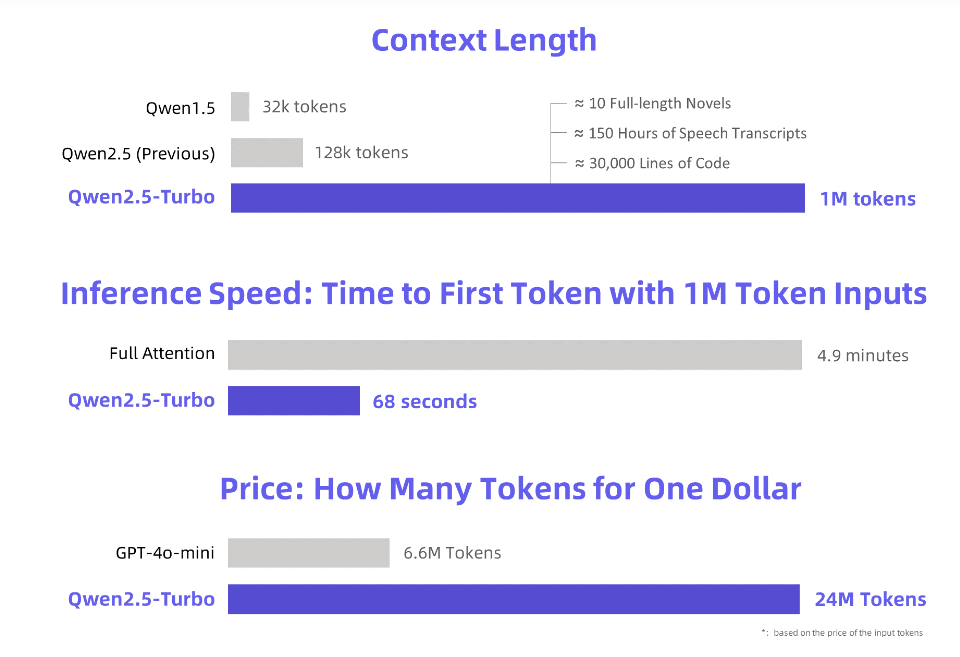
Downcodes の編集者は、Alibaba Cloud が新しくアップグレードされた Qwen2.5-Turbo 大規模言語モデルをリリースし、そのコンテキストの長さが驚くべき 100 万トークンに達したことを知りました。これはどういう意味ですか?これは、「三体」小説 10 冊、150 時間の音声、または 30,000 行のコードに相当する情報量を処理できることを意味します。このような強力な処理能力は、大規模な言語モデルと対話する方法に革命をもたらすでしょう。
Alibaba Cloud は、新しくアップグレードされた Qwen2.5-Turbo 大規模言語モデルを開始します。そのコンテキスト長は、驚くべき 100 万トークンを超えています。この概念は、「三体」小説 10 冊、音声文字起こし 150 時間、またはコード容量 30,000 行に相当します。今回は、「小説 10 冊を一気に読む」も夢ではありません。
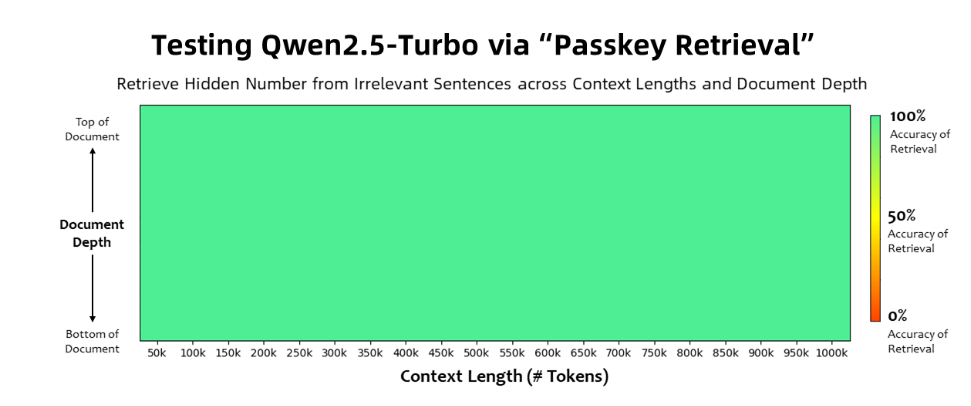
Qwen2.5-Turbo モデルは、パスキー取得タスクで 100% の精度を達成し、長文理解能力の点で GPT-4 などの同様のモデルを上回りました。このモデルは、RULER 長文ベンチマークで 93.1 という高スコアを達成しましたが、GPT-4 のスコアは 91.6 にとどまり、GLM4-9B-1M のスコアは 89.9 でした。
Qwen2.5-Turbo は超長文処理能力に加え、短文処理の精度も備えており、短文ベンチマークテストでは GPT-4o-mini や Qwen2.5-14B-Instruct と同等の性能を発揮します。モデル。
Qwen2.5-Turbo モデルでは、スパース アテンション メカニズムを採用することで、100 万トークンの最初のトークン処理時間が 4.9 分から 68 秒に短縮され、推論速度が 4.3 倍向上しました。
同時に、100万トークンの処理コストはわずか0.3元で、GPT-4o-miniと比較して、同じコストで3.6倍のコンテンツを処理できます。
Alibaba Cloud は、Qwen2.5-Turbo モデルの一連のデモンストレーションを準備し、小説の深い理解、コード支援、複数の論文の読み取りへの応用を示しました。たとえば、ユーザーが 690,000 トークンを含む中国の小説「三体問題」三部作をアップロードした後、モデルは各小説のプロットを英語で要約することに成功しました。
ユーザーは、Alibaba Cloud Model Studio、HuggingFace Demo、ModelScope Demo の API サービスを通じて、Qwen2.5-Turbo モデルの強力な機能を体験できます。
Alibaba Cloudは、今後もモデルの最適化を継続して、長いシーケンスのタスクにおける人間の好みの調整を改善し、推論効率をさらに最適化し、計算時間を短縮し、より大規模で強力なロングコンテキストモデルの立ち上げを試みると述べた。
公式紹介: https://qwenlm.github.io/blog/qwen2.5-turbo/
オンラインデモ: https://huggingface.co/spaces/Qwen/Qwen2.5-Turbo-1M-Demo
API ドキュメント: https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen
Qwen2.5-Turbo の登場は、大規模言語モデルの長文テキスト処理機能における大きな進歩を示しています。その高効率と低コストは、あらゆる分野に大きな応用の可能性をもたらします。この強力なモデルが将来私たちの世界をどのように変えるかを楽しみに待ちましょう!