personality prediction
Code for ICDM'20 paper

Этот репозиторий содержит код для бумаги снизу вверх и сверху вниз: прогнозирование личности с помощью психолингвистических и языковых модельных функций, опубликованных на Международной конференции данных IEEE по добыче данных 2020 .
Вот набор экспериментов, написанных в Tensorflow + Pytorch для изучения автоматического обнаружения личности с использованием языковых моделей в наборе данных эссе (черты с маркировкой пятерки) и набор данных Kaggle MBTI.
Вытащите репозиторий из GitHub, затем создать новую виртуальную среду (Conda или Venv):
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10Установите стихи и используйте ее для установки зависимостей, необходимых для запуска проекта:
curl - sSL https : // install . python - poetry . org | python3 -
poetry install Сначала запустите код экстрактора LM, который передает набор данных через языковую модель и хранит встроенные (из всех слоев) в файле рассола. Создание этого «нового набора данных» сохраняет нас много времени и позволяет эффективному поиску гиперпараметров для сети в области создания. Перед запуском кода создайте папку PKL_DATA в папке Repo. Все аргументы необязательны, и не передают аргументы, которые запускают экстрактор со значениями по умолчанию.
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data 'Затем запустите модель создания, чтобы принять извлеченные функции в качестве ввода из файла Pickle и обучить модель Mevetuning. Мы находим мелкий MLP, чтобы быть лучшим выполнением
python finetune_models/MLP_LM.py| Таблица результатов | Языковые модели против психолингвистических признаков |
|---|---|
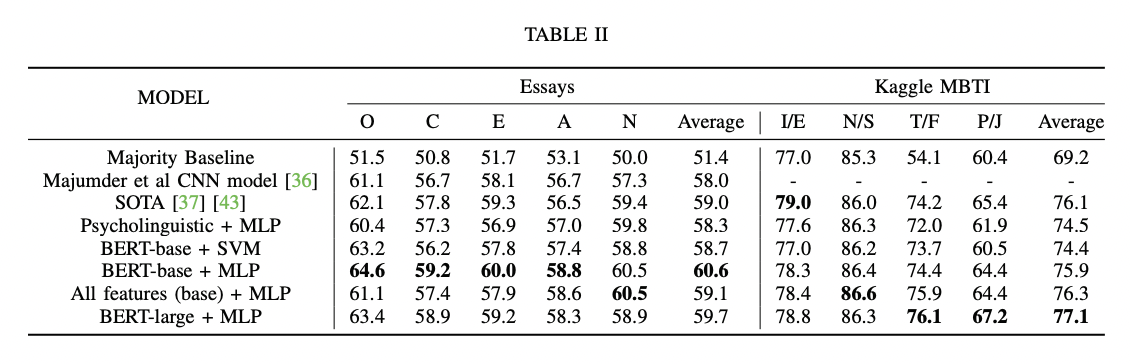 | 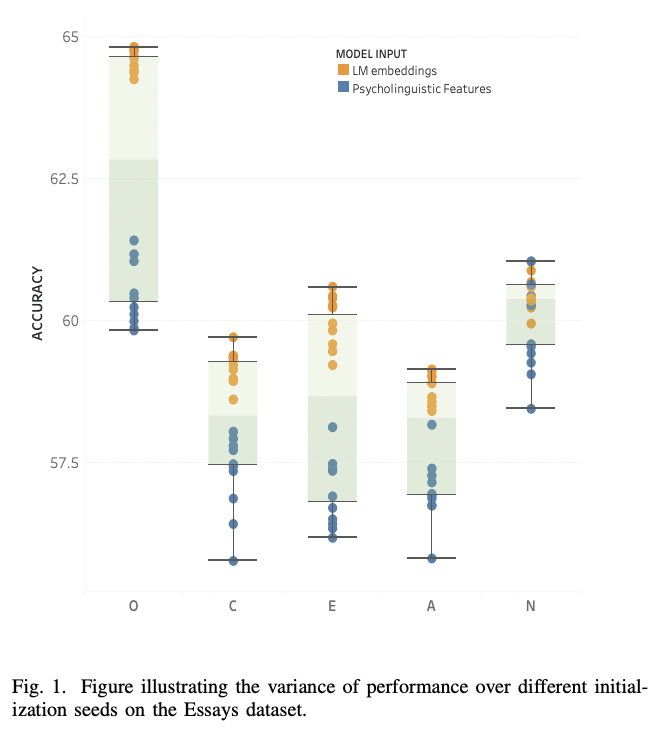 |
Следуйте приведенным ниже шагам для прогнозирования личности (например, Big Five: Ocean Trats) на новом тексту/эссе:
python finetune_models/MLP_LM.py -save_model ' yes 'Теперь используйте сценарий ниже, чтобы предсказать невидимый текст:
python unseen_predictor.pyLM_extractor.pyНа графическом процессоре RTX2080 экстрактор-эмптор «bert-base» занимает около ~ 2 м 30, а «Берт-широкий» занимает около ~ 5 м 30-х годов.
На процессоре экстрактор «Bert-Base» занимает около ~ 25 м
python finetune_models/MLP_LM.pyНа графическом процессоре RTX2080, работающий в течение 15 эпох (без перекрестной проверки) берет с 5S-60, в зависимости от архитектуры MLP.
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}Если вы найдете это репо полезным для вашего исследования, пожалуйста, укажите его, используя следующее:
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}Исходный код для этого проекта лицензирован по лицензии MIT.


