LLMChat
v1.1.3.4.1
Bienvenido al Repositorio de LLMCHAT, una implementación completa de un servidor API construido con Python Fastapi y un hermoso frontend con Flutter. Este proyecto está diseñado para ofrecer una experiencia de chat perfecta con el ChatGPT avanzado y otros modelos LLM. ? Ofreciendo una infraestructura moderna que se puede extender fácilmente cuando las características multimodales y de complementos de GPT-4 están disponibles. ¡Disfruta de tu estadía!
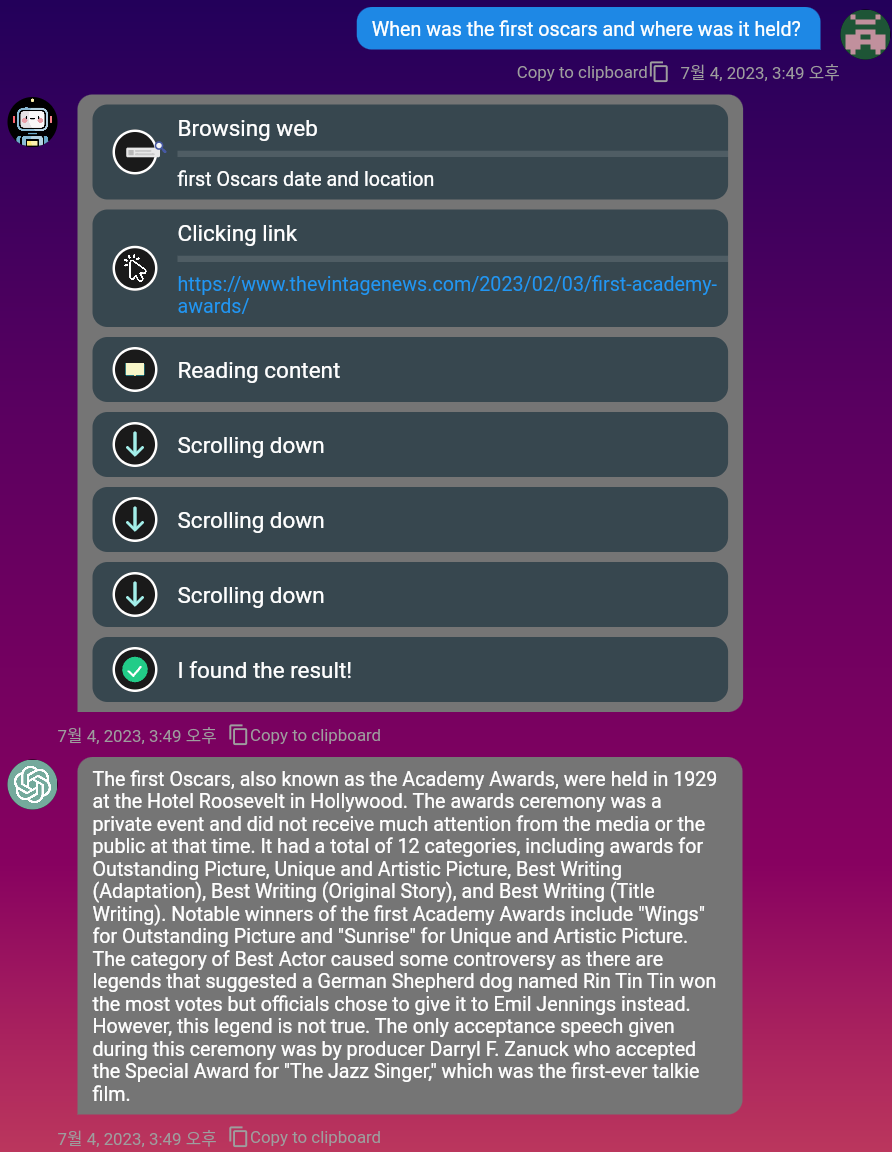
mobile y PC .Markdown también es compatible, por lo que puede usarlo para formatear sus mensajes.Puede usar el motor de búsqueda de Duckduckgo para encontrar información relevante en la web. ¡Simplemente active el botón 'Examinar' de alternancia!
Mire el video de demostración para la navegación completa: https://www.youtube.com/watch?v=mj_cvrwrs08
Con el comando /embed , puede almacenar el texto indefinidamente en su propia base de datos de vectores privados y consultarlo más tarde, en cualquier momento. Si usa el comando /share , el texto se almacena en una base de datos de vectores públicos que todos pueden compartir. Habilitar el botón de alternar Query o el comando /query ayuda a la IA a generar respuestas contextualizadas buscando similitudes de texto en las bases de datos públicas y privadas. Esto resuelve una de las mayores limitaciones de los modelos de idiomas: la memoria .
Puede incrustar el archivo PDF haciendo clic en Embed Document en la parte inferior izquierda. En unos pocos segundos, el contenido de texto de PDF se convertirá en vectores y se incrustará a Redis Cache.
LLMModels que se encuentra en app/models/llms.py . Para el LLALAM LLMS local, se supone que funciona solo en el entorno local y utiliza el punto final http://localhost:8002/v1/completions . Verifica continuamente el estado del servidor API LLAMA conectándose a http://localhost:8002/health una vez por segundo para ver si se devuelve una respuesta de 200 OK, y si no, ejecuta automáticamente un proceso separado para crear un servidor API.
El objetivo principal de Llama.cpp es ejecutar el modelo LLAMA utilizando cuantización GGML de 4 bits con implementación simple de C/C ++ sin dependencias. Debe descargar el archivo GGML bin desde Huggingface y colocarlo en la carpeta llama_models/ggml , y definir LLMMODEL en app/models/llms.py . Hay pocos ejemplos, por lo que puede definir fácilmente su propio modelo. Consulte el repositorio de llama.cpp para obtener más información: https://github.com/ggerganov/llama.cpp
Una implementación independiente de Python/C ++/CUDA de LLAMA para su uso con pesos GPTQ de 4 bits, diseñados para ser rápido y eficiente en la memoria en las GPU modernas. Utiliza pytorch y sentencepiece para ejecutar el modelo. Se supone que funciona solo en el entorno local y se requiere al menos una NVIDIA CUDA GPU . Debe descargar archivos Tokenizer, Config y GPTQ de Huggingface y ponerlo en la carpeta llama_models/gptq/YOUR_MODEL_FOLDER , y definir llmmodel en app/models/llms.py . Hay pocos ejemplos, por lo que puede definir fácilmente su propio modelo. Consulte el repositorio exllama para obtener información más detallada: https://github.com/turboderp/exllama
web framework de alto rendimiento para construir API con Python.Webapp Frontend con una hermosa interfaz de usuario y un rico conjunto de widgets personalizables.OpenAI API para la generación de texto y la gestión de mensajes.LlamaCpp y Exllama Models.Real-time , bidireccional con el CHATGPT y otros modelos LLM, con Flutter Frontend WebApp.Redis y Langchain , almacenar y recuperar incrustaciones de vectores para la búsqueda de similitud. Ayudará a la IA a generar respuestas más relevantes.Duckduckgo , navegue por la web y encuentre información relevante.async / await sintaxis para la concurrencia y el paralelismo.MySQL . Realice fácilmente las acciones Crear, leer, actualizar y eliminar, con sqlalchemy.asyncioRedis con Aioredis. Realice fácilmente las acciones Crear, leer, actualizar y eliminar, con aioredis . Para configurar la máquina local, siga estos simples pasos. Antes de comenzar, asegúrese de tener instalado docker y docker-compose en su máquina. Si desea ejecutar el servidor sin Docker, debe instalar Python 3.11 adicionalmente. Aunque necesitas Docker para ejecutar servidores DB.
Para clonar recursivamente los submódulos para usar modelos Exllama o llama.cpp , use el siguiente comando:
git clone --recurse-submodules https://github.com/c0sogi/llmchat.gitSolo desea usar características principales (OpenAI), use el siguiente comando:
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.env Configurar un archivo ENV, refiriéndose al archivo .env-sample . Ingrese la información de la base de datos para crear, la tecla API de OpenAI y otras configuraciones necesarias. No se requieren opciones, solo déjalas como son.
Ejecutar estos. Puede tomar unos minutos iniciar el servidor por primera vez:
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml down Ahora puede acceder al servidor en http://localhost:8000/docs y la base de datos en db:3306 o cache:6379 . También puede acceder a la aplicación en http://localhost:8000/chat .
Para ejecutar el servidor sin Docker si desea ejecutar el servidor sin Docker, debe instalar Python 3.11 adicionalmente. Aunque necesitas Docker para ejecutar servidores DB. Apague el servidor API que ya se ejecuta con docker-compose -f docker-compose-local.yaml down api . ¡No olvides ejecutar otros servidores DB en Docker! Luego, ejecute los siguientes comandos:
python -m main Su servidor ahora debería estar en funcionamiento en http://localhost:8001 en este caso.
Este proyecto tiene licencia bajo la licencia MIT, que permite un uso gratuito, modificación y distribución, siempre que los derechos de autor originales y el aviso de licencia se incluyan en cualquier copia o porción sustancial del software.
FastAPI es un marco web moderno para construir API con Python. ? Tiene un alto rendimiento, fácil de aprender, rápido para codificar y listo para la producción. ? Una de las características principales de FastAPI es que admite la concurrencia y la sintaxis async / await . ? Esto significa que puede escribir un código que puede manejar múltiples tareas al mismo tiempo sin bloquearse entre sí, especialmente cuando se trata de operaciones vinculadas a E/S, como solicitudes de red, consultas de bases de datos, operaciones de archivos, etc.
Flutter es un kit de herramientas de interfaz de usuario de código abierto desarrollado por Google para construir interfaces de usuarios nativos para plataformas móviles, web y de escritorio a partir de una sola base de código. ? Utiliza Dart , un lenguaje de programación moderno orientado a objetos, y proporciona un rico conjunto de widgets personalizables que pueden adaptarse a cualquier diseño.
Puede acceder ChatGPT o LlamaCpp a través de la conexión WebSocket usando dos módulos: app/routers/websocket y app/utils/chat/chat_stream_manager . Estos módulos facilitan la comunicación entre el cliente Flutter y el modelo de chat a través de un WebSocket. Con WebSocket, puede establecer un canal de comunicación bidireccional en tiempo real para interactuar con el LLM.
Para iniciar una conversación, conéctese a la ruta de WebSocket /ws/chat/{api_key} con una clave API válida registrada en la base de datos. Tenga en cuenta que esta tecla API no es la misma que la clave de API de OpenAI, sino que solo está disponible para su servidor para validar al usuario. Una vez conectado, puede enviar mensajes y comandos para interactuar con el modelo LLM. WebSocket enviará respuestas de chat en tiempo real. Esta conexión WebSocket se establece a través de la aplicación Flutter, que puede acceder con Endpoint /chat .
websocket.py es responsable de configurar una conexión de WebSocket y manejar la autenticación del usuario. Define la ruta /chat/{api_key} de WebSocket que acepta un WebSocket y una clave API como parámetros.
Cuando un cliente se conecta al WebSocket, primero verifica la tecla API para autenticar al usuario. Si la clave API es válida, la función begin_chat() se llama desde el módulo stream_manager.py para iniciar la conversación.
En caso de una clave API no registrada o un error inesperado, se envía un mensaje apropiado al cliente y la conexión está cerrada.
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.py es responsable de administrar la conversación y manejar los mensajes de usuario. Define la función begin_chat() , que toma un WebSocket, un ID de usuario como parámetros.
La función primero inicializa el contexto de chat del usuario desde el Administrador de caché. Luego, envía el historial de mensajes inicial al cliente a través del WebSocket.
La conversación continúa en un bucle hasta que la conexión está cerrada. Durante la conversación, se procesan los mensajes del usuario y las respuestas de GPT se generan en consecuencia.
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
... La clase SendToWebsocket se usa para enviar mensajes y transmisiones al WebSocket. Tiene dos métodos: message() y stream() . El método message() envía un mensaje completo al WebSocket, mientras que el método stream() envía una transmisión al WebSocket.
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
... La clase MessageHandler también maneja las respuestas de AI. El método ai() envía la respuesta AI al WebSocket. Si la traducción está habilitada, la respuesta se traduce utilizando la API de traducción de Google antes de enviarla al cliente.
class MessageHandler :
...
@ staticmethod
async def ai (...):
... Los mensajes de usuario se procesan utilizando la clase HandleMessage . Si el mensaje comienza con / , como /YOUR_CALLBACK_NAME . Se trata como un comando y se genera la respuesta de comando apropiada. De lo contrario, el mensaje del usuario se procesa y se envía al modelo LLM para generar una respuesta.
Los comandos se manejan utilizando la clase ChatCommands . Ejecuta la función de devolución de llamada correspondiente según el comando. Puede agregar nuevos comandos simplemente agregando devolución de llamada en la clase ChatCommands desde app.utils.chat.chat_commands .
¿Usar Redis para almacenar incrustaciones vectoriales de conversaciones? ️ ¿Puede ayudar al modelo CHATGPT? En varias maneras, como la recuperación eficiente y rápida del contexto de conversación ♀️, manejar grandes cantidades de datos y proporcionar respuestas más relevantes a través de la búsqueda de similitud vectorial?
Algunos ejemplos divertidos de cómo esto podría funcionar en la práctica:
/embed Cuando un usuario ingresa a un comando en la ventana de chat como /embed <text_to_embed> , se llama al método VectorStoreManager.create_documents . Este método convierte el texto de entrada en un vector utilizando el modelo text-embedding-ada-002 y lo almacena en Redis Vectorstore.
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../query Cuando el usuario ingresa al comando /query <query> , la función asimilarity_search se usa para encontrar hasta tres resultados con la más alta similitud vectorial con los datos integrados en Redis Vectorstore. Estos resultados se almacenan temporalmente en el contexto del chat, lo que ayuda a AI a responder la consulta al referirse a estos datos.
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
... Al ejecutar la función begin_chat , si un usuario carga un archivo que contiene texto (por ejemplo, un archivo PDF o TXT), el texto se extrae automáticamente del archivo y su incrustación vectorial se guarda en Redis.
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py Funcionalidad En el archivo commands.py , hay varios componentes importantes:
command_response : esta clase se usa para establecer un decorador en el método de comando para especificar la siguiente acción. Ayuda a definir varios tipos de respuesta, como enviar un mensaje y detener, enviar un mensaje y continuar, manejar la entrada del usuario, manejar las respuestas de IA y más.command_handler : esta función es responsable de realizar un método de devolución de llamada de comando basado en el texto ingresado por el usuario.arguments_provider : esta función suministra automáticamente los argumentos requeridos por el método de comando basado en el tipo de anotación del método de comando.Activación de tareas : esta característica se activa cada vez que un usuario escribe un mensaje o la IA responde con un mensaje. En este punto, se genera una tarea de resumen automática para condensar el contenido de texto.
Almacenamiento de tareas : la tarea de auto-sumarización se almacena luego en el atributo task_list del BufferUserChatContext . Esto sirve como una cola para administrar tareas vinculadas al contexto de chat del usuario.
Cosecha de tareas : después de la finalización de un ciclo de preguntas y respuestas del usuario de AI por el MessageHandler , se invoca la función harvest_done_tasks . Esta función recopila los resultados de la tarea de resumen, asegurándose de que no quede nada.
Aplicación de resumen : después del proceso de cosecha, los resultados resumidos reemplazan el mensaje real cuando nuestro chatbot solicita respuestas de los modelos de aprendizaje de idiomas (LLM), como OpenAI y LLAMA_CPP. Al hacerlo, podemos enviar indicaciones mucho más sucintas que el largo mensaje inicial.
Experiencia del usuario : importante, desde la perspectiva del usuario, solo ven el mensaje original. La versión resumida del mensaje no se les muestra, manteniendo la transparencia y evitando la posible confusión.
Tareas simultáneas : otra característica clave de esta tarea automotriz de sumarización es que no impide otras tareas. En otras palabras, mientras el chatbot está ocupado resumiendo el texto, aún se pueden llevar a cabo otras tareas, mejorando así la eficiencia general de nuestro chatbot.
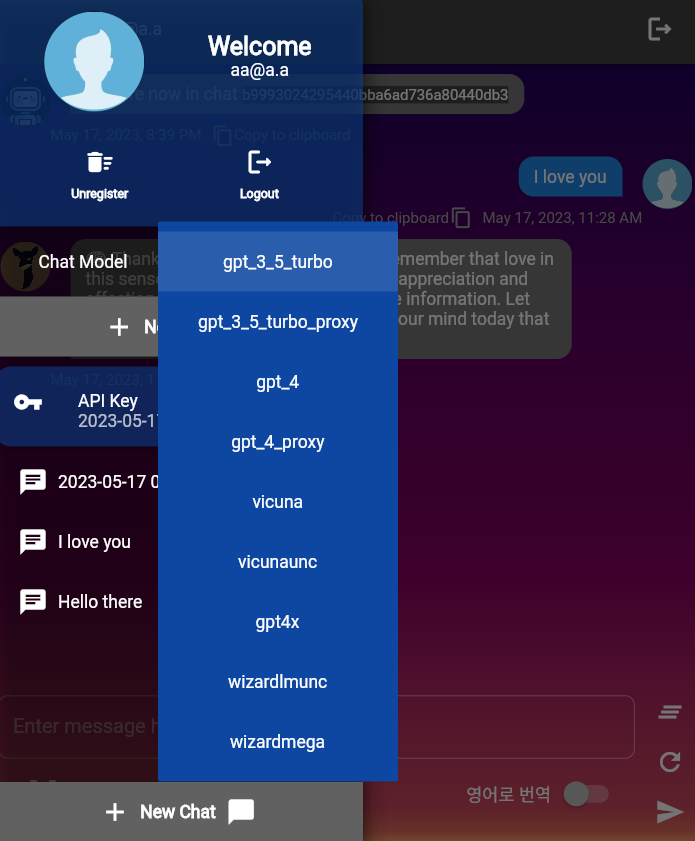
ChatConfig . Este repositorio contiene diferentes modelos LLM, definidos en llms.py Cada clase de modelo LLM hereda de la clase base LLMModel . El LLMModels Enum es una colección de estos LLM.
Todas las operaciones se manejan de manera asincrónica sin interrumpir el hilo principal. Sin embargo, los LLM locales no pueden manejar múltiples solicitudes al mismo tiempo, ya que son demasiado costosos computacionalmente. Por lo tanto, se utiliza un Semaphore para limitar el número de solicitudes a 1.
El modelo LLM predeterminado utilizado por el usuario a través de UserChatContext.construct_default es gpt-3.5-turbo . Puede cambiar el valor predeterminado para esa función.
OpenAIModel genera texto asincrónicamente solicitando la finalización del chat desde el servidor OpenAI. Requiere una tecla API de OpenAI.
LlamaCppModel lee un modelo GGML almacenado localmente. El modelo LLAMA.CPP GGML debe colocarse en la carpeta llama_models/ggml como un archivo .bin . Por ejemplo, si descargó un modelo cuantificado Q4_0 de "https://huggingface.co/thebloke/robin-7b-v2-ggml", la ruta del modelo debe ser "robin-7b.ggmlv3.q4_0.bin".
ExllamaModel leyó un modelo GPTQ almacenado localmente. El modelo Exllama GPTQ debe colocarse en la carpeta llama_models/gptq como carpeta. Por ejemplo, si descargó 3 archivos de "https://huggingface.co/thebloke/orca_mini_7b-gptq/tree/main":
Entonces debes ponerlos en una carpeta. La ruta del modelo tiene que ser el nombre de la carpeta. Digamos, "orca_mini_7b", que contiene los 3 archivos.
Manejar excepciones que pueden ocurrir durante la generación de texto. Si se lanza un ChatLengthException , realiza automáticamente una rutina para re-limitando el mensaje dentro del número de tokens limitados por la función cutoff_message_histories , y reenviarlo. Esto asegura que el usuario tenga una experiencia de chat sin problemas, independientemente del límite de token.
Este proyecto tiene como objetivo crear un backend de API para habilitar el servicio de chatbot de modelo de idioma grande. Utiliza un administrador de caché para almacenar mensajes y perfiles de usuario en Redis, y un administrador de mensajes para almacenar mensajes de forma segura para que el número de tokens no exceda un límite aceptable.
El Cache Manager ( CacheManager ) es responsable de manejar la información del contexto del usuario y los historiales de mensajes. Almacena estos datos en Redis, lo que permite una fácil recuperación y modificación. El administrador proporciona varios métodos para interactuar con el caché, como:
read_context_from_profile : lee el contexto de chat del usuario desde Redis, de acuerdo con el perfil del usuario.create_context : crea un nuevo contexto de chat de usuario en Redis.reset_context : restablece el contexto de chat del usuario a los valores predeterminados.update_message_histories : actualiza los historiales de mensajes para un rol específico (usuario, IA o sistema).lpop_message_history / rpop_message_history : elimina y devuelve el historial de mensajes desde el extremo izquierdo o derecho de la lista.append_message_history : agrega un historial de mensajes al final de la lista.get_message_history : recupera el historial de mensajes para un papel específico.delete_message_history : elimina el historial de mensajes para un rol específico.set_message_history : establece un historial de mensajes específico para un rol e índice. El administrador de mensajes ( MessageManager ) asegura que el número de tokens en los historiales de mensajes no exceda el límite especificado. Maneja de forma segura agregar, eliminar y establecer historias de mensajes en el contexto de chat del usuario mientras mantiene los límites de token. El administrador proporciona varios métodos para interactuar con los historiales de mensajes, como:
add_message_history_safely : agrega un historial de mensajes al contexto de chat del usuario, asegurando que no se exceda el límite del token.pop_message_history_safely : elimina y devuelve el historial de mensajes desde el extremo derecho de la lista al actualizar el recuento de tokens.set_message_history_safely : establece un historial de mensajes específico en el contexto de chat del usuario, actualizando el recuento de tokens y asegurando que no se exceda el límite de token. Para usar el administrador de caché y el administrador de mensajes en su proyecto, importarlos de la siguiente manera:
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManagerLuego, puede usar sus métodos para interactuar con el caché de Redis y administrar los historiales de mensajes de acuerdo con sus requisitos.
Por ejemplo, para crear un nuevo contexto de chat de usuario:
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )Para agregar de forma segura un historial de mensajes al contexto de chat del usuario:
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role ) Este proyecto utiliza token_validator middleware y otros artículos intermedios utilizados en la aplicación Fastapi. Estos artículos intermedios son responsables de controlar el acceso a la API, asegurando que solo se procesen las solicitudes autorizadas y autenticadas.
Los siguientes medios se agregan a la aplicación FastAPI:
El middleware de control de acceso se define en el archivo token_validator.py . Es responsable de validar las teclas API y los tokens JWT.
La clase StateManager se utiliza para inicializar las variables de estado de solicitud. Establece la hora de solicitud, la hora de inicio, la dirección IP y el token de usuario.
La clase AccessControl contiene dos métodos estáticos para validar las claves API y los tokens JWT:
api_service : valida las teclas API verificando la existencia de los parámetros y encabezados de consulta requeridos en la solicitud. Llama al método Validator.api_key para verificar la clave API, el secreto y la marca de tiempo.non_api_service : valida los tokens JWT verificando la existencia del encabezado de 'autorización' o cookie de 'autorización' en la solicitud. Llama al método Validator.jwt para decodificar y verificar el token JWT. La clase Validator contiene dos métodos estáticos para validar las claves API y los tokens JWT:
api_key : verifica la clave de acceso API, el secreto hashed y la marca de tiempo. Devuelve un objeto UserToken si la validación es exitosa.jwt : decodifica y verifica el token JWT. Devuelve un objeto UserToken si la validación es exitosa. La función access_control es una función asincrónica que maneja el flujo de solicitud y respuesta para el middleware. Inicializa el estado de solicitud utilizando la clase StateManager , determina el tipo de autenticación requerida para la URL solicitada (clave API o token JWT) y valida la autenticación utilizando la clase AccessControl . Si se produce un error durante el proceso de validación, se plantea una excepción HTTP apropiada.
Las utilidades del token se definen en el archivo token.py . Contiene dos funciones:
create_access_token : crea un token JWT con los datos y el tiempo de vencimiento dados.token_decode : decodifica y verifica un token JWT. Plantea una excepción si el token está expirado o no se puede decodificar. El archivo params_utils.py contiene una función de utilidad para los parámetros de consulta de hash y la clave secreta usando HMAC y SHA256:
hash_params : Toma los parámetros de consulta y la clave secreta como entrada y devuelve una cadena de hashed codificada Base64. El archivo date_utils.py contiene la clase UTC con funciones de utilidad para trabajar con fechas y marcas de tiempo:
now : devuelve el UTC DateTime actual con una diferencia de hora opcional.timestamp : Devuelve la marca de tiempo UTC actual con una diferencia de hora opcional.timestamp_to_datetime : convierte una marca de tiempo en un objeto DateTime con una diferencia de hora opcional. El archivo logger.py contiene la clase ApiLogger , que registra información de solicitud y respuesta de API, incluida la URL de solicitud, el método, el código de estado, la información del cliente, el tiempo de procesamiento y los detalles de error (si corresponde). La función del registrador se llama al final de la función access_control para registrar la solicitud y la respuesta procesada.
