LLMChat
v1.1.3.4.1
Python Fastapi로 구축 된 API 서버의 풀 스택 구현 및 Flutter로 구동되는 아름다운 프론트 엔드 LLMCHAT 저장소에 오신 것을 환영합니다. 이 프로젝트는 고급 Chatgpt 및 기타 LLM 모델로 완벽한 채팅 경험을 제공하도록 설계되었습니다. ? GPT-4의 멀티 모드 및 플러그인 기능을 사용할 수있을 때 쉽게 확장 할 수있는 최신 인프라를 제공합니다. 숙박을 즐기십시오!
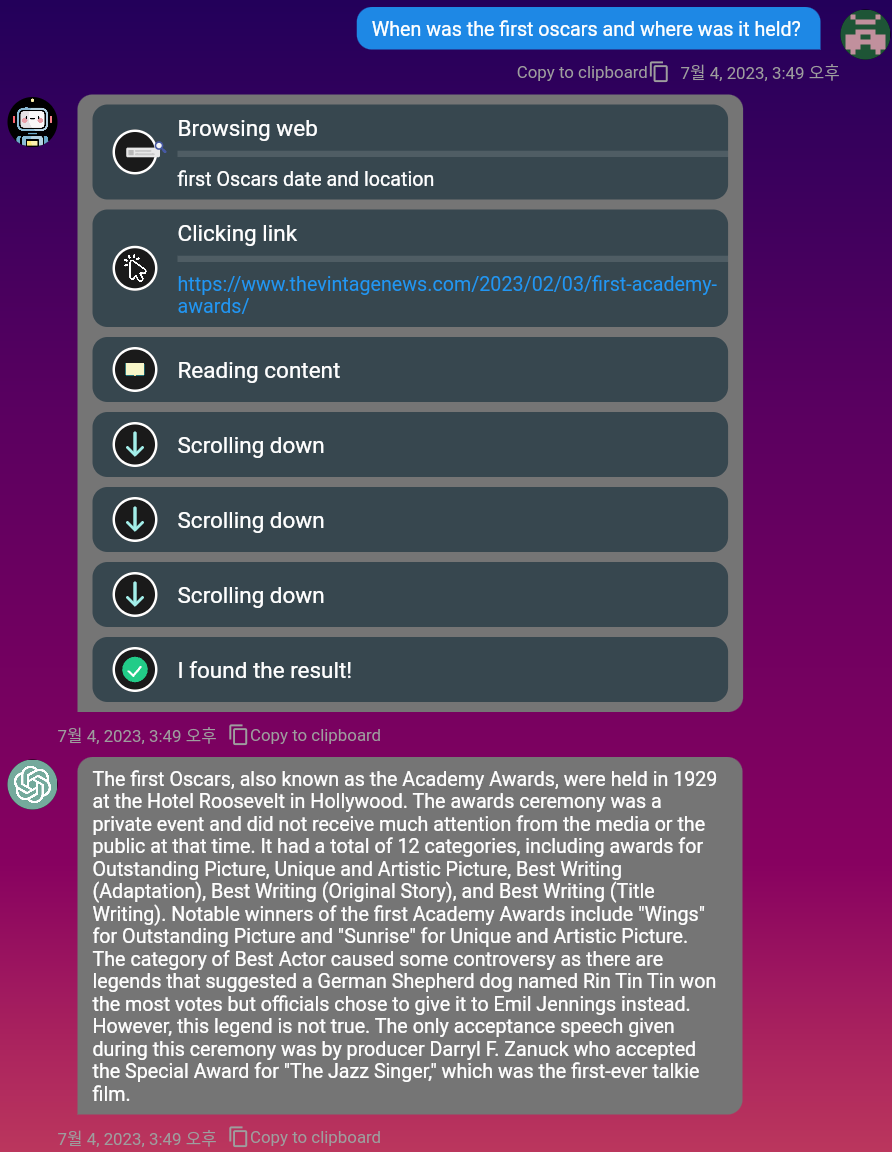
mobile 및 PC 환경을 모두 지원합니다.Markdown 도 지원되므로 메시지를 작성하여 메시지를 작성할 수 있습니다.DuckDuckgo 검색 엔진을 사용하여 웹에서 관련 정보를 찾을 수 있습니다. '찾아보기'토글 버튼을 활성화하십시오!
풀 브라우징의 데모 비디오를 시청하십시오 : https://www.youtube.com/watch?v=mj_cvrwrs08
/embed 명령을 사용하면 텍스트를 자신의 개인 벡터 데이터베이스에 무기한으로 저장하고 나중에 언제든지 쿼리 할 수 있습니다. /share 명령을 사용하는 경우 텍스트는 모든 사람이 공유 할 수있는 공개 벡터 데이터베이스에 저장됩니다. Query 토글 버튼 또는 /query 명령을 활성화하면 AI가 공개 및 개인 데이터베이스에서 텍스트 유사성을 검색하여 상황에 맞는 답변을 생성 할 수 있습니다. 이것은 언어 모델의 가장 큰 한계 중 하나 인 메모리를 해결합니다.
왼쪽 하단에 Embed Document 클릭하여 PDF 파일을 포함시킬 수 있습니다. 몇 초 안에 PDF의 텍스트 내용은 벡터로 변환되고 Redis 캐시에 포함됩니다.
app/models/llms.py 에 위치한 LLMModels 에서 사용하려는 모든 모델을 정의 할 수 있습니다. 로컬 llalam llms의 경우, 지역 환경에서만 작동하는 것으로 가정하며 http://localhost:8002/v1/completions 엔드 포인트를 사용합니다. http://localhost:8002/health 에 한 번 1 초에 연결되어 200 OK 응답이 반환되는지 확인하여 LLAMA API 서버의 상태를 지속적으로 확인합니다. 그렇지 않은 경우 API 서버를 생성하기 위해 별도의 프로세스를 자동으로 실행합니다.
LLAMA.CPP의 주요 목표는 종속성없이 일반 C/C ++ 구현을 사용하여 GGML 4 비트 양자화를 사용하여 LLAMA 모델을 실행하는 것입니다. bin llama_models/ggml app/models/llms.py 예제는 거의 없으므로 자신의 모델을 쉽게 정의 할 수 있습니다. 자세한 내용은 llama.cpp 를 참조하십시오
현대 GPU에서 빠르고 메모리 효율적으로 설계된 4 비트 GPTQ 가중치와 함께 사용하기위한 LLAMA의 독립형 파이썬/C ++/CUDA 구현. pytorch 와 sentencepiece 사용하여 모델을 실행합니다. 지역 환경에서만 작동하는 것으로 가정되며 적어도 하나의 NVIDIA CUDA GPU 필요합니다. llama_models/gptq/YOUR_MODEL_FOLDER app/models/llms.py 예제는 거의 없으므로 자신의 모델을 쉽게 정의 할 수 있습니다. 자세한 내용은 exllama 저장소를 참조하십시오. 자세한 내용은 https://github.com/turboderp/exllama
web framework .Webapp 프론트 엔드.OpenAI API 와의 원활한 통합.LlamaCpp 및 Exllama 모델.Real-timeRedis 및 Langchain 사용하여 유사성 검색을 위해 벡터 임베드를 저장하고 검색합니다. AI가보다 관련성있는 응답을 생성하는 데 도움이됩니다.Duckduckgo 검색 엔진을 사용하여 웹을 탐색하고 관련 정보를 찾으십시오.async / await 구문을 사용한 비동기 프로그래밍.MySQL 쿼리를 실행합니다. sqlalchemy.asyncio 로 작업을 쉽게 수행, 읽기, 업데이트 및 삭제하십시오.Redis 쿼리를 실행하십시오. aioredis 로 작업을 쉽게 수행, 읽기, 업데이트 및 삭제하십시오. 로컬 컴퓨터에서 설정하려면 다음을 수행하십시오. 시작하기 전에 컴퓨터에 docker 와 docker-compose 설치되어 있는지 확인하십시오. Docker없이 서버를 실행하려면 Python 3.11 추가로 설치해야합니다. 그러나 DB 서버를 실행하려면 Docker 필요합니다.
Exllama 또는 llama.cpp 모델을 사용하기 위해 서브 모듈을 재귀 적으로 복제하려면 다음 명령을 사용하십시오.
git clone --recurse-submodules https://github.com/c0sogi/llmchat.git핵심 기능 (OpenAI) 만 사용하려면 다음 명령을 사용합니다.
git clone https://github.com/c0sogi/llmchat.git cd LLMChat.env 파일을 만듭니다 .env-sample 파일을 참조하는 ENV 파일을 설정하십시오. 생성하려면 데이터베이스 정보를 입력하여 OpenAI API 키 및 기타 필요한 구성을 입력하십시오. 선택 사항은 필요하지 않습니다. 그대로 두십시오.
이것들을 실행하십시오. 서버를 처음 시작하는 데 몇 분이 걸릴 수 있습니다.
docker-compose -f docker-compose-local.yaml updocker-compose -f docker-compose-local.yaml down 이제 http://localhost:8000/docs 및 db:3306 또는 cache:6379 의 데이터베이스에서 서버에 액세스 할 수 있습니다. http://localhost:8000/chat 에서 앱에 액세스 할 수도 있습니다.
Docker없이 서버를 실행하려면 Docker없이 서버를 실행하려면 Python 3.11 추가로 설치해야합니다. 그러나 DB 서버를 실행하려면 Docker 필요합니다. docker-compose -f docker-compose-local.yaml down api 로 이미 실행중인 API 서버를 끕니다. Docker에서 다른 DB 서버를 실행하는 것을 잊지 마십시오! 그런 다음 다음 명령을 실행하십시오.
python -m main 이 경우 서버는 이제 http://localhost:8001 에서 실행 중입니다.
이 프로젝트는 MIT 라이센스에 따라 라이센스가 부여되어 원래의 저작권 및 라이센스 통지가 소프트웨어의 모든 사본 또는 실질적인 부분에 포함되어있는 한 무료 사용, 수정 및 배포를 허용합니다.
FastAPI 파이썬으로 API를 구축하기위한 최신 웹 프레임 워크입니다. ? 고성능, 배우기 쉽고, 빠르게 코딩하고, 생산 준비가되어 있습니다. ? FastAPI 의 주요 특징 중 하나는 동시성 및 async / await 구문을 지원한다는 것입니다. ? 즉, 특히 네트워크 요청, 데이터베이스 쿼리, 파일 작업 등과 같은 I/O 바운드 작업을 처리 할 때 서로 차단하지 않고도 여러 작업을 동시에 처리 할 수있는 코드를 작성할 수 있습니다.
Flutter 는 단일 코드베이스에서 모바일, 웹 및 데스크탑 플랫폼 용 기본 사용자 인터페이스를 구축하기 위해 Google에서 개발 한 오픈 소스 UI 툴킷입니다. ?, 최신 객체 지향 프로그래밍 언어 인 Dart 사용하고 모든 디자인에 적응할 수있는 풍부한 사용자 정의 가능한 위젯 세트를 제공합니다.
app/routers/websocket 및 app/utils/chat/chat_stream_manager 두 모듈을 사용하여 WebSocket 연결을 통해 ChatGPT 또는 LlamaCpp 액세스 할 수 있습니다. 이 모듈은 WebSocket을 통해 Flutter 클라이언트와 채팅 모델 간의 통신을 용이하게합니다. WebSocket을 사용하면 LLM과 상호 작용할 수있는 실시간 양방향 통신 채널을 설정할 수 있습니다.
대화를 시작하려면 데이터베이스에 등록 된 유효한 API 키를 사용하여 WebSocket Route /ws/chat/{api_key} 에 연결하십시오. 이 API 키는 OpenAI API 키와 동일하지 않지만 서버에서만 사용할 수 있습니다. 연결되면 LLM 모델과 상호 작용하기 위해 메시지 및 명령을 보낼 수 있습니다. WebSocket은 채팅 응답을 실시간으로 전송합니다. 이 WebSocket 연결은 Flutter App을 통해 설정되어 엔드 포인트 /chat 으로 액세스 할 수 있습니다.
websocket.py 는 WebSocket 연결을 설정하고 사용자 인증을 처리 할 책임이 있습니다. WebSocket Route /chat/{api_key} 를 정의하여 WebSocket과 API 키를 매개 변수로 수락합니다.
클라이언트가 WebSocket에 연결하면 먼저 API 키를 확인하여 사용자를 인증합니다. API 키가 유효 한 경우 begin_chat() 함수가 stream_manager.py 모듈에서 호출되어 대화를 시작합니다.
등록되지 않은 API 키 또는 예기치 않은 오류의 경우 적절한 메시지가 클라이언트로 전송되고 연결이 닫힙니다.
@ router . websocket ( "/chat/{api_key}" )
async def ws_chat ( websocket : WebSocket , api_key : str ):
... stream_manager.py 대화를 관리하고 사용자 메시지를 처리 할 책임이 있습니다. webSocket을 사용자 ID를 매개 변수로 가져 오는 begin_chat() 함수를 정의합니다.
이 기능은 먼저 캐시 관리자의 사용자 채팅 컨텍스트를 초기화합니다. 그런 다음 WebSocket을 통해 초기 메시지 기록을 클라이언트에게 보냅니다.
연결이 닫힐 때까지 대화가 계속됩니다. 대화 중에 사용자의 메시지가 처리되고 GPT의 응답이 그에 따라 생성됩니다.
class ChatStreamManager :
@ classmethod
async def begin_chat ( cls , websocket : WebSocket , user : Users ) -> None :
... SendToWebsocket 클래스는 WebSocket으로 메시지와 스트림을 보내는 데 사용됩니다. message() 와 stream() 두 가지 방법이 있습니다. message() 메소드는 WebSocket에 완전한 메시지를 보내고 stream() 메소드는 WebSocket으로 스트림을 보냅니다.
class SendToWebsocket :
@ staticmethod
async def message (...):
...
@ staticmethod
async def stream (...):
... MessageHandler 클래스는 AI 응답도 처리합니다. ai() 메소드는 AI 응답을 WebSocket에 보냅니다. 번역이 활성화되면 클라이언트로 보내기 전에 Google Translate API를 사용하여 응답이 번역됩니다.
class MessageHandler :
...
@ staticmethod
async def ai (...):
... 사용자 메시지는 HandleMessage Class를 사용하여 처리됩니다. 메시지가 / , 예 : /YOUR_CALLBACK_NAME 과 같이 시작하는 경우. 명령으로 취급되며 적절한 명령 응답이 생성됩니다. 그렇지 않으면 사용자의 메시지가 처리되어 응답을 생성하기 위해 LLM 모델로 전송됩니다.
