personality prediction
Code for ICDM'20 paper

Dieses Repository enthält Code für das Papierbinder und Top-Down: Vorhersage der Persönlichkeit mit psycholinguistischen und sprachlichen Modellfunktionen, die in der IEEE International Conference of Data Mining 2020 veröffentlicht wurden.
Hier sind eine Reihe von Experimenten, die in TensorFlow + Pytorch geschrieben wurden, um die automatisierte Persönlichkeitserkennung mithilfe von Sprachmodellen im Essays-Datensatz (Big-Five-Persönlichkeits-Merkmale) und im Kaggle MBTI-Datensatz zu untersuchen.
Ziehen Sie das Repository aus GitHub, gefolgt von der Erstellung einer neuen virtuellen Umgebung (Conda oder Venv):
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10Installieren Sie Gedichte und verwenden Sie diese, um die für das Ausführen des Projekts erforderlichen Abhängigkeiten zu installieren:
curl - sSL https : // install . python - poetry . org | python3 -
poetry install Führen Sie zuerst den LM -Extraktorcode aus, der den Datensatz über das Sprachmodell übergibt und die Einbettung (aller Schichten) in einer Gurkendatei speichert. Das Erstellen dieses „neuen Datensatzes“ speichert uns viel Rechenzeit und ermöglicht eine effektive Suche der Hyperparameter für das Finetuning -Netzwerk. Erstellen Sie vor dem Ausführen des Codes einen PKL_Data -Ordner im Repo -Ordner. Alle Argumente sind optional, und das Übergeben ohne Argumente führt den Extraktor mit den Standardwerten aus.
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data 'Führen Sie als nächstes ein Finetuning -Modell aus, um die extrahierten Funktionen als Eingabe aus der Gurkendatei zu nutzen und ein Finetuning -Modell zu trainieren. Wir finden eine flache MLP als die beste Leistung
python finetune_models/MLP_LM.py| Ergebnisse Tabelle | Sprachmodelle gegen psycholinguistische Merkmale |
|---|---|
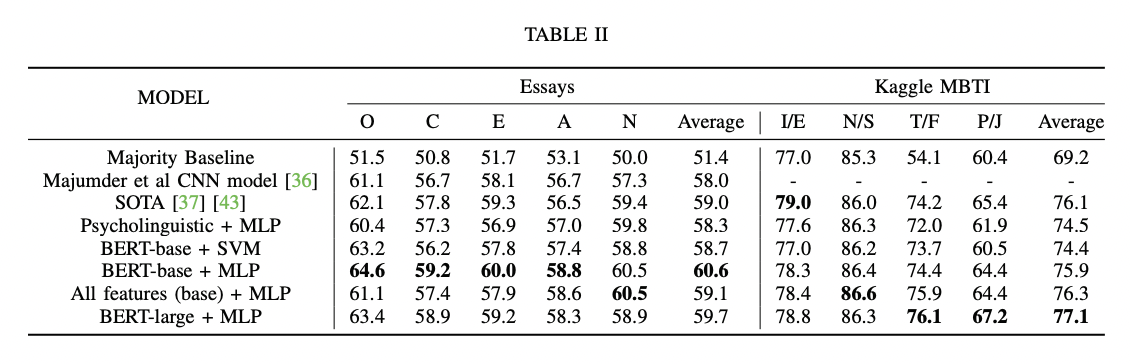 | 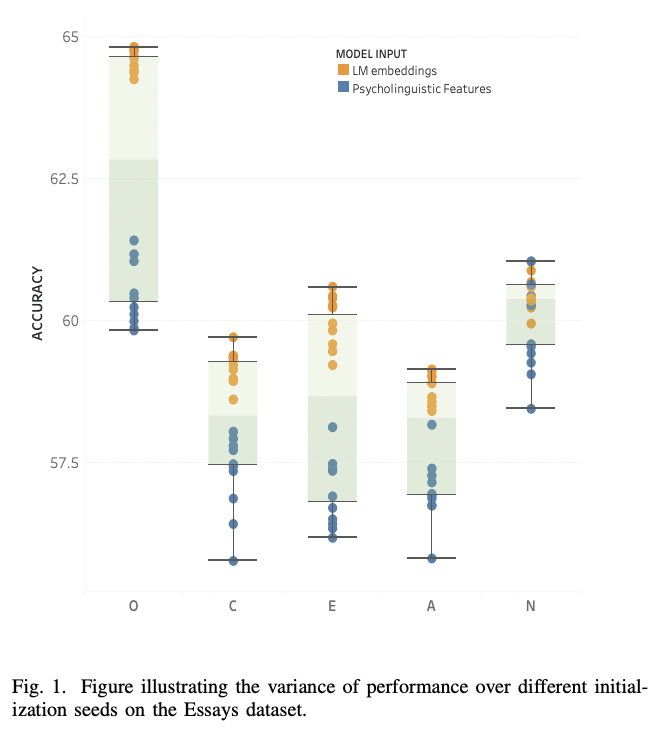 |
Befolgen Sie die folgenden Schritte zur Vorhersage der Persönlichkeit (z. B. der Big-Five: Ocean Merkmale) in einem neuen Text/Aufsatz:
python finetune_models/MLP_LM.py -save_model ' yes 'Verwenden Sie nun das folgende Skript, um den unsichtbaren Text vorherzusagen:
python unