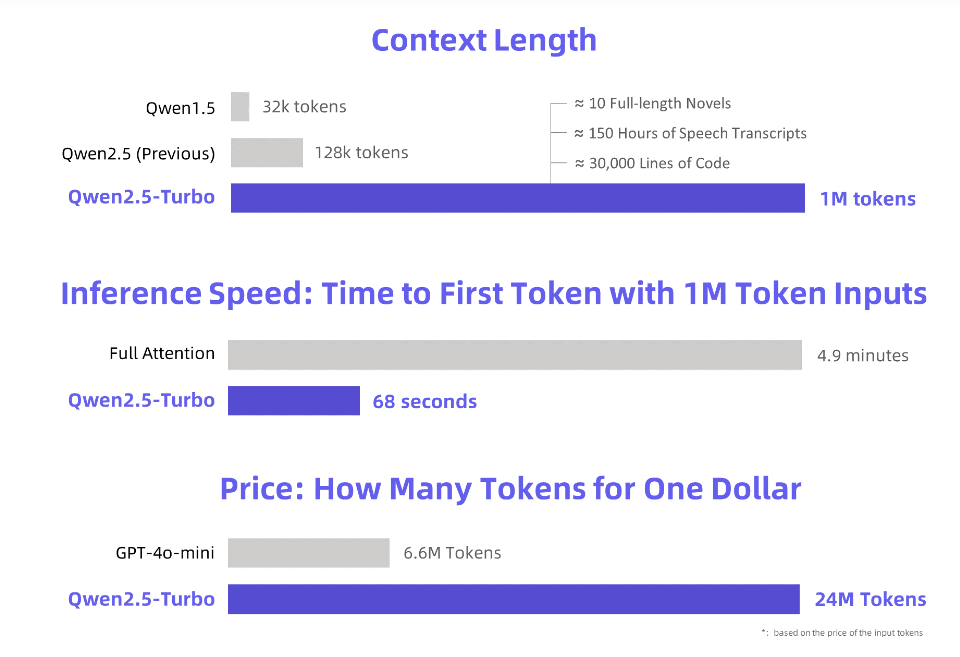
علم محرر Downcodes أن Alibaba Cloud قد أصدرت نموذج لغة كبير Qwen2.5-Turbo تمت ترقيته حديثًا، وقد وصل طول سياقه إلى مليون رمز مذهل! ماذا يعني هذا؟ وهذا يعني أنه يمكنه معالجة كمية من المعلومات تعادل 10 روايات "ثلاثية الجسم"، أو 150 ساعة من الصوت، أو 30000 سطر من التعليمات البرمجية! ستحدث قوة المعالجة القوية هذه ثورة في الطريقة التي نتفاعل بها مع نماذج اللغات الكبيرة.
تطلق Alibaba Cloud نموذج اللغة الكبير Qwen2.5-Turbo الذي تمت ترقيته حديثًا، والذي يتجاوز طول سياقه مليون رمز مذهل. ما هو يعادل هذا المفهوم؟ إنه يعادل 10 روايات "ثلاثة أجساد"، أو 150 ساعة من النسخ الصوتي، أو 30 ألف سطر من سعة الكود هذه المرة، لم تعد "قراءة عشر روايات في نفس واحد" حلما!
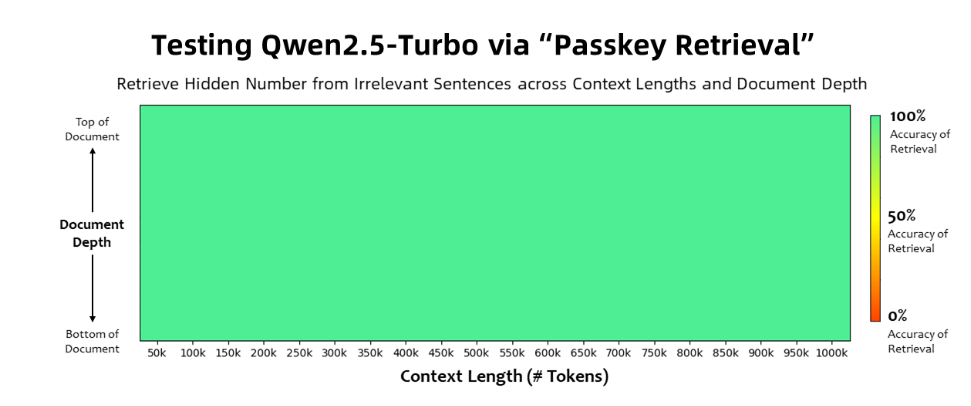
حقق نموذج Qwen2.5-Turbo دقة بنسبة 100% في مهمة استرجاع مفتاح المرور، وتجاوز النماذج المماثلة مثل GPT-4 من حيث قدرات فهم النص الطويل. حقق النموذج درجة عالية بلغت 93.1 في اختبار RULER للنصوص الطويلة، في حين سجل GPT-4 91.6 فقط، وسجل GLM4-9B-1M 89.9.
بالإضافة إلى قدرات معالجة النصوص الطويلة جدًا، يتمتع Qwen2.5-Turbo أيضًا بدقة معالجة النصوص القصيرة، وفي اختبار قياس النص القصير، يمكن مقارنة أدائه بـ GPT-4o-mini وQwen2.5-14B-Instruct. نماذج.
من خلال اعتماد آلية الاهتمام المتناثر، يختصر نموذج Qwen2.5-Turbo وقت معالجة الرمز المميز الأول لمليون رمز من 4.9 دقيقة إلى 68 ثانية، مما يحقق زيادة قدرها 4.3 أضعاف في سرعة الاستدلال.
وفي الوقت نفسه، تبلغ تكلفة معالجة مليون رمز 0.3 يوان فقط، وبالمقارنة مع GPT-4o-mini، يمكنه معالجة المحتوى بمقدار 3.6 أضعاف بنفس التكلفة.
أعدت Alibaba Cloud سلسلة من العروض التوضيحية لنموذج Qwen2.5-Turbo، والتي توضح تطبيقه في الفهم المتعمق للروايات، والمساعدة في التعليمات البرمجية، وقراءة أوراق متعددة. على سبيل المثال، بعد أن قام أحد المستخدمين بتحميل ثلاثية الرواية الصينية "مشكلة الأجسام الثلاثة" التي تحتوي على 690 ألف رمز، نجح النموذج في تلخيص حبكة كل رواية باللغة الإنجليزية.
يمكن للمستخدمين تجربة الوظائف القوية لنموذج Qwen2.5-Turbo من خلال خدمة API الخاصة بـ Alibaba Cloud Model Studio أو HuggingFace Demo أو ModelScope Demo.
ذكرت Alibaba Cloud أنها ستواصل في المستقبل تحسين النموذج لتحسين توافق التفضيلات البشرية في المهام المتسلسلة الطويلة، وتحسين كفاءة الاستدلال بشكل أكبر، وتقليل وقت الحوسبة، ومحاولة إطلاق نموذج سياق طويل أكبر وأقوى.
المقدمة الرسمية: https://qwenlm.github.io/blog/qwen2.5-turbo/
العرض التوضيحي عبر الإنترنت: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
وثائق واجهة برمجة التطبيقات: https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen
يمثل ظهور Qwen2.5-Turbo إنجازًا كبيرًا في قدرات معالجة النصوص الطويلة لنماذج اللغات الكبيرة. ستوفر كفاءتها العالية وتكلفتها المنخفضة إمكانات تطبيق هائلة لجميع مناحي الحياة. دعونا ننتظر ونرى كيف سيغير هذا النموذج القوي عالمنا في المستقبل!