Commands ChatCommands 를 사용하여 명령이 처리됩니다. 명령에 따라 해당 콜백 함수를 실행합니다. app.utils.chat.chat_commands 의 ChatCommands 클래스에서 콜백을 추가하여 새 명령을 추가 할 수 있습니다.
대화의 벡터 임베딩을 저장하기 위해 Redis를 사용합니까? ️ chatgpt 모델에 도움이 될 수 있습니까? 대화 컨텍스트의 효율적이고 빠른 검색 ♀️, 많은 양의 데이터를 처리하고 벡터 유사성 검색을 통해보다 관련성있는 응답을 제공하는 등 여러 가지면에서?
이것이 실제로 어떻게 작동 할 수 있는지에 대한 몇 가지 재미있는 예 :
/embed 명령을 사용하여 텍스트를 포함시킵니다 사용자가 채팅 창에 /embed <text_to_embed> 에 명령을 입력하면 VectorStoreManager.create_documents 메소드가 호출됩니다. 이 메소드는 OpenAI의 text-embedding-ada-002 모델을 사용하여 입력 텍스트를 벡터로 변환하고이를 Redis VectorStore에 저장합니다.
@ staticmethod
@ command_response . send_message_and_stop
async def embed ( text_to_embed : str , / , buffer : BufferedUserContext ) -> str :
"""Embed the text and save its vectors in the redis vectorstore. n
/embed <text_to_embed>"""
.../query 명령을 사용하여 임베디드 데이터 쿼리 사용자가 /query <query> 명령을 입력하면 asimilarity_search 함수는 Redis 벡터 스토어의 임베디드 데이터와 가장 높은 벡터 유사성을 가진 최대 3 개의 결과를 찾는 데 사용됩니다. 이러한 결과는 채팅의 맥락에서 일시적으로 저장되므로 AI는 이러한 데이터를 참조하여 쿼리에 응답하는 데 도움이됩니다.
@ staticmethod
async def query ( query : str , / , buffer : BufferedUserContext , ** kwargs ) -> Tuple [ str | None , ResponseType ]:
"""Query from redis vectorstore n
/query <query>"""
... begin_chat 함수를 실행할 때 사용자가 텍스트가 포함 된 파일 (예 : PDF 또는 TXT 파일)을 업로드하면 텍스트가 파일에서 자동으로 추출되며 벡터 임베딩이 redis에 저장됩니다.
@ classmethod
async def embed_file_to_vectorstore ( cls , file : bytes , filename : str , collection_name : str ) -> str :
# if user uploads file, embed it
...commands.py 기능 commands.py 파일에는 몇 가지 중요한 구성 요소가 있습니다.
command_response :이 클래스는 다음 조치를 지정하기 위해 명령 메소드에서 데코레이터를 설정하는 데 사용됩니다. 메시지 보내기 및 중지, 메시지 보내기 및 계속해서 사용자 입력 처리, AI 응답 처리 등과 같은 다양한 응답 유형을 정의하는 데 도움이됩니다.command_handler :이 함수는 사용자가 입력 한 텍스트를 기반으로 명령 콜백 메소드를 수행 할 책임이 있습니다.arguments_provider :이 함수는 명령 메소드의 주석 유형에 따라 명령 메소드에 필요한 인수를 자동으로 제공합니다.작업 트리거링 :이 기능은 사용자가 메시지를 입력하거나 AI가 메시지로 응답 할 때마다 활성화됩니다. 이 시점에서 텍스트 내용을 응축하기 위해 자동 요약 작업이 생성됩니다.
Task Storage : Auto-Summarization 작업은 BufferUserChatContext 의 task_list 속성에 저장됩니다. 이는 사용자의 채팅 컨텍스트에 연결된 작업을 관리하기위한 대기열 역할을합니다.
작업 수확 harvest_done_tasks MessageHandler 이 기능은 요약 작업의 결과를 수집하여 아무것도 제외되지 않도록합니다.
요약 응용 프로그램 : 수확 과정 후, 요약 된 결과는 챗봇이 OpenAI 및 LLAMA_CPP와 같은 LLM (Language Learning Models)의 답변을 요청할 때 실제 메시지를 대체합니다. 그렇게함으로써, 우리는 초기 긴 메시지보다 훨씬 더 간결한 프롬프트를 보낼 수 있습니다.
사용자 경험 : 중요한 것은 사용자의 관점에서 원래 메시지 만 볼 수 있습니다. 메시지의 요약 된 버전은 그들에게 표시되지 않아 투명성을 유지하고 잠재적 혼란을 피합니다.
동시 작업 :이 자동 수소화 작업의 또 다른 주요 기능은 다른 작업을 방해하지 않는다는 것입니다. 다시 말해, 챗봇은 텍스트를 요약하는 데 바쁘지만 다른 작업은 여전히 수행 될 수 있으므로 챗봇의 전반적인 효율성을 향상시킬 수 있습니다.
ChatConfig 에서 설정된 임계 값을 설정할 수 있습니다. 이 저장소에는 llms.py 에 정의 된 다른 LLM 모델이 포함되어 있습니다. 각 LLM 모델 클래스는 기본 클래스 LLMModel 에서 상속됩니다. LLMModels enum은 이러한 LLM의 모음입니다.
모든 작업은 기본 스레드를 상호 작용하지 않고 비동기 적으로 처리됩니다. 그러나 로컬 LLM은 계산적으로 비싸기 때문에 여러 요청을 동시에 처리 할 수 없습니다. 따라서 Semaphore 요청 수를 1으로 제한하는 데 사용됩니다.
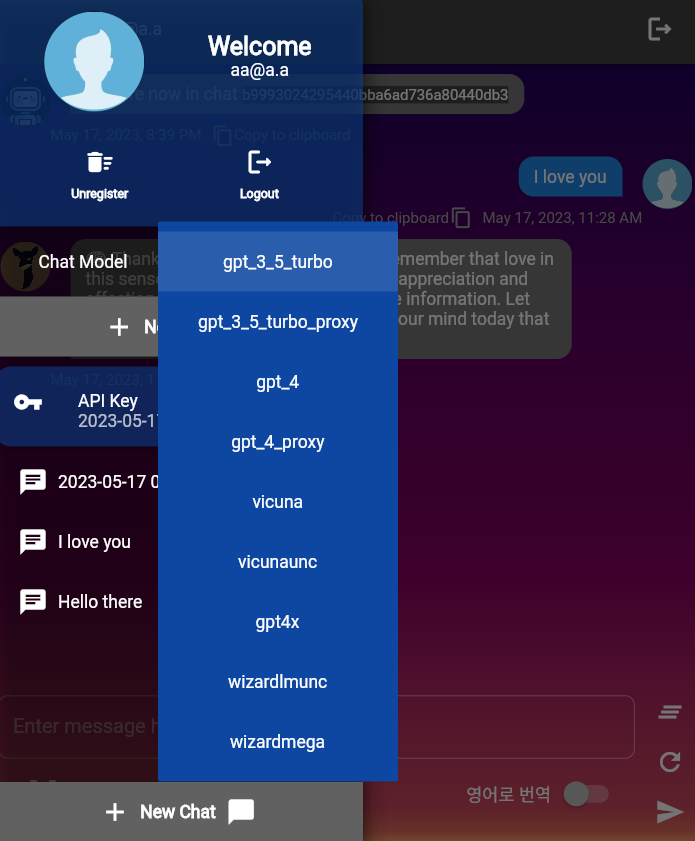
UserChatContext.construct_default 를 통해 사용자가 사용하는 기본 LLM 모델은 gpt-3.5-turbo 입니다. 해당 함수의 기본값을 변경할 수 있습니다.
OpenAIModel OpenAI 서버에서 채팅 완료를 요청하여 텍스트를 비동기 적으로 생성합니다. OpenAI API 키가 필요합니다.
LlamaCppModel 로컬로 저장된 GGML 모델을 읽습니다. llama.cpp ggml 모델은 llama_models/ggml 폴더에 .bin 파일로 넣어야합니다. 예를 들어, "https://huggingface.co/thebloke/robin-7b-v2-ggml"에서 Q4_0 양자화 된 모델을 다운로드 한 경우 모델의 경로는 "Robin-7b.ggmlv3.q4_0.bin"이어야합니다.
ExllamaModel 로컬로 저장된 GPTQ 모델을 읽으십시오. exllama gptq 모델은 llama_models/gptq 폴더에 폴더로 넣어야합니다. 예를 들어, "https://huggingface.co/thebloke/orca_mini_7b-gptq/tree/main에서 3 개의 파일을 다운로드 한 경우 :
그런 다음 폴더에 넣어야합니다. 모델의 경로는 폴더 이름이어야합니다. 3 개의 파일이 포함 된 "Orca_Mini_7B"라고 가정 해 봅시다.
텍스트 생성 중에 발생할 수있는 예외를 처리합니다. ChatLengthException 이 발생하면 cutoff_message_histories 함수에 의해 제한된 토큰 수 내에서 메시지를 다시 제한하는 루틴을 자동으로 수행하고 재판매합니다. 이를 통해 사용자는 토큰 제한에 관계없이 부드러운 채팅 경험을 보장합니다.
이 프로젝트는 대형 언어 모델 챗봇 서비스를 활성화하기 위해 API 백엔드를 작성하는 것을 목표로합니다. Cache Manager를 사용하여 Redis에 메시지 및 사용자 프로필을 저장하고 메시지 관리자가 메시지를 안전하게 캐시하여 토큰 수가 허용 가능한 한계를 초과하지 않도록합니다.
Cache Manager ( CacheManager )는 사용자 컨텍스트 정보 및 메시지 이력을 처리 할 책임이 있습니다. 이 데이터를 Redis에 저장하여 쉽게 검색하고 수정할 수 있습니다. 관리자는 다음과 같은 캐시와 상호 작용하는 몇 가지 방법을 제공합니다.
read_context_from_profile : 사용자의 프로필에 따라 Redis에서 사용자의 채팅 컨텍스트를 읽습니다.create_context : redis에서 새로운 사용자 채팅 컨텍스트를 만듭니다.reset_context : 사용자의 채팅 컨텍스트를 기본값으로 재설정합니다.update_message_histories : 특정 역할 (사용자, AI 또는 시스템)에 대한 메시지 이력을 업데이트합니다.lpop_message_history / rpop_message_history : 목록의 왼쪽 또는 오른쪽 끝에서 메시지 기록을 제거하고 반환합니다.append_message_history : 목록 끝에 메시지 기록을 추가합니다.get_message_history : 특정 역할에 대한 메시지 기록을 검색합니다.delete_message_history : 특정 역할에 대한 메시지 기록을 삭제합니다.set_message_history : 역할 및 색인에 대한 특정 메시지 기록을 설정합니다. 메시지 관리자 ( MessageManager )는 메시지 이력의 토큰 수가 지정된 한계를 초과하지 않도록합니다. 토큰 제한을 유지하면서 사용자의 채팅 컨텍스트에서 메시지 이력을 추가, 제거 및 설정하는 것을 안전하게 처리합니다. 관리자는 다음과 같은 메시지 이력과 상호 작용하는 몇 가지 방법을 제공합니다.
add_message_history_safely : 사용자의 채팅 컨텍스트에 메시지 기록을 추가하여 토큰 제한이 초과되지 않도록합니다.pop_message_history_safely : 토큰 수를 업데이트하면서 목록의 오른쪽 끝에서 메시지 기록을 제거하고 반환합니다.set_message_history_safely : 사용자의 채팅 컨텍스트에서 특정 메시지 기록을 설정하여 토큰 수를 업데이트하고 토큰 제한이 초과되지 않도록합니다. 프로젝트에서 캐시 관리자 및 메시지 관리자를 사용하려면 다음과 같이 가져옵니다.
from app . utils . chat . managers . cache import CacheManager
from app . utils . chat . message_manager import MessageManager그런 다음 방법을 사용하여 Redis 캐시와 상호 작용하고 요구 사항에 따라 메시지 이력을 관리 할 수 있습니다.
예를 들어, 새로운 사용자 채팅 컨텍스트를 작성하려면 다음과 같습니다.
user_id = "[email protected]" # email format
chat_room_id = "example_chat_room_id" # usually the 32 characters from `uuid.uuid4().hex`
default_context = UserChatContext . construct_default ( user_id = user_id , chat_room_id = chat_room_id )
await CacheManager . create_context ( user_chat_context = default_context )사용자의 채팅 컨텍스트에 메시지 기록을 안전하게 추가하려면 다음과 같습니다.
user_chat_context = await CacheManager . read_context_from_profile ( user_chat_profile = UserChatProfile ( user_id = user_id , chat_room_id = chat_room_id ))
content = "This is a sample message."
role = ChatRoles . USER # can be enum such as ChatRoles.USER, ChatRoles.AI, ChatRoles.SYSTEM
await MessageManager . add_message_history_safely ( user_chat_context , content , role ) 이 프로젝트는 token_validator 미들웨어 및 Fastapi 응용 프로그램에 사용되는 기타 중간 전쟁을 사용합니다. 이 중간 전위는 API에 대한 액세스를 제어하여 승인 및 인증 요청 만 처리되도록합니다.
다음 중간 전야는 Fastapi 응용 프로그램에 추가됩니다.
액세스 제어 미들웨어는 token_validator.py 파일에 정의됩니다. API 키와 JWT 토큰을 검증 할 책임이 있습니다.
StateManager 클래스는 요청 상태 변수를 초기화하는 데 사용됩니다. 요청 시간, 시작 시간, IP 주소 및 사용자 토큰을 설정합니다.
AccessControl 클래스에는 API 키와 JWT 토큰을 검증하기위한 두 가지 정적 메소드가 포함되어 있습니다.
api_service : 요청에 필요한 쿼리 매개 변수 및 헤더의 존재를 확인하여 API 키를 확인합니다. API 키, 비밀 및 타임 스탬프를 확인하기 위해 Validator.api_key 메소드를 호출합니다.non_api_service : 요청에 '인증'헤더 또는 '인증'쿠키의 존재를 확인하여 JWT 토큰을 확인합니다. JWT 토큰을 디코딩하고 확인하기 위해 Validator.jwt 메서드를 호출합니다. Validator 클래스에는 API 키와 JWT 토큰을 검증하기위한 두 가지 정적 메소드가 포함되어 있습니다.
api_key : API 액세스 키, 해시 비밀 및 타임 스탬프를 확인합니다. 유효성 검사가 성공하면 UserToken 객체를 반환합니다.jwt : JWT 토큰을 디코딩하고 검증합니다. 유효성 검사가 성공하면 UserToken 객체를 반환합니다. access_control 함수는 미들웨어의 요청 및 응답 흐름을 처리하는 비동기 기능입니다. StateManager 클래스를 사용하여 요청 상태를 초기화하고 요청 된 URL (API 키 또는 JWT 토큰)에 필요한 인증 유형을 결정하고 AccessControl 클래스를 사용하여 인증을 확인합니다. 유효성 검사 프로세스 중에 오류가 발생하면 적절한 HTTP 예외가 제기됩니다.
토큰 유틸리티는 token.py 파일에 정의됩니다. 두 가지 기능이 포함되어 있습니다.
create_access_token : 주어진 데이터와 만료 시간으로 JWT 토큰을 만듭니다.token_decode : DECODES 및 JWT 토큰을 검증합니다. 토큰이 만료되거나 디코딩 될 수없는 경우 예외를 제기합니다. params_utils.py 파일에는 HMAC 및 SHA256을 사용하여 해싱 쿼리 매개 변수와 비밀 키에 대한 유틸리티 기능이 포함되어 있습니다.
hash_params : 쿼리 매개 변수와 비밀 키를 입력으로 가져 와서 Base64 인코딩 된 해시 스트링을 반환합니다. date_utils.py 파일에는 날짜 및 타임 스탬프 작업을위한 유틸리티 함수가 포함 된 UTC 클래스가 포함되어 있습니다.
now : 선택적인 시간 차이로 현재 UTC DateTime을 반환합니다.timestamp : 선택적인 시간 차이로 현재 UTC 타임 스탬프를 반환합니다.timestamp_to_datetime : 선택적인 시간 차이로 timestamp를 dateTime 객체로 변환합니다. logger.py 파일에는 ApiLogger 클래스가 포함되어 있으며,이 API 요청 및 요청 URL, 메소드, 상태 코드, 클라이언트 정보, 처리 시간 및 오류 세부 정보 (해당되는 경우)를 포함하여 API 요청 및 응답 정보를 기록합니다. 로거 함수는 access_control 함수의 끝에서 호출되어 처리 된 요청 및 응답을 기록합니다.
FastApi 응용 프로그램에서 token_validator 미들웨어를 사용하려면 access_control 함수를 가져 와서 FastApi 인스턴스에 미들웨어로 추가하십시오.
from app . middlewares . token_validator import access_control
app = FastAPI ()
app . add_middleware ( dispatch = access_control , middleware_class = BaseHTTPMiddleware )완전한 액세스 제어를 위해 CORS 및 신뢰할 수있는 호스트 중간 전 세계를 추가하십시오.
app . add_middleware (
CORSMiddleware ,
allow_origins = config . allowed_sites ,
allow_credentials = True ,
allow_methods = [ "*" ],
allow_headers = [ "*" ],
)
app . add_middleware (
TrustedHostMiddleware ,
allowed_hosts = config . trusted_hosts ,
except_path = [ "/health" ],
) 이제 FASTAPI 애플리케이션에 대한 모든 요청은 token_validator Middleware 및 기타 중간 전쟁에 의해 처리되므로 승인 및 인증 요청 만 처리되도록합니다.
이 모듈 app.database.connection SQLALCHEMY 및 REDIS를 사용하여 데이터베이스 연결을 관리하고 SQL 쿼리를 실행하기위한 사용하기 쉬운 인터페이스를 제공합니다. MySQL을 지원 하며이 프로젝트와 쉽게 통합 될 수 있습니다.
먼저 모듈에서 필요한 클래스를 가져옵니다.
from app . database . connection import MySQL , SQLAlchemy , CacheFactory 다음으로 SQLAlchemy 클래스의 인스턴스를 작성하여 데이터베이스 설정으로 구성하십시오.
from app . common . config import Config
config : Config = Config . get ()
db = SQLAlchemy ()
db . start ( config ) 이제 db 인스턴스를 사용하여 SQL 쿼리를 실행하고 세션을 관리 할 수 있습니다.
# Execute a raw SQL query
result = await db . execute ( "SELECT * FROM users" )
# Use the run_in_session decorator to manage sessions
@ db . run_in_session
async def create_user ( session , username , password ):
await session . execute ( "INSERT INTO users (username, password) VALUES (:username, :password)" , { "username" : username , "password" : password })
await create_user ( "JohnDoe" , "password123" ) Redis Caching을 사용하려면 CacheFactory 클래스의 인스턴스를 작성하여 Redis 설정으로 구성하십시오.
cache = CacheFactory ()
cache . start ( config ) 이제 cache 인스턴스를 사용하여 redis와 상호 작용할 수 있습니다.
# Set a key in Redis
await cache . redis . set ( "my_key" , "my_value" )
# Get a key from Redis
value = await cache . redis . get ( "my_key" ) 실제로이 프로젝트에서 MySQL 클래스는 앱 시작에서 초기 설정을 수행하며 모든 데이터베이스 연결은 모듈 끝에있는 db 및 cache 변수만으로 만들어집니다. ?
