repositori exllama untuk informasi lebih rinci: https://github.com/turboderp/exlama
web framework berkinerja tinggi untuk membangun API dengan Python.Webapp dengan UI yang indah dan set widget yang dapat disesuaikan.OpenAI API untuk pembuatan teks dan manajemen pesan.LlamaCpp dan Exllama Model.Real-time , dua arah dengan chatgpt, dan model LLM lainnya, dengan Webapp Frontend Flutter.Redis dan Langchain , menyimpan dan mengambil embeddings vektor untuk pencarian kesamaan. Ini akan membantu AI untuk menghasilkan tanggapan yang lebih relevan.Duckduckgo , menelusuri web dan temukan informasi yang relevan.async / await untuk konkurensi dan paralelisme.MySQL . Mudah Lakukan Tindakan Buat, Membaca, Perbarui, dan Hapus dengan Mudah, dengan sqlalchemy.asyncioRedis dengan Aioredis. Mudah melakukan tindakan Buat, Baca, Perbarui, dan Hapus dengan mudah, dengan aioredis . Untuk mengatur mesin lokal Anda, ikuti langkah -langkah sederhana ini. Sebelum Anda mulai, pastikan Anda memiliki docker dan docker-compose yang dipasang di mesin Anda. Jika Anda ingin menjalankan server tanpa Docker, Anda harus menginstal Python 3.11 tambahan. Meskipun, Anda perlu Docker untuk menjalankan server DB.
Untuk secara rekursif mengkloning submodules untuk menggunakan model Exllama atau llama.cpp , gunakan perintah berikut:
git clone --recurse-submodules https://github.com/c0sogi/llmchat.gitAnda hanya ingin menggunakan fitur inti (openai), menggunakan perintah berikut:
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.env Siapkan file Env, merujuk pada file .env-sample . Masukkan informasi database untuk membuat, kunci API OpenAI, dan konfigurasi lain yang diperlukan. Opsial tidak diperlukan, tinggalkan saja.
Jalankan ini. Mungkin perlu beberapa menit untuk memulai server untuk pertama kalinya:
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml down Sekarang Anda dapat mengakses server di http://localhost:8000/docs dan database di db:3306 atau cache:6379 . Anda juga dapat mengakses aplikasi di http://localhost:8000/chat .
Untuk menjalankan server tanpa Docker jika Anda ingin menjalankan server tanpa Docker, Anda harus menginstal Python 3.11 tambahan. Meskipun, Anda perlu Docker untuk menjalankan server DB. Matikan server API yang sudah berjalan dengan docker-compose -f docker-compose-local.yaml down api . Jangan lupa untuk menjalankan server DB lain di Docker! Kemudian, jalankan perintah berikut:
python -m main Server Anda sekarang harus siap dan berjalan di http://localhost:8001 dalam hal ini.
Proyek ini dilisensikan di bawah lisensi MIT, yang memungkinkan penggunaan gratis, modifikasi, dan distribusi, selama hak cipta dan pemberitahuan lisensi asli termasuk dalam salinan atau bagian substansial dari perangkat lunak.
FastAPI adalah kerangka kerja web modern untuk membangun API dengan Python. ? Ini memiliki kinerja tinggi, mudah dipelajari, cepat untuk kode, dan siap untuk diproduksi. ? Salah satu fitur utama FastAPI adalah mendukung Sintaks Concurrency dan async / await . ? Ini berarti bahwa Anda dapat menulis kode yang dapat menangani banyak tugas secara bersamaan tanpa memblokir satu sama lain, terutama ketika berhadapan dengan operasi I/O Bound, seperti permintaan jaringan, kueri basis data, operasi file, dll.
Flutter adalah toolkit UI open-source yang dikembangkan oleh Google untuk membangun antarmuka pengguna asli untuk platform seluler, web, dan desktop dari basis kode tunggal. ? Menggunakan Dart , bahasa pemrograman berorientasi objek modern, dan menyediakan satu set yang kaya widget yang dapat disesuaikan yang dapat beradaptasi dengan desain apa pun.
Anda dapat mengakses ChatGPT atau LlamaCpp melalui koneksi WebSocket menggunakan dua modul: app/routers/websocket dan app/utils/chat/chat_stream_manager . Modul -modul ini memfasilitasi komunikasi antara klien Flutter dan model obrolan melalui Websocket. Dengan Websocket, Anda dapat membuat saluran komunikasi dua arah yang real-time untuk berinteraksi dengan LLM.
Untuk memulai percakapan, sambungkan ke rute WebSocket /ws/chat/{api_key} dengan kunci API yang valid yang terdaftar di database. Perhatikan bahwa kunci API ini tidak sama dengan kunci API OpenAI, tetapi hanya tersedia untuk server Anda untuk memvalidasi pengguna. Setelah terhubung, Anda dapat mengirim pesan dan perintah untuk berinteraksi dengan model LLM. Websocket akan mengirim kembali tanggapan obrolan secara real-time. Koneksi Websocket ini dibuat melalui Aplikasi Flutter, yang dapat diakses dengan titik akhir /chat .
websocket.py bertanggung jawab untuk menyiapkan koneksi WebSocket dan menangani otentikasi pengguna. Ini mendefinisikan rute WebSocket /chat/{api_key} yang menerima kunci WebSocket dan API sebagai parameter.
Ketika klien terhubung ke WebSocket, pertama -tama memeriksa tombol API untuk mengotentikasi pengguna. Jika kunci API valid, fungsi begin_chat() dipanggil dari modul stream_manager.py untuk memulai percakapan.
Dalam hal kunci API yang tidak terdaftar atau kesalahan yang tidak terduga, pesan yang sesuai dikirim ke klien dan koneksi ditutup.
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.py bertanggung jawab untuk mengelola percakapan dan menangani pesan pengguna. Ini mendefinisikan fungsi begin_chat() , yang mengambil WebSocket, ID pengguna sebagai parameter.
Fungsi pertama -tama menginisialisasi konteks obrolan pengguna dari Cache Manager. Kemudian, ia mengirimkan riwayat pesan awal ke klien melalui Websocket.
Percakapan berlanjut dalam satu loop sampai koneksi ditutup. Selama percakapan, pesan pengguna diproses dan tanggapan GPT dihasilkan sesuai.
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
... Kelas SendToWebsocket digunakan untuk mengirim pesan dan stream ke Websocket. Ini memiliki dua metode: message() dan stream() . Metode message() mengirimkan pesan lengkap ke WebSocket, sedangkan metode stream() mengirimkan aliran ke WebSocket.
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
... Kelas MessageHandler juga menangani respons AI. Metode ai() mengirimkan respons AI ke WebSocket. Jika terjemahan diaktifkan, respons diterjemahkan menggunakan Google Translate API sebelum mengirimkannya ke klien.
class MessageHandler :
...
@ staticmethod
async def ai (...):
... Pesan pengguna diproses menggunakan kelas HandleMessage . Jika pesan dimulai dengan / , seperti /YOUR_CALLBACK_NAME . Ini diperlakukan sebagai perintah dan respons perintah yang tepat dihasilkan. Kalau tidak, pesan pengguna diproses dan dikirim ke model LLM untuk menghasilkan respons.
Perintah ditangani menggunakan kelas ChatCommands . Ini mengeksekusi fungsi callback yang sesuai tergantung pada perintah. Anda dapat menambahkan perintah baru dengan hanya menambahkan callback di kelas ChatCommands dari app.utils.chat.chat_commands .
Menggunakan Redis untuk menyimpan embeddings vektor percakapan? ️ Dapat membantu model chatgpt? Dalam beberapa hal, seperti pengambilan konteks percakapan yang efisien dan cepat ️, menangani sejumlah besar data, dan memberikan tanggapan yang lebih relevan melalui pencarian kesamaan vektor?
Beberapa contoh menyenangkan tentang bagaimana ini bisa bekerja dalam praktik:
/embed Ketika pengguna memasukkan perintah di jendela obrolan seperti /embed <text_to_embed> , metode VectorStoreManager.create_documents dipanggil. Metode ini mengubah teks input menjadi vektor menggunakan model openai text-embedding-ada-002 dan menyimpannya di redis vectorstore.
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../query Ketika pengguna memasukkan perintah /query <query> , fungsi asimilarity_search digunakan untuk menemukan hingga tiga hasil dengan kemiripan vektor tertinggi dengan data tertanam di Redis Vectorstore. Hasil ini disimpan sementara dalam konteks obrolan, yang membantu AI menjawab permintaan dengan merujuk pada data ini.
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
... Saat menjalankan fungsi begin_chat , jika pengguna mengunggah file yang berisi teks (misalnya, file PDF atau TXT), teks secara otomatis diekstraksi dari file, dan embedding vektornya disimpan ke Redis.
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py Di file commands.py , ada beberapa komponen penting:
command_response : Kelas ini digunakan untuk mengatur dekorator pada metode perintah untuk menentukan tindakan berikutnya. Ini membantu untuk mendefinisikan berbagai jenis respons, seperti mengirim pesan dan berhenti, mengirim pesan dan melanjutkan, menangani input pengguna, menangani respons AI, dan banyak lagi.command_handler : Fungsi ini bertanggung jawab untuk melakukan metode callback perintah berdasarkan teks yang dimasukkan oleh pengguna.arguments_provider : Fungsi ini secara otomatis memasok argumen yang diperlukan oleh metode perintah berdasarkan jenis anotasi dari metode perintah.Pemicu Tugas : Fitur ini diaktifkan setiap kali pengguna mengetik pesan atau AI merespons dengan pesan. Pada titik ini, tugas ringkasan otomatis dihasilkan untuk memadatkan konten teks.
Penyimpanan Tugas : Tugas Summarisasi Otomatis kemudian disimpan dalam atribut task_list dari BufferUserChatContext . Ini berfungsi sebagai antrian untuk mengelola tugas yang ditautkan ke konteks obrolan pengguna.
Pemanenan Tugas : Mengikuti penyelesaian siklus tanya umum pengguna-AI oleh MessageHandler , fungsi harvest_done_tasks dipanggil. Fungsi ini mengumpulkan hasil tugas peringkasan, memastikan tidak ada yang ditinggalkan.
Aplikasi Ringkasan : Setelah proses pemanenan, hasil yang diringkas menggantikan pesan yang sebenarnya ketika chatbot kami meminta jawaban dari model pembelajaran bahasa (LLM), seperti OpenAI dan LLAMA_CPP. Dengan melakukan itu, kami dapat mengirim petunjuk yang jauh lebih ringkas daripada pesan panjang awal.
Pengalaman Pengguna : Yang penting, dari perspektif pengguna, mereka hanya melihat pesan asli. Versi pesan yang diringkas tidak ditunjukkan kepada mereka, mempertahankan transparansi dan menghindari potensi kebingungan.
Tugas Simultan : Fitur kunci lain dari tugas pengumuman otomatis ini adalah tidak menghambat tugas-tugas lain. Dengan kata lain, sementara chatbot sibuk merangkum teks, tugas -tugas lain masih dapat dilakukan, sehingga meningkatkan efisiensi keseluruhan chatbot kami.
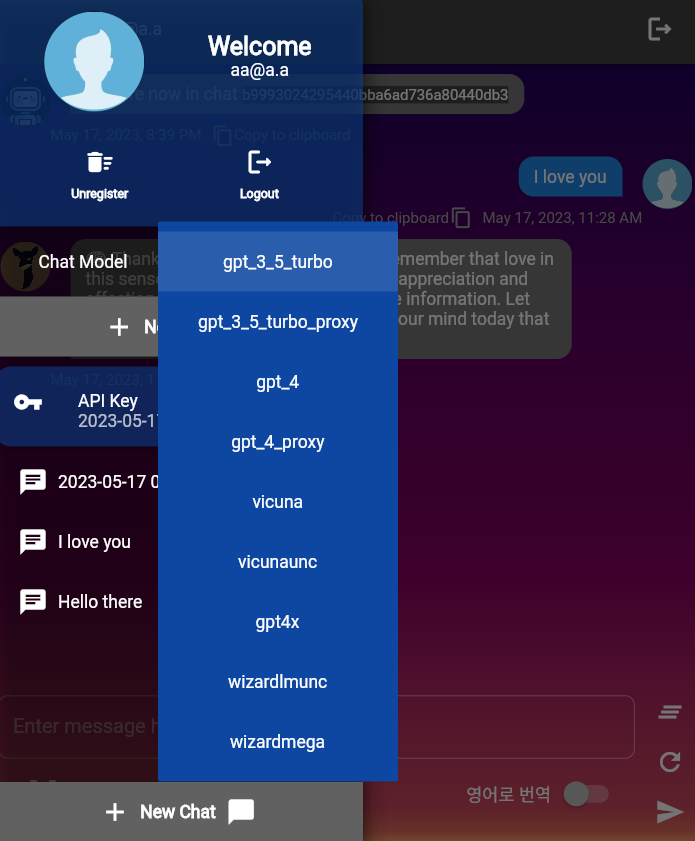
ChatConfig . Repositori ini berisi model LLM yang berbeda, yang didefinisikan dalam llms.py Setiap kelas model LLM mewarisi dari kelas dasar LLMModel . LLMModels Enum adalah kumpulan LLMS ini.
