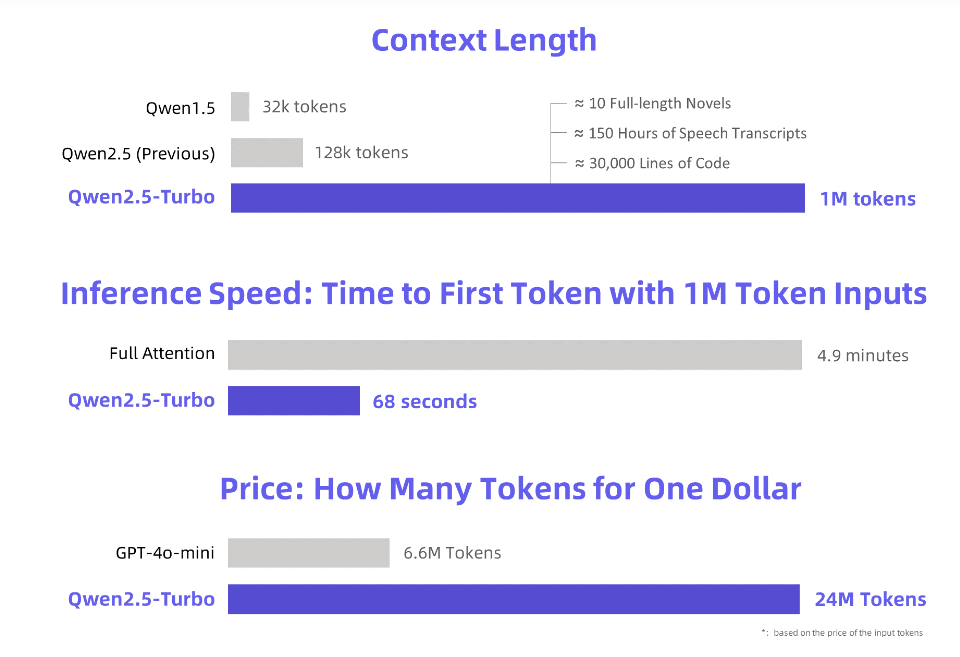
L'éditeur de Downcodes a appris qu'Alibaba Cloud avait publié un grand modèle de langage Qwen2.5-Turbo récemment mis à niveau et que sa longueur de contexte avait atteint un million de jetons étonnants ! Qu'est-ce que cela signifie? Cela signifie qu'il peut traiter une quantité d'informations équivalente à 10 romans « Trois corps », 150 heures de voix ou 30 000 lignes de code ! Une telle puissance de traitement va révolutionner la façon dont nous interagissons avec les grands modèles de langage.
Alibaba Cloud lance le nouveau modèle de langage étendu Qwen2.5-Turbo, dont la longueur du contexte dépasse le nombre étonnant d'un million de jetons. Quel est l'équivalent de ce concept ? C'est l'équivalent de 10 romans « Trois Corps », 150 heures de transcription vocale ou 30 000 lignes de code cette fois, « lire dix romans d'un seul coup » n'est plus un rêve !
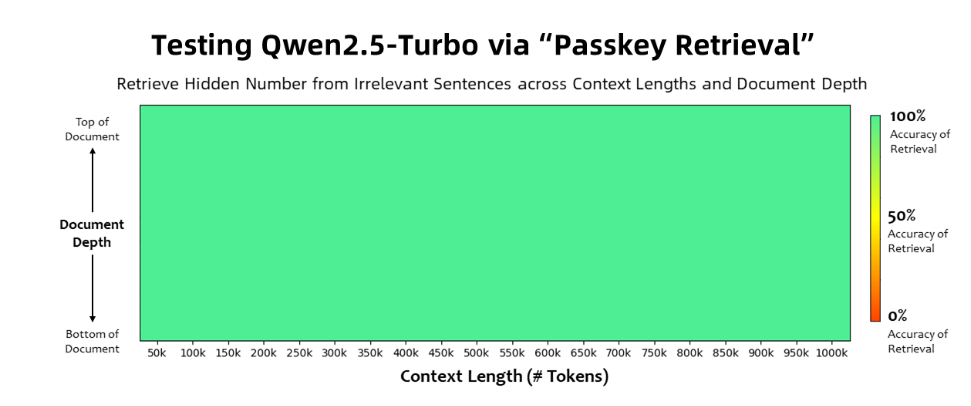
Le modèle Qwen2.5-Turbo a atteint une précision de 100 % dans la tâche de récupération de clé d'accès et a surpassé des modèles similaires tels que GPT-4 en termes de capacités de compréhension de textes longs. Le modèle a obtenu un score élevé de 93,1 sur le benchmark de texte long RULER, tandis que GPT-4 n'a obtenu qu'un score de 91,6 et GLM4-9B-1M un score de 89,9.
En plus des capacités de traitement de texte ultra-long, Qwen2.5-Turbo possède également la précision du traitement de texte court. Dans le test de référence de texte court, ses performances sont comparables à celles du GPT-4o-mini et du Qwen2.5-14B-Instruct. modèles.
En adoptant le mécanisme d'attention clairsemée, le modèle Qwen2.5-Turbo réduit le temps de traitement du premier jeton d'un million de jetons de 4,9 minutes à 68 secondes, ce qui permet d'obtenir une vitesse d'inférence multipliée par 4,3.
Dans le même temps, le coût de traitement d'un million de jetons n'est que de 0,3 yuan. Par rapport au GPT-4o-mini, il peut traiter 3,6 fois le contenu au même coût.
Alibaba Cloud a préparé une série de démonstrations pour le modèle Qwen2.5-Turbo, montrant son application dans la compréhension approfondie de romans, l'assistance au code et la lecture de plusieurs articles. Par exemple, après qu'un utilisateur a mis en ligne la trilogie de romans chinois « Le problème à trois corps » contenant 690 000 jetons, le modèle a réussi à résumer l'intrigue de chaque roman en anglais.
Les utilisateurs peuvent découvrir les fonctions puissantes du modèle Qwen2.5-Turbo via le service API d'Alibaba Cloud Model Studio, HuggingFace Demo ou ModelScope Demo.
Alibaba Cloud a déclaré qu'à l'avenir, il continuerait à optimiser le modèle pour améliorer son alignement des préférences humaines dans les tâches à longue séquence, optimiser davantage l'efficacité de l'inférence, réduire le temps de calcul et essayer de lancer un modèle de contexte long plus grand et plus solide.
Introduction officielle : https://qwenlm.github.io/blog/qwen2.5-turbo/
Démo en ligne : https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
Documentation API : https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen
L'émergence de Qwen2.5-Turbo marque une avancée majeure dans les capacités de traitement de texte long des grands modèles de langage. Sa haute efficacité et son faible coût apporteront un énorme potentiel d’application à tous les horizons. Attendons de voir comment ce modèle puissant changera notre monde à l’avenir !