모든 DB 설정은 app.common.app_settings 의 create_app() 에서 수행됩니다. 예를 들어, app.common.app_settings 의 create_app() 함수는 다음과 같습니다.
def create_app ( config : Config ) -> FastAPI :
# Initialize app & db & js
new_app = FastAPI (
title = config . app_title ,
description = config . app_description ,
version = config . app_version ,
)
db . start ( config = config )
cache . start ( config = config )
js_url_initializer ( js_location = "app/web/main.dart.js" )
# Register routers
# ...
return new_app 이 프로젝트 app.database.crud 간단하고 효율적인 방법을 사용하여 app.database.models.schema 및 두 가지 모듈을 사용하여 데이터베이스 CRUD (작성, 읽기, 업데이트, 삭제) 작업을 처리합니다.
schema.py 모듈은 SQLALCHEMY를 사용하여 데이터베이스 모델과 관계를 정의 할 책임이 있습니다. 여기에는 Base 에서 상속되는 클래스 세트, declarative_base() 의 인스턴스가 포함됩니다. 각 클래스는 데이터베이스의 테이블을 나타내며 속성은 테이블의 열을 나타냅니다. 이 클래스는 또한 Mixin 클래스에서 상속되어 모든 모델에 대한 몇 가지 일반적인 방법과 속성을 제공합니다.
Mixin 클래스는 상속받는 모든 클래스에 대한 몇 가지 일반적인 속성과 방법을 제공합니다. 일부 속성에는 다음이 포함됩니다.
id : 테이블의 정수 기본 키.created_at : 레코드가 만들어 졌을 때 DateTime.updated_at : 레코드가 마지막으로 업데이트 된 경우 DateTime.ip_address : 레코드를 생성하거나 업데이트 한 클라이언트의 IP 주소.또한 SQLALCHEMY를 사용하여 CRUD 작업을 수행하는 몇 가지 클래스 방법을 제공합니다.
add_all() : 데이터베이스에 여러 레코드를 추가합니다.add_one() : 데이터베이스에 단일 레코드를 추가합니다.update_where() : 필터를 기반으로 데이터베이스의 레코드를 업데이트합니다.fetchall_filtered_by() : 제공된 필터와 일치하는 데이터베이스에서 모든 레코드를 가져옵니다.one_filtered_by() : 제공된 필터와 일치하는 데이터베이스에서 단일 레코드를 가져옵니다.first_filtered_by() : 제공된 필터와 일치하는 데이터베이스에서 첫 번째 레코드를 가져옵니다.one_or_none_filtered_by() : 단일 레코드를 가져 오거나 레코드가 제공되지 않은 경우 제공된 필터와 일치하는 경우 None 반환합니다. users.py 및 api_keys.py 모듈에는 schema.py 에 정의 된 클래스를 사용하여 CRUD 작업을 수행하는 기능 세트가 포함되어 있습니다. 이 기능은 Mixin 클래스가 제공하는 클래스 방법을 사용하여 데이터베이스와 상호 작용합니다.
이 모듈의 일부 기능에는 다음이 포함됩니다.
create_api_key() : 사용자를위한 새 API 키를 만듭니다.get_api_keys() : 사용자의 모든 API 키를 검색합니다.get_api_key_owner() : API 키의 소유자를 검색합니다.get_api_key_and_owner() : API 키와 소유자를 검색합니다.update_api_key() : API 키를 업데이트합니다.delete_api_key() : API 키를 삭제합니다.is_email_exist() : 데이터베이스에 이메일이 있는지 확인합니다.get_me() : 사용자 ID를 기반으로 사용자 정보를 검색합니다.is_valid_api_key() : API 키가 유효한지 확인합니다.register_new_user() : 데이터베이스에 새 사용자를 등록합니다.find_matched_user() : 데이터베이스에서 이메일이 일치하는 사용자를 찾습니다. 제공된 CRUD 작업을 사용하려면 crud.py 모듈에서 관련 기능을 가져와 필요한 매개 변수로 호출하십시오. 예를 들어:
import asyncio
from app . database . crud . users import register_new_user , get_me , is_email_exist
from app . database . crud . api_keys import create_api_key , get_api_keys , update_api_key , delete_api_key
async def main ():
# `user_id` is an integer index in the MySQL database, and `email` is user's actual name
# the email will be used as `user_id` in chat. Don't confuse with `user_id` in MySQL
# Register a new user
new_user = await register_new_user ( email = "[email protected]" , hashed_password = "..." )
# Get user information
user = await get_me ( user_id = 1 )
# Check if an email exists in the database
email_exists = await is_email_exist ( email = "[email protected]" )
# Create a new API key for user with ID 1
new_api_key = await create_api_key ( user_id = 1 , additional_key_info = { "user_memo" : "Test API Key" })
# Get all API keys for user with ID 1
api_keys = await get_api_keys ( user_id = 1 )
# Update the first API key in the list
updated_api_key = await update_api_key ( updated_key_info = { "user_memo" : "Updated Test API Key" }, access_key_id = api_keys [ 0 ]. id , user_id = 1 )
# Delete the first API key in the list
await delete_api_key ( access_key_id = api_keys [ 0 ]. id , access_key = api_keys [ 0 ]. access_key , user_id = 1 )
if __name__ == "__main__" :
asyncio . run ( main ())