personality prediction
Code for ICDM'20 paper

このリポジトリには、紙のボトムアップとトップダウンのコードが含まれています。IEEE国際データマイニング2020で公開されている精神言語モデルの機能で性格を予測します。
以下は、Tensorflow + Pytorchで書かれた一連の実験で、エッセイデータセット(ビッグ5人格のラベル付けされた特性)とKaggle MBTIデータセットの言語モデルを使用した自動性パーソナリティ検出を調査します。
Githubからリポジトリを引き出し、新しい仮想環境(CondaまたはVenv)を作成します。
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10詩をインストールし、それを使用して、プロジェクトの実行に必要な依存関係をインストールします。
curl - sSL https : // install . python - poetry . org | python3 -
poetry install 最初に、データセットを言語モデルに渡すLM抽出装置コードを実行し、(すべてのレイヤーの)埋め込みをピクルスファイルに保存します。この「新しいデータセット」を作成すると、大量の計算時間が節約され、微調整ネットワークのハイパーパラメーターの効果的な検索が可能になります。コードを実行する前に、RepoフォルダーにPKL_DATAフォルダーを作成します。すべての引数はオプションであり、渡されない引数はデフォルト値で抽出器を実行しません。
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data '次に、微調整モデルを実行して、抽出された機能をピクルスファイルからの入力として取得し、微調整モデルをトレーニングします。私たちは浅いMLPが最高のパフォーマンスを持っていることを見つけます
python finetune_models/MLP_LM.py| 結果表 | 言語モデルと心理言語的特性 |
|---|---|
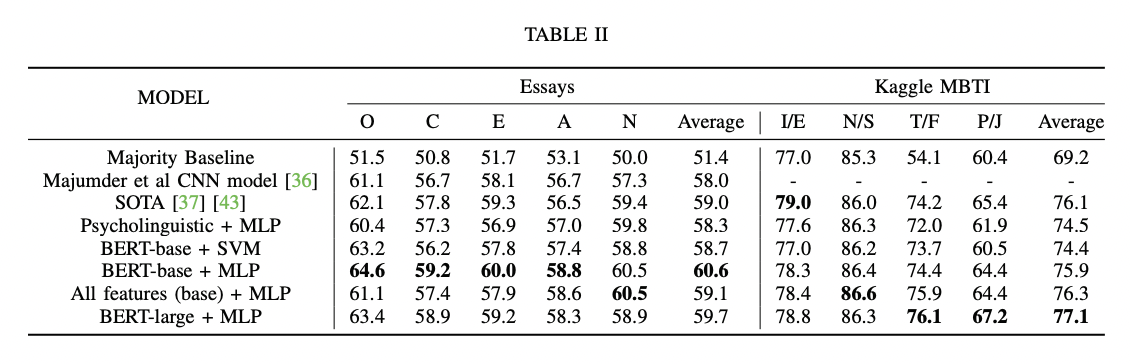 | 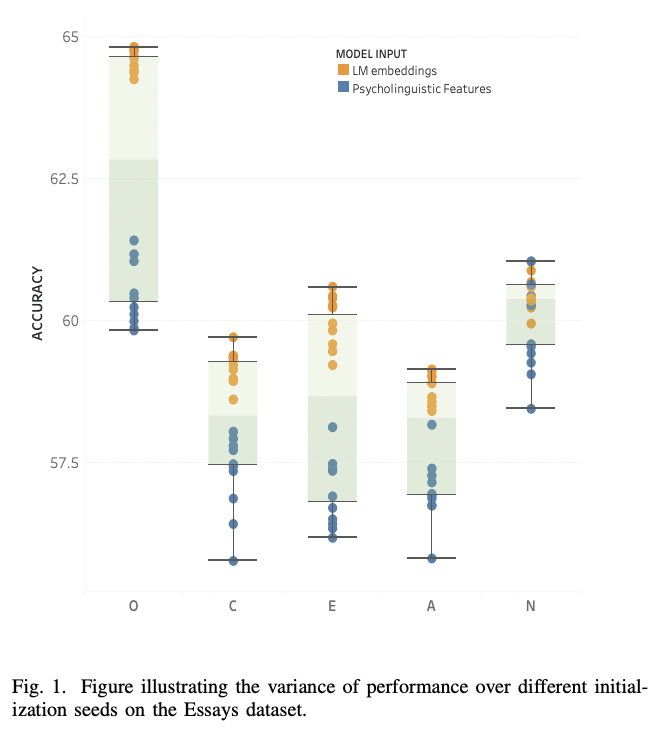 |
新しいテキスト/エッセイで性格(たとえば、ビッグファイブ:海洋特性など)を予測するために、以下の手順に従ってください。
python finetune_models/MLP_LM.py -save_model ' yes '次に、以下のスクリプトを使用して、目に見えないテキストを予測します。
python unseen_predictor.pyLM_extractor.pyRTX2080 GPUでは、-med embed 'bert-base'抽出器は約2mの30秒かかり、「バート - ラージ」は約5m 30秒かかります
CPUでは、「Bert-Base」抽出器には約25mかかります
python finetune_models/MLP_LM.pyRTX2080 GPUでは、MLPアーキテクチャに応じて、5S-60Sから15エポック(相互検証なし)で実行されます。
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}このリポジトリがあなたの研究に役立つと思われる場合は、以下を使用して引用してください。
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}このプロジェクトのソースコードは、MITライセンスの下でライセンスされています。


