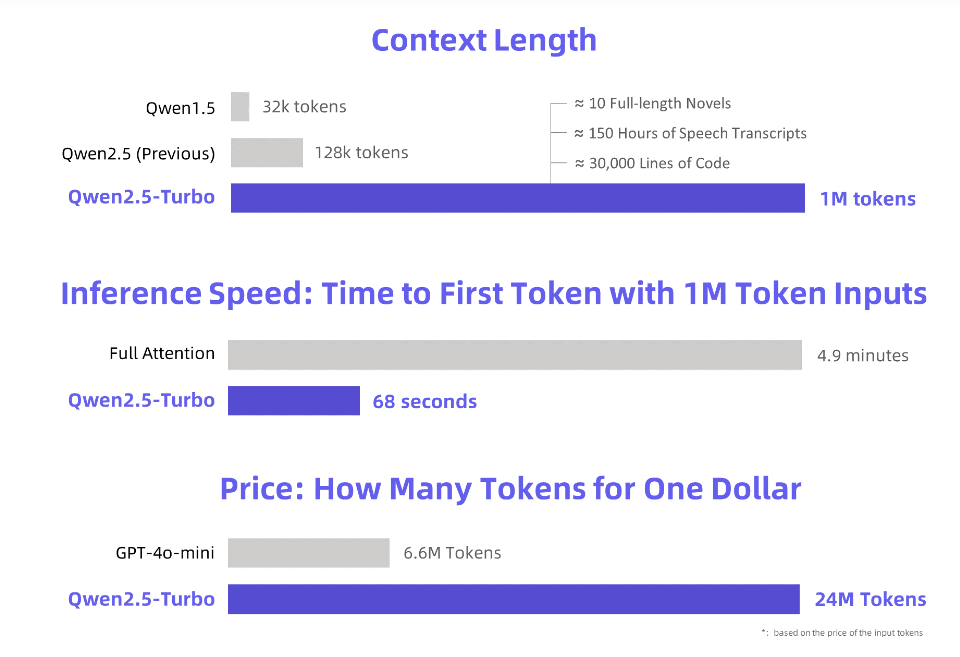
Der Herausgeber von Downcodes erfuhr, dass Alibaba Cloud ein neu aktualisiertes Qwen2.5-Turbo-Großsprachenmodell veröffentlicht hat und dessen Kontextlänge erstaunliche 1 Million Token erreicht hat! Was bedeutet das? Das bedeutet, dass es eine Informationsmenge verarbeiten kann, die 10 „Three Body“-Romanen, 150 Stunden Sprachausgabe oder 30.000 Zeilen Code entspricht! Eine solch leistungsstarke Rechenleistung wird die Art und Weise, wie wir mit großen Sprachmodellen interagieren, revolutionieren.
Alibaba Cloud führt das neu aktualisierte große Sprachmodell Qwen2.5-Turbo ein, dessen Kontextlänge erstaunliche 1 Million Token übersteigt. Was entspricht diesem Konzept? Es entspricht 10 „Three Body“-Romanen, 150 Stunden Sprachtranskription oder 30.000 Zeilen Codekapazität. Diesmal ist „zehn Romane in einem Atemzug lesen“ kein Traum mehr!
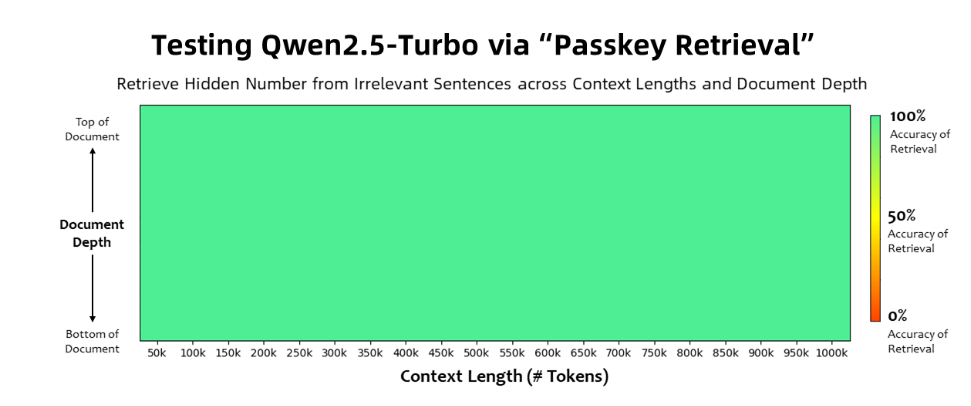
Das Qwen2.5-Turbo-Modell erreichte eine Genauigkeit von 100 % bei der Passkey-Retrieval-Aufgabe und übertraf ähnliche Modelle wie GPT-4 in Bezug auf die Fähigkeiten zum Verständnis langer Texte. Das Modell erreichte beim RULER-Langtext-Benchmark eine hohe Punktzahl von 93,1, während GPT-4 nur 91,6 und GLM4-9B-1M 89,9 erreichte.
Zusätzlich zu den Funktionen zur Verarbeitung ultralanger Texte verfügt Qwen2.5-Turbo auch über die Genauigkeit der Verarbeitung kurzer Texte. Im Kurztext-Benchmark-Test ist seine Leistung mit der von GPT-4o-mini und Qwen2.5-14B-Instruct vergleichbar Modelle.
Durch die Übernahme des Sparse-Attention-Mechanismus verkürzt das Qwen2.5-Turbo-Modell die erste Token-Verarbeitungszeit von 1 Million Token von 4,9 Minuten auf 68 Sekunden und erreicht so eine 4,3-fache Steigerung der Inferenzgeschwindigkeit.
Gleichzeitig betragen die Kosten für die Verarbeitung von 1 Million Token nur 0,3 Yuan. Im Vergleich zu GPT-4o-mini kann bei gleichen Kosten das 3,6-fache des Inhalts verarbeitet werden.
Alibaba Cloud hat eine Reihe von Demonstrationen für das Qwen2.5-Turbo-Modell vorbereitet, die seine Anwendung beim vertieften Verständnis von Romanen, bei der Codeunterstützung und beim Lesen mehrerer Artikel demonstrieren. Nachdem ein Benutzer beispielsweise die chinesische Romantrilogie „Das Drei-Körper-Problem“ mit 690.000 Token hochgeladen hatte, fasste das Modell die Handlung jedes Romans erfolgreich auf Englisch zusammen.
Benutzer können die leistungsstarken Funktionen des Qwen2.5-Turbo-Modells über den API-Dienst von Alibaba Cloud Model Studio, HuggingFace Demo oder ModelScope Demo erleben.
Alibaba Cloud erklärte, dass es das Modell in Zukunft weiter optimieren wird, um die Ausrichtung menschlicher Präferenzen bei Aufgaben mit langer Sequenz zu verbessern, die Inferenzeffizienz weiter zu optimieren, die Rechenzeit zu reduzieren und zu versuchen, ein größeres und stärkeres Modell mit langem Kontext auf den Markt zu bringen.
Offizielle Einführung: https://qwenlm.github.io/blog/qwen2.5-turbo/
Online-Demo: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
API-Dokumentation: https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen
Das Aufkommen von Qwen2.5-Turbo markiert einen großen Durchbruch bei den Langtextverarbeitungsfunktionen großer Sprachmodelle. Seine hohe Effizienz und seine geringen Kosten eröffnen ein enormes Anwendungspotenzial für alle Lebensbereiche. Warten wir ab, wie dieses leistungsstarke Modell unsere Welt in Zukunft verändern wird!