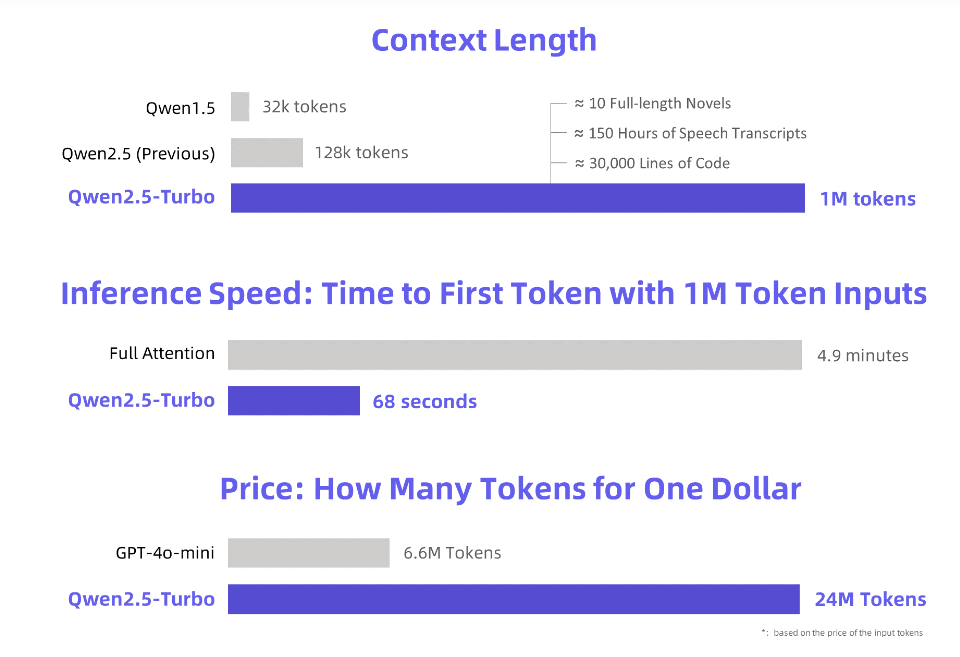
The editor of Downcodes learned that Alibaba Cloud has released a newly upgraded Qwen2.5-Turbo large language model, and its context length has reached an astonishing 1 million Tokens! What does this mean? This means it can process an amount of information equivalent to 10 "Three Body" novels, 150 hours of voice, or 30,000 lines of code! Such powerful processing power will revolutionize the way we interact with large language models.
Alibaba Cloud launches the newly upgraded Qwen2.5-Turbo large language model, whose context length exceeds an astonishing 1 million Tokens. What is the equivalent of this concept? It is equivalent to 10 "Three Body" novels, 150 hours of voice transcription or 30,000 lines of code capacity! This time, "reading ten novels in one breath" is no longer a dream!
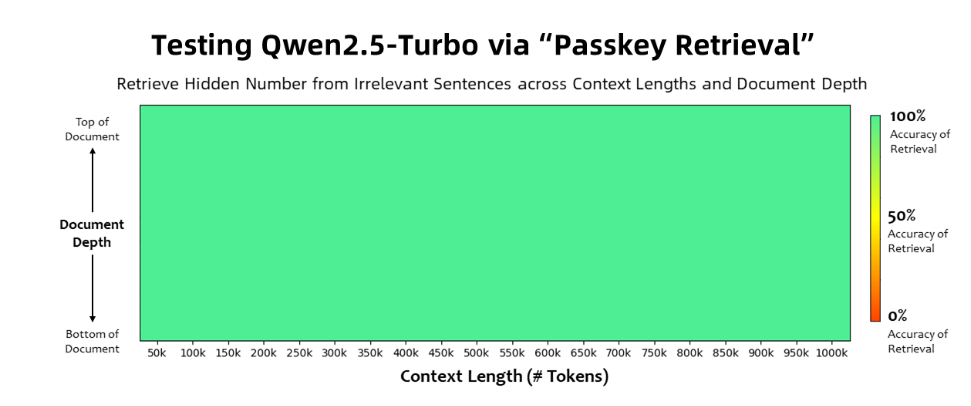
The Qwen2.5-Turbo model achieved 100% accuracy in the Passkey Retrieval task, and surpassed similar models such as GPT-4 in terms of long text understanding capabilities. The model achieved a high score of 93.1 on the RULER long text benchmark, while GPT-4 scored only 91.6 and GLM4-9B-1M scored 89.9.
In addition to ultra-long text processing capabilities, Qwen2.5-Turbo also has the accuracy of short text processing. In the short text benchmark test, its performance is comparable to the GPT-4o-mini and Qwen2.5-14B-Instruct models.
By adopting the sparse attention mechanism, the Qwen2.5-Turbo model shortens the first token processing time of 1 million Tokens from 4.9 minutes to 68 seconds, achieving a 4.3-fold increase in inference speed.
At the same time, the cost of processing 1 million Tokens is only 0.3 yuan. Compared with GPT-4o-mini, it can process 3.6 times the content at the same cost.
Alibaba Cloud has prepared a series of demonstrations for the Qwen2.5-Turbo model, showing its application in in-depth understanding of novels, code assistance, and reading of multiple papers. For example, after a user uploaded the Chinese novel "The Three-Body Problem" trilogy containing 690,000 tokens, the model successfully summarized the plot of each novel in English.
Users can experience the powerful functions of the Qwen2.5-Turbo model through the API service of Alibaba Cloud Model Studio, HuggingFace Demo or ModelScope Demo.
Alibaba Cloud stated that in the future, it will continue to optimize the model to improve its human preference alignment in long sequence tasks, further optimize inference efficiency, reduce computing time, and try to launch a larger and stronger long context model.
Official introduction: https://qwenlm.github.io/blog/qwen2.5-turbo/
Online demo: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
API documentation: https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen
The emergence of Qwen2.5-Turbo marks a major breakthrough in the long text processing capabilities of large language models. Its high efficiency and low cost will bring huge application potential to all walks of life. Let’s wait and see how this powerful model will change our world in the future!