personality prediction
Code for ICDM'20 paper

พื้นที่เก็บข้อมูลนี้มีรหัสสำหรับกระดาษจากล่างขึ้นบนและบนลงล่าง: การทำนายบุคลิกภาพด้วยคุณสมบัติรูปแบบจิตวิทยาและภาษาที่ตีพิมพ์ใน IEEE International Conference of Data Mining 2020
นี่คือชุดของการทดลองที่เขียนใน TensorFlow + Pytorch เพื่อสำรวจการตรวจจับบุคลิกภาพอัตโนมัติโดยใช้แบบจำลองภาษาในชุดข้อมูลเรียงความ (บุคลิกภาพที่มีบุคลิกขนาดใหญ่ที่มีการระบุลักษณะ) และชุดข้อมูล Kaggle MBTI
ดึงที่เก็บจาก GitHub ตามด้วยการสร้างสภาพแวดล้อมเสมือนจริงใหม่ (conda หรือ venv):
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10ติดตั้งบทกวีและใช้สิ่งนั้นเพื่อติดตั้งการอ้างอิงที่จำเป็นสำหรับการเรียกใช้โครงการ:
curl - sSL https : // install . python - poetry . org | python3 -
poetry install ก่อนอื่นให้เรียกใช้รหัส LM Extractor ซึ่งผ่านชุดข้อมูลผ่านโมเดลภาษาและเก็บ embeddings (ของเลเยอร์ทั้งหมด) ในไฟล์ดอง การสร้าง 'ชุดข้อมูลใหม่' นี้ช่วยให้เราประหยัดเวลาได้มากและช่วยให้การค้นหา HyperParameters ที่มีประสิทธิภาพสำหรับเครือข่าย Finetuning ก่อนที่จะเรียกใช้รหัสให้สร้างโฟลเดอร์ PKL_DATA ในโฟลเดอร์ repo อาร์กิวเมนต์ทั้งหมดเป็นทางเลือกและไม่มีการส่งอาร์กิวเมนต์เรียกใช้ตัวแยกด้วยค่าเริ่มต้น
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data 'ถัดไปเรียกใช้โมเดล finetuning เพื่อนำคุณสมบัติที่แยกออกมาเป็นอินพุตจากไฟล์ดองและฝึกอบรมโมเดล finetuning เราพบว่า MLP ตื้นที่มีประสิทธิภาพดีที่สุด
python finetune_models/MLP_LM.py| ตารางผลลัพธ์ | แบบจำลองภาษากับลักษณะทางจิตวิทยา |
|---|---|
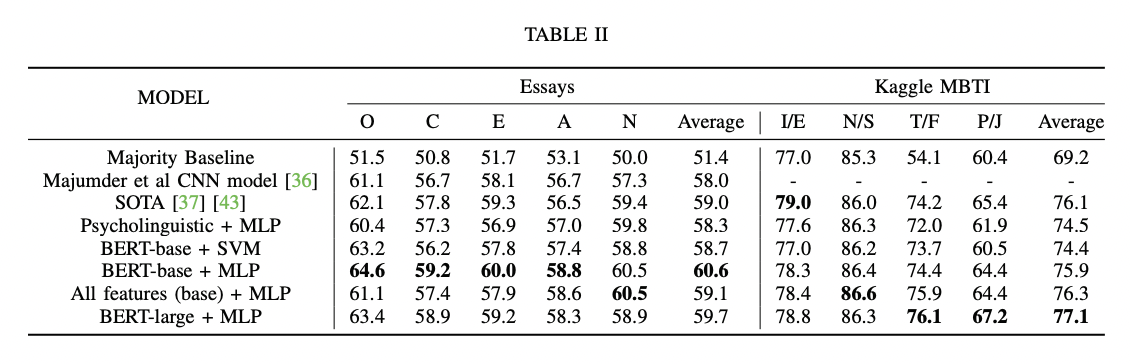 | 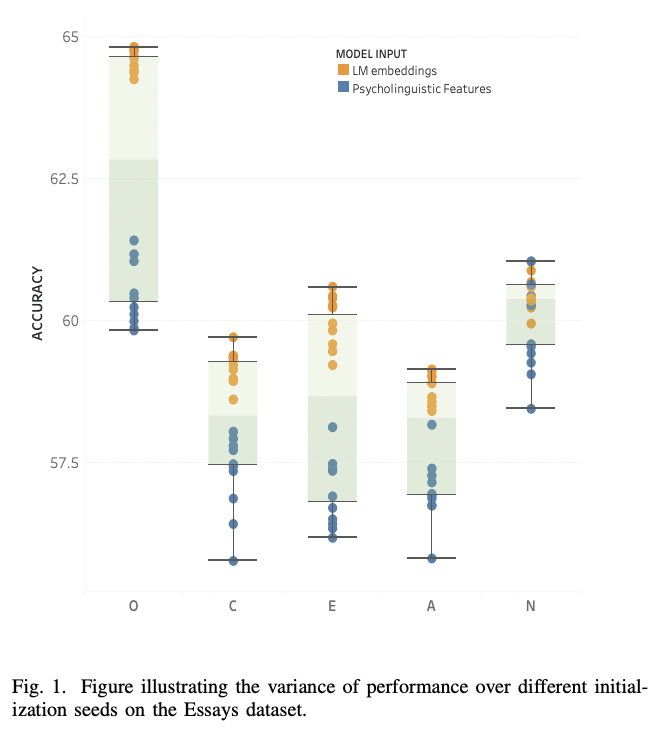 |
ทำตามขั้นตอนด้านล่างสำหรับการทำนายบุคลิกภาพ (เช่นบิ๊กห้า: ลักษณะมหาสมุทร) บนข้อความ/เรียงความใหม่:
python finetune_models/MLP_LM.py -save_model ' yes 'ตอนนี้ใช้สคริปต์ด้านล่างเพื่อทำนายข้อความที่มองไม่เห็น:
python unseen_predictor.pyLM_extractor.pyบน RTX2080 GPU ตัวแยก 'bert-base' ที่มีการใช้งานใช้เวลาประมาณ ~ 2m 30s และ 'Bert-large' ใช้เวลาประมาณ ~ 5m 30s
บน CPU ตัวแยก 'Bert-base' ใช้เวลาประมาณ ~ 25m
python finetune_models/MLP_LM.pyบน RTX2080 GPU ทำงานเป็นเวลา 15 ยุค (ที่ไม่มีการตรวจสอบข้าม) ใช้เวลาตั้งแต่ 5S-60S ขึ้นอยู่กับสถาปัตยกรรม MLP
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}หากคุณพบว่า repo นี้มีประโยชน์สำหรับการวิจัยของคุณโปรดอ้างอิงโดยใช้สิ่งต่อไปนี้:
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}ซอร์สโค้ดสำหรับโครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT


