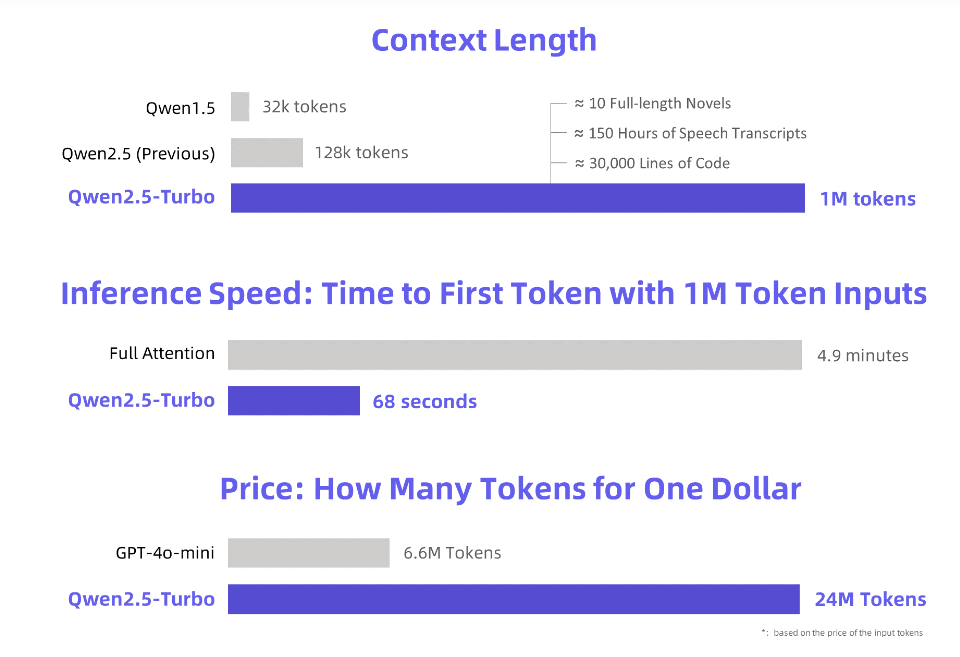
บรรณาธิการของ Downcodes ได้เรียนรู้ว่า Alibaba Cloud ได้เปิดตัวโมเดลภาษาขนาดใหญ่ Qwen2.5-Turbo ที่ได้รับการอัปเกรดใหม่ และความยาวบริบทของโมเดลก็สูงถึง 1 ล้านโทเค็นอย่างน่าประหลาดใจ! สิ่งนี้หมายความว่าอย่างไร? ซึ่งหมายความว่าสามารถประมวลผลข้อมูลจำนวนเทียบเท่ากับนวนิยาย "Three Body" 10 เล่ม เสียง 150 ชั่วโมง หรือโค้ด 30,000 บรรทัด! พลังการประมวลผลอันทรงพลังดังกล่าวจะปฏิวัติวิธีที่เราโต้ตอบกับโมเดลภาษาขนาดใหญ่
Alibaba Cloud เปิดตัวโมเดลภาษาขนาดใหญ่ Qwen2.5-Turbo ที่ได้รับการอัพเกรดใหม่ ซึ่งมีความยาวบริบทเกินกว่า 1 ล้านโทเค็นอย่างน่าประหลาดใจ อะไรจะเทียบเท่ากับนิยาย "สามร่าง" 10 เล่ม การถอดเสียง 150 ชั่วโมง หรือความจุโค้ด 30,000 บรรทัด ครั้งนี้ "อ่านนิยาย 10 เล่มในหนึ่งลมหายใจ" ไม่ใช่ความฝันอีกต่อไป!
