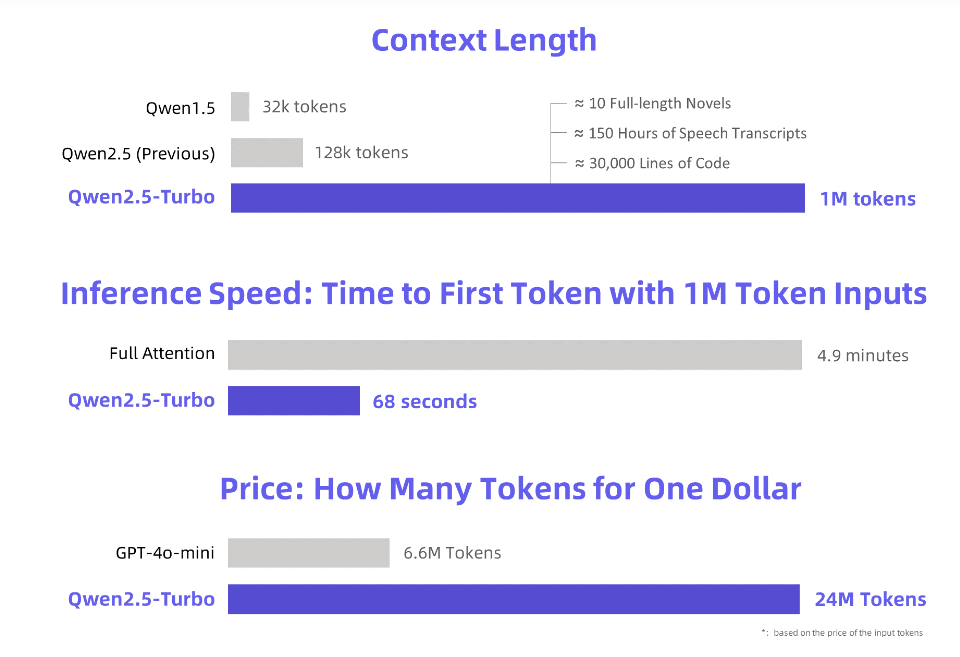
Downcodes의 편집자는 Alibaba Cloud가 새로 업그레이드된 Qwen2.5-Turbo 대형 언어 모델을 출시했으며 해당 컨텍스트 길이가 놀랍게도 100만 개의 토큰에 도달했다는 사실을 알게 되었습니다! 이것은 무엇을 의미합니까? 이는 "삼체" 소설 10편, 음성 150시간, 코드 30,000줄에 해당하는 정보량을 처리할 수 있다는 의미입니다! 이러한 강력한 처리 능력은 우리가 대규모 언어 모델과 상호 작용하는 방식에 혁명을 일으킬 것입니다.
Alibaba Cloud는 새롭게 업그레이드된 Qwen2.5-Turbo 대형 언어 모델을 출시합니다. 이 모델의 컨텍스트 길이는 놀랍게도 토큰 100만 개를 초과합니다. 이 개념에 해당하는 것은 무엇입니까? 소설 10권, 음성 전사 150시간 또는 코드 용량 30,000줄에 해당합니다. 이제 "한숨에 소설 10권 읽기"는 더 이상 꿈이 아닙니다!
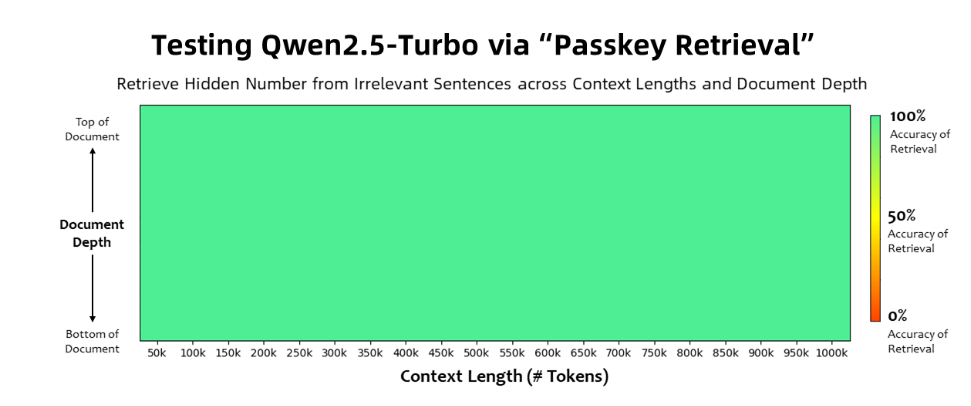
Qwen2.5-Turbo 모델은 패스키 검색 작업에서 100% 정확도를 달성했으며 긴 텍스트 이해 기능 측면에서 GPT-4와 같은 유사 모델을 능가했습니다. 이 모델은 RULER 긴 텍스트 벤치마크에서 93.1이라는 높은 점수를 얻은 반면, GPT-4는 91.6점, GLM4-9B-1M은 89.9점을 얻었습니다.
매우 긴 텍스트 처리 기능 외에도 Qwen2.5-Turbo는 짧은 텍스트 처리의 정확성도 갖추고 있습니다. 짧은 텍스트 벤치마크 테스트에서 성능은 GPT-4o-mini 및 Qwen2.5-14B-Instruct와 비슷합니다. 모델.
Qwen2.5-Turbo 모델은 Sparse Attention 메커니즘을 채택하여 100만 개의 토큰에 대한 첫 번째 토큰 처리 시간을 4.9분에서 68초로 단축하여 추론 속도를 4.3배 향상시켰습니다.
동시에 100만 개의 토큰을 처리하는 데 드는 비용은 0.3위안에 불과합니다. GPT-4o-mini와 비교하면 동일한 비용으로 3.6배의 콘텐츠를 처리할 수 있습니다.
Alibaba Cloud는 Qwen2.5-Turbo 모델에 대한 일련의 데모를 준비하여 소설에 대한 심층적인 이해, 코드 지원 및 여러 논문 읽기에 대한 응용 프로그램을 보여주었습니다. 예를 들어 사용자가 690,000개의 토큰이 포함된 중국 소설 '삼체 문제' 3부작을 업로드한 후 모델은 각 소설의 줄거리를 영어로 성공적으로 요약했습니다.
사용자는 Alibaba Cloud Model Studio, HuggingFace Demo 또는 ModelScope Demo의 API 서비스를 통해 Qwen2.5-Turbo 모델의 강력한 기능을 경험할 수 있습니다.
Alibaba Cloud는 앞으로도 긴 시퀀스 작업에서 인간의 선호 정렬을 개선하고 추론 효율성을 더욱 최적화하며 컴퓨팅 시간을 단축하고 더 크고 강력한 긴 컨텍스트 모델을 출시하기 위해 모델을 계속 최적화할 것이라고 밝혔습니다.
공식 소개: https://qwenlm.github.io/blog/qwen2.5-turbo/
온라인 데모: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
API 문서: https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen
Qwen2.5-Turbo의 출현은 대규모 언어 모델의 긴 텍스트 처리 기능에 있어 획기적인 발전을 의미합니다. 높은 효율성과 저렴한 비용은 모든 계층에 엄청난 응용 가능성을 가져다 줄 것입니다. 이 강력한 모델이 미래에 우리 세상을 어떻게 변화시킬지 기다려 봅시다!