Para usar el middleware token_validator en su aplicación Fastapi, simplemente importe la función access_control y agréguela como un middleware a su instancia de Fastapi:
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )Asegúrese de agregar también el Cors y el host de confianza MiddleWares para el control de acceso completo:
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
) Ahora, cualquier solicitud entrante a su aplicación FastAPI será procesada por el middleware token_validator y otros artículos intermedios, asegurando que solo se procesen las solicitudes autorizadas y autenticadas.
Este módulo app.database.connection proporciona una interfaz fácil de usar para administrar conexiones de bases de datos y ejecutar consultas SQL utilizando SQLalchemy y Redis. Admite MySQL y puede integrarse fácilmente con este proyecto.
Primero, importe las clases requeridas del módulo:
from app . database . connection import MySQL , SQLAlchemy , CacheFactory A continuación, cree una instancia de la clase SQLAlchemy y configúrela con la configuración de su base de datos:
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config ) Ahora puede usar la instancia db para ejecutar consultas SQL y administrar sesiones:
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" ) Para usar el almacenamiento en caché de Redis, cree una instancia de la clase CacheFactory y configúrela con su configuración de Redis:
cache = CacheFactory ()
cache . start ( config ) Ahora puede usar la instancia cache para interactuar con Redis:
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" ) De hecho, en este proyecto, la clase MySQL realiza la configuración inicial en el inicio de la aplicación, y todas las conexiones de la base de datos se realizan solo con las variables db y cache presentes al final del módulo. ?
Todas las configuraciones de DB se realizarán en create_app() en app.common.app_settings . Por ejemplo, la función create_app() en app.common.app_settings se verá así:
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_app Este proyecto utiliza una forma simple y eficiente de manejar las operaciones CRUD (Crear, leer, actualizar, eliminar) con SQLalchemy y dos módulos y rutas: app.database.models.schema y app.database.crud .
El módulo schema.py es responsable de definir modelos de bases de datos y sus relaciones utilizando SQLalchemy. Incluye un conjunto de clases que heredan de Base , una instancia de declarative_base() . Cada clase representa una tabla en la base de datos, y sus atributos representan columnas en la tabla. Estas clases también heredan de una clase Mixin , que proporciona algunos métodos y atributos comunes para todos los modelos.
La clase Mixin proporciona algunos atributos y métodos comunes para todas las clases que heredan de ella. Algunos de los atributos incluyen:
id : clave principal entera para la tabla.created_at : DateTime para cuando se creó el registro.updated_at : dateTime para cuándo se actualizó por última vez el registro.ip_address : dirección IP del cliente que creó o actualizó el registro.También proporciona varios métodos de clase que realizan operaciones CRUD utilizando Sqlalchemy, como:
add_all() : agrega múltiples registros a la base de datos.add_one() : agrega un solo registro a la base de datos.update_where() : actualiza registros en la base de datos basada en un filtro.fetchall_filtered_by() : obtiene todos los registros de la base de datos que coinciden con el filtro proporcionado.one_filtered_by() : obtiene un solo registro de la base de datos que coincide con el filtro proporcionado.first_filtered_by() : obtiene el primer registro de la base de datos que coincide con el filtro proporcionado.one_or_none_filtered_by() : obtiene un solo registro o no devuelve None si ningún registro coincide con el filtro proporcionado. El módulo users.py y api_keys.py contiene un conjunto de funciones que realizan operaciones CRUD utilizando las clases definidas en schema.py . Estas funciones utilizan los métodos de clase proporcionados por la clase Mixin para interactuar con la base de datos.
Algunas de las funciones en este módulo incluyen:
create_api_key() : crea una nueva clave API para un usuario.get_api_keys() : recupera todas las claves API para un usuario.get_api_key_owner() : recupera al propietario de una clave API.get_api_key_and_owner() : recupera una clave API y su propietario.update_api_key() : actualiza una clave API.delete_api_key() : elimina una tecla API.is_email_exist() : Comprueba si existe un correo electrónico en la base de datos.get_me() : recupera la información del usuario según la ID de usuario.is_valid_api_key() : verifica si una clave API es válida.register_new_user() : registra un nuevo usuario en la base de datos.find_matched_user() : encuentra a un usuario con un correo electrónico coincidente en la base de datos. Para utilizar las operaciones CRUD proporcionadas, importe las funciones relevantes del módulo crud.py y llámalas con los parámetros requeridos. Por ejemplo:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())