Semua operasi ditangani secara asinkron tanpa menginterupsi utas utama. Namun, LLM lokal tidak dapat menangani banyak permintaan secara bersamaan, karena harganya terlalu mahal. Oleh karena itu, Semaphore digunakan untuk membatasi jumlah permintaan menjadi 1.
Model LLM default yang digunakan oleh pengguna melalui UserChatContext.construct_default adalah gpt-3.5-turbo . Anda dapat mengubah default untuk fungsi itu.
OpenAIModel menghasilkan teks secara asinkron dengan meminta penyelesaian obrolan dari server OpenAI. Ini membutuhkan kunci API OpenAI.
LlamaCppModel membaca model GGML yang disimpan secara lokal. Model Llama.cpp GGML harus dimasukkan ke dalam folder llama_models/ggml sebagai file .bin . Misalnya, jika Anda mengunduh model terkuantisasi Q4_0 dari "https://huggingface.co/thebloke/robin-7b-v2-ggml", jalur model harus menjadi "robin-7b.ggmlv3.q4_0.bin".
ExllamaModel membaca model GPTQ yang disimpan secara lokal. Model Exllama GPTQ harus dimasukkan ke dalam folder llama_models/gptq sebagai folder. Misalnya, jika Anda mengunduh 3 file dari "https://huggingface.co/thebloke/orca_mini_7b-gptq/tree/main":
Maka Anda harus memasukkannya ke dalam folder. Jalur model harus menjadi nama folder. Katakanlah, "orca_mini_7b", yang berisi 3 file.
Menangani pengecualian yang mungkin terjadi selama pembuatan teks. Jika ChatLengthException dilemparkan, secara otomatis melakukan rutin untuk membatasi kembali pesan ke dalam jumlah token yang dibatasi oleh fungsi cutoff_message_histories , dan mengirimkannya. Ini memastikan bahwa pengguna memiliki pengalaman obrolan yang mulus terlepas dari batas token.
Proyek ini bertujuan untuk membuat backend API untuk mengaktifkan layanan chatbot model bahasa besar. Ini menggunakan Cache Manager untuk menyimpan pesan dan profil pengguna di Redis, dan manajer pesan untuk cache dengan aman sehingga jumlah token tidak melebihi batas yang dapat diterima.
Cache Manager ( CacheManager ) bertanggung jawab untuk menangani informasi konteks pengguna dan sejarah pesan. Ini menyimpan data ini di Redis, memungkinkan pengambilan dan modifikasi yang mudah. Manajer menyediakan beberapa metode untuk berinteraksi dengan cache, seperti:
read_context_from_profile : Membaca konteks obrolan pengguna dari Redis, sesuai dengan profil pengguna.create_context : Membuat konteks obrolan pengguna baru di Redis.reset_context : Reset konteks obrolan pengguna ke nilai default.update_message_histories : memperbarui sejarah pesan untuk peran tertentu (pengguna, AI, atau sistem).lpop_message_history / rpop_message_history : menghapus dan mengembalikan riwayat pesan dari ujung kiri atau kanan daftar.append_message_history : Tambahkan riwayat pesan ke akhir daftar.get_message_history : mengambil riwayat pesan untuk peran tertentu.delete_message_history : Hapus riwayat pesan untuk peran tertentu.set_message_history : Mengatur riwayat pesan tertentu untuk peran dan indeks. Manajer pesan ( MessageManager ) memastikan bahwa jumlah token dalam sejarah pesan tidak melebihi batas yang ditentukan. Ini dengan aman menangani penambahan, menghapus, dan mengatur riwayat pesan dalam konteks obrolan pengguna sambil mempertahankan batas token. Manajer menyediakan beberapa metode untuk berinteraksi dengan sejarah pesan, seperti:
add_message_history_safely : Menambahkan riwayat pesan ke konteks obrolan pengguna, memastikan bahwa batas token tidak terlampaui.pop_message_history_safely : Menghapus dan mengembalikan riwayat pesan dari ujung kanan daftar sambil memperbarui jumlah token.set_message_history_safely : Mengatur riwayat pesan tertentu dalam konteks obrolan pengguna, memperbarui jumlah token dan memastikan bahwa batas token tidak terlampaui. Untuk menggunakan Cache Manager dan Manajer Pesan di proyek Anda, impor sebagai berikut:
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManagerKemudian, Anda dapat menggunakan metode mereka untuk berinteraksi dengan cache Redis dan mengelola sejarah pesan sesuai dengan kebutuhan Anda.
Misalnya, untuk membuat konteks obrolan pengguna baru:
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )Untuk dengan aman menambahkan riwayat pesan ke konteks obrolan pengguna:
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role ) Proyek ini menggunakan Middleware token_validator dan Middleware lain yang digunakan dalam aplikasi FASTAPI. Perangkat menengah ini bertanggung jawab untuk mengendalikan akses ke API, memastikan hanya permintaan yang diotorisasi dan diautentikasi diproses.
Perangkat menengah berikut ditambahkan ke aplikasi FASTAPI:
Middleware kontrol akses didefinisikan dalam file token_validator.py . Ini bertanggung jawab untuk memvalidasi tombol API dan token JWT.
Kelas StateManager digunakan untuk menginisialisasi variabel negara meminta. Ini menetapkan waktu permintaan, waktu mulai, alamat IP, dan token pengguna.
Kelas AccessControl berisi dua metode statis untuk memvalidasi tombol API dan token JWT:
api_service : memvalidasi tombol API dengan memeriksa keberadaan parameter kueri yang diperlukan dan header dalam permintaan. Ini memanggil metode Validator.api_key untuk memverifikasi kunci API, rahasia, dan stempel waktu.non_api_service : memvalidasi token JWT dengan memeriksa keberadaan cookie header 'otorisasi' atau 'otorisasi' dalam permintaan. Ini memanggil metode Validator.jwt untuk mendekode dan memverifikasi token JWT. Kelas Validator berisi dua metode statis untuk memvalidasi tombol API dan token JWT:
api_key : Memverifikasi kunci akses API, rahasia hashed, dan cap waktu. Mengembalikan objek UserToken jika validasi berhasil.jwt : Decodes dan memverifikasi token JWT. Mengembalikan objek UserToken jika validasi berhasil. Fungsi access_control adalah fungsi asinkron yang menangani permintaan dan aliran respons untuk middleware. Ini menginisialisasi status permintaan menggunakan kelas StateManager , menentukan jenis otentikasi yang diperlukan untuk URL yang diminta (tombol API atau token JWT), dan memvalidasi otentikasi menggunakan kelas AccessControl . Jika terjadi kesalahan selama proses validasi, pengecualian HTTP yang sesuai dinaikkan.
Utilitas token didefinisikan dalam file token.py . Itu berisi dua fungsi:
create_access_token : Membuat token JWT dengan data dan waktu kedaluwarsa yang diberikan.token_decode : Decodes dan memverifikasi token JWT. Meningkatkan pengecualian jika token sudah kedaluwarsa atau tidak dapat didekodekan. File params_utils.py berisi fungsi utilitas untuk parameter kueri hashing dan kunci rahasia menggunakan HMAC dan SHA256:
hash_params : mengambil parameter kueri dan kunci rahasia sebagai input dan mengembalikan string hash base64 yang dikodekan. File date_utils.py berisi kelas UTC dengan fungsi utilitas untuk bekerja dengan tanggal dan cap waktu:
now : Mengembalikan datetime UTC saat ini dengan perbedaan jam opsional.timestamp : Mengembalikan cap waktu UTC saat ini dengan perbedaan jam opsional.timestamp_to_datetime : Mengubah cap waktu menjadi objek datetime dengan perbedaan jam opsional. File logger.py berisi kelas ApiLogger , yang mencatat informasi permintaan dan respons API, termasuk URL permintaan, metode, kode status, informasi klien, waktu pemrosesan, dan detail kesalahan (jika berlaku). Fungsi logger dipanggil pada akhir fungsi access_control untuk mencatat permintaan dan respons yang diproses.
Untuk menggunakan token_validator Middleware di aplikasi FASTAPI Anda, cukup impor fungsi access_control dan tambahkan sebagai middleware ke instance FASTAPI Anda:
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )Pastikan untuk juga menambahkan COR dan tuan rumah tuan rumah tepercaya untuk kontrol akses lengkap:
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
) Sekarang, setiap permintaan yang masuk ke aplikasi FASTAPI Anda akan diproses oleh token_validator Middleware dan Middleware lainnya, memastikan bahwa hanya permintaan yang diotorisasi dan diautentikasi yang diproses.
Modul ini app.database.connection menyediakan antarmuka yang mudah digunakan untuk mengelola koneksi basis data dan menjalankan kueri SQL menggunakan SQLalchemy dan Redis. Ini mendukung MySQL, dan dapat dengan mudah diintegrasikan dengan proyek ini.
Pertama, impor kelas yang diperlukan dari modul:
from app . database . connection import MySQL , SQLAlchemy , CacheFactory Selanjutnya, buat instance dari kelas SQLAlchemy dan konfigurasikan dengan pengaturan database Anda:
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config ) Sekarang Anda dapat menggunakan instance db untuk menjalankan kueri SQL dan mengelola sesi:
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" ) Untuk menggunakan caching Redis, buat instance kelas CacheFactory dan konfigurasinya dengan pengaturan Redis Anda:
cache = CacheFactory ()
cache . start ( config ) Anda sekarang dapat menggunakan instance cache untuk berinteraksi dengan Redis:
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" ) Bahkan, dalam proyek ini, kelas MySQL melakukan pengaturan awal pada startup aplikasi, dan semua koneksi basis data dibuat dengan hanya variabel db dan cache yang ada di akhir modul. ?
Semua pengaturan DB akan dilakukan di create_app() di app.common.app_settings . Misalnya, fungsi create_app() di app.common.app_settings akan terlihat seperti ini:
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_app Proyek ini menggunakan cara sederhana dan efisien untuk menangani operasi basis data (buat, baca, perbarui, hapus) menggunakan sqlalchemy dan dua modul dan path: app.database.models.schema dan app.database.crud .
Modul schema.py bertanggung jawab untuk mendefinisikan model basis data dan hubungannya menggunakan sqlalchemy. Ini termasuk satu set kelas yang mewarisi dari Base , contoh dari declarative_base() . Setiap kelas mewakili tabel dalam database, dan atributnya mewakili kolom dalam tabel. Kelas -kelas ini juga mewarisi dari kelas Mixin , yang menyediakan beberapa metode dan atribut umum untuk semua model.
Kelas mixin menyediakan beberapa atribut dan metode umum untuk semua kelas yang mewarisi darinya. Beberapa atribut meliputi:
id : Kunci utama integer untuk tabel.created_at : DateTime untuk saat catatan dibuat.updated_at : datetime untuk saat catatan terakhir diperbarui.ip_address : Alamat IP klien yang membuat atau memperbarui catatan.Ini juga menyediakan beberapa metode kelas yang melakukan operasi CRUD menggunakan sqlalchemy, seperti:
add_all() : Menambahkan beberapa catatan ke database.add_one() : Menambahkan satu catatan ke database.update_where() : Pembaruan catatan dalam database berdasarkan filter.fetchall_filtered_by() : Mengambil semua catatan dari database yang cocok dengan filter yang disediakan.one_filtered_by() : Mengambil satu catatan dari database yang cocok dengan filter yang disediakan.first_filtered_by() : Mengambil catatan pertama dari database yang cocok dengan filter yang disediakan.one_or_none_filtered_by() : Mengambil satu catatan atau mengembalikan None jika tidak ada catatan yang cocok dengan filter yang disediakan. Modul users.py dan api_keys.py berisi serangkaian fungsi yang melakukan operasi CRUD menggunakan kelas yang ditentukan dalam schema.py . Fungsi -fungsi ini menggunakan metode kelas yang disediakan oleh kelas mixin untuk berinteraksi dengan database.
Beberapa fungsi dalam modul ini meliputi:
create_api_key() : Membuat kunci API baru untuk pengguna.get_api_keys() : Mengambil semua tombol API untuk pengguna.get_api_key_owner() : Mengambil pemilik kunci API.get_api_key_and_owner() : mengambil kunci API dan pemiliknya.update_api_key() : Memperbarui kunci API.delete_api_key() : Menghapus kunci API.is_email_exist() : Memeriksa apakah ada email dalam database.get_me() : Mengambil informasi pengguna berdasarkan ID pengguna.is_valid_api_key() : Memeriksa apakah kunci API valid.register_new_user() : Mendaftar pengguna baru di database.find_matched_user() : Temukan pengguna dengan email yang cocok di database. Untuk menggunakan operasi CRUD yang disediakan, impor fungsi yang relevan dari modul crud.py dan hubungi mereka dengan parameter yang diperlukan. Misalnya:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())