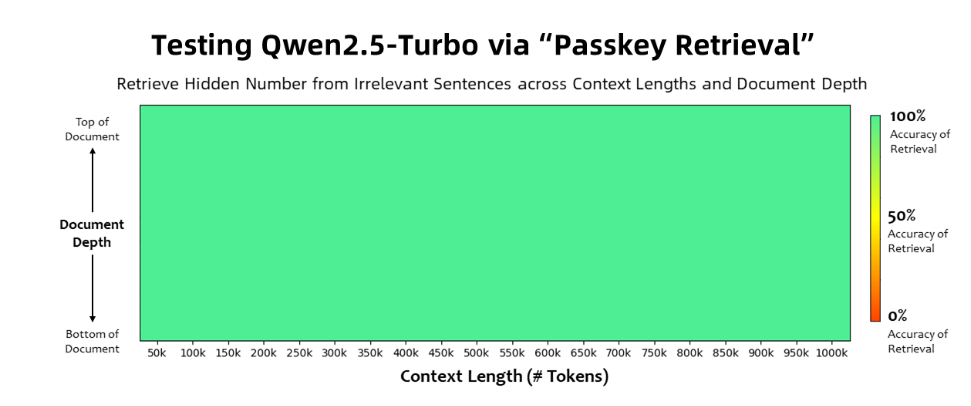
รุ่น Qwen2.5-Turbo ได้รับความแม่นยำ 100% ในงานดึงรหัสผ่าน และเหนือกว่ารุ่นที่คล้ายกัน เช่น GPT-4 ในแง่ของความสามารถในการทำความเข้าใจข้อความขนาดยาว โมเดลดังกล่าวได้รับคะแนนสูงถึง 93.1 ในเกณฑ์มาตรฐานข้อความยาวของ RULER ในขณะที่ GPT-4 ได้คะแนนเพียง 91.6 และ GLM4-9B-1M ได้คะแนน 89.9
นอกจากความสามารถในการประมวลผลข้อความที่ยาวเป็นพิเศษแล้ว Qwen2.5-Turbo ยังมีความแม่นยำในการประมวลผลข้อความสั้นอีกด้วย ในการทดสอบเกณฑ์มาตรฐานข้อความสั้น ประสิทธิภาพเทียบได้กับ GPT-4o-mini และ Qwen2.5-14B-Instruct โมเดล
ด้วยการใช้กลไกการใส่ใจแบบกระจัดกระจาย รุ่น Qwen2.5-Turbo ช่วยลดระยะเวลาการประมวลผลโทเค็นแรกจำนวน 1 ล้านโทเค็นจาก 4.9 นาทีเหลือ 68 วินาที ทำให้ได้รับความเร็วในการอนุมานเพิ่มขึ้น 4.3 เท่า
ในเวลาเดียวกัน ค่าใช้จ่ายในการประมวลผล 1 ล้านโทเค็นอยู่ที่ 0.3 หยวนเท่านั้น เมื่อเทียบกับ GPT-4o-mini สามารถประมวลผลเนื้อหาได้ 3.6 เท่าในราคาเดียวกัน
Alibaba Cloud ได้เตรียมชุดการสาธิตสำหรับรุ่น Qwen2.5-Turbo ซึ่งแสดงให้เห็นการประยุกต์ใช้ในการทำความเข้าใจนวนิยายเชิงลึก ความช่วยเหลือด้านโค้ด และการอ่านเอกสารหลายฉบับ ตัวอย่างเช่น หลังจากที่ผู้ใช้อัปโหลดนวนิยายจีนไตรภาค "The Three-Body Problem" ที่มีโทเค็น 690,000 โทเค็น แบบจำลองก็สามารถสรุปเนื้อเรื่องของนวนิยายแต่ละเรื่องเป็นภาษาอังกฤษได้สำเร็จ
ผู้ใช้สามารถสัมผัสประสบการณ์ฟังก์ชันอันทรงพลังของรุ่น Qwen2.5-Turbo ผ่านบริการ API ของ Alibaba Cloud Model Studio, HuggingFace Demo หรือ ModelScope Demo
อาลีบาบา คลาวด์ ระบุว่าในอนาคต จะยังคงปรับโมเดลให้เหมาะสมต่อไป เพื่อปรับปรุงการจัดตำแหน่งตามความชอบของมนุษย์ในงานลำดับยาว เพิ่มประสิทธิภาพการอนุมานให้เหมาะสมยิ่งขึ้น ลดเวลาในการประมวลผล และพยายามเปิดตัวโมเดลบริบทที่ยาวและใหญ่ขึ้นและแข็งแกร่งขึ้น
บทนำอย่างเป็นทางการ: https://qwenlm.github.io/blog/qwen2.5-turbo/
การสาธิตออนไลน์: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
เอกสาร API: https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen
การเกิดขึ้นของ Qwen2.5-Turbo ถือเป็นความก้าวหน้าครั้งสำคัญในด้านความสามารถในการประมวลผลข้อความขนาดยาวของโมเดลภาษาขนาดใหญ่ ประสิทธิภาพสูงและต้นทุนต่ำจะนำศักยภาพการใช้งานมหาศาลมาสู่ทุกสาขาอาชีพ มาดูกันว่าโมเดลอันทรงพลังนี้จะเปลี่ยนโลกของเราในอนาคตอย่างไร!