personality prediction
Code for ICDM'20 paper

Repositori ini berisi kode untuk kertas bottom-up dan top-down: memprediksi kepribadian dengan fitur psikolinguistik dan model bahasa, yang diterbitkan dalam Konferensi Internasional IEEE dari Data Mining 2020 .
Berikut adalah serangkaian percobaan yang ditulis dalam TensorFlow + Pytorch untuk mengeksplorasi deteksi kepribadian otomatis menggunakan model bahasa pada dataset esai (kepribadian besar-lima berlabel ciri-ciri) dan dataset Kaggle MBTI.
Tarik repositori dari github, diikuti dengan menciptakan lingkungan virtual baru (conda atau venv):
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10Instal puisi, dan gunakan itu untuk menginstal dependensi yang diperlukan untuk menjalankan proyek:
curl - sSL https : // install . python - poetry . org | python3 -
poetry install Pertama jalankan kode LM Extractor yang melewati dataset melalui model bahasa dan menyimpan embeddings (dari semua lapisan) dalam file acar. Membuat 'dataset baru' ini menghemat banyak waktu komputasi dan memungkinkan pencarian hyperparameter yang efektif untuk jaringan finetuning. Sebelum menjalankan kode, buat folder PKL_DATA di folder Repo. Semua argumen adalah opsional dan tidak ada argumen yang menjalankan ekstraktor dengan nilai default.
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data 'Selanjutnya jalankan model finetuning untuk mengambil fitur yang diekstraksi sebagai input dari file acar dan melatih model finetuning. Kami menemukan MLP yang dangkal menjadi yang berkinerja terbaik
python finetune_models/MLP_LM.py| Tabel Hasil | Model Bahasa vs Sifat Psikolinguistik |
|---|---|
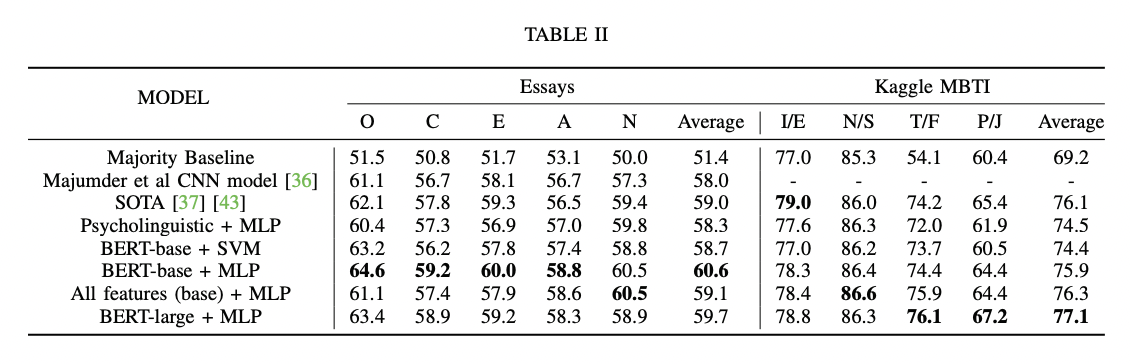 | 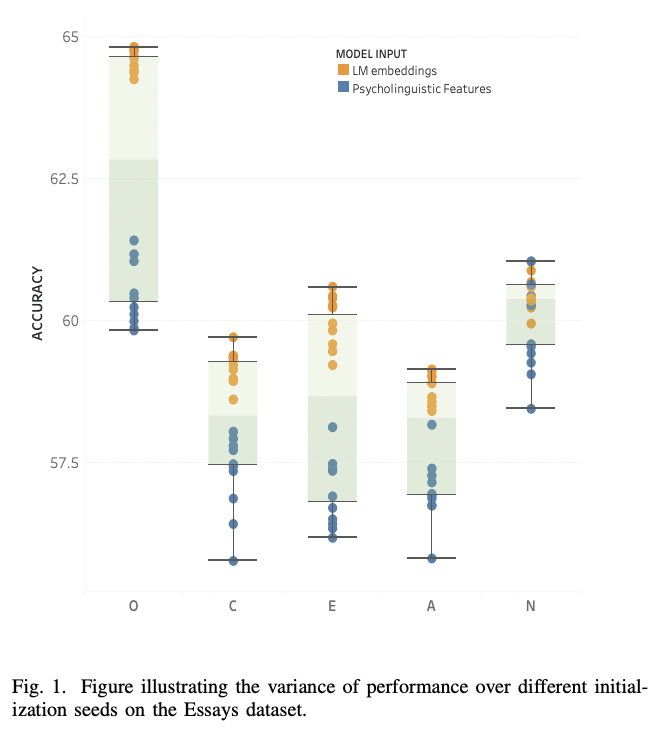 |
Ikuti langkah-langkah di bawah ini untuk memprediksi kepribadian (misalnya Big-Five: Samudra Ciri) pada teks/esai baru:
python finetune_models/MLP_LM.py -save_model ' yes 'Sekarang gunakan skrip di bawah ini untuk memprediksi teks yang tidak terlihat:
python unseen_predictor.pyLM_extractor.pyPada GPU RTX2080, Extractor 'Bert-Base' yang embbed mengambil sekitar ~ 2m 30-an dan 'Bert-Large' membutuhkan waktu sekitar ~ 5m 30-an
Pada CPU, ekstraktor 'Bert-base' membutuhkan waktu sekitar ~ 25m
python finetune_models/MLP_LM.pyPada GPU RTX2080, berjalan selama 15 zaman (tanpa validasi silang) dari 5S-60-an, tergantung pada arsitektur MLP.
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}Jika Anda menemukan repo ini berguna untuk penelitian Anda, silakan kutipnya menggunakan yang berikut:
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}Kode sumber untuk proyek ini dilisensikan di bawah lisensi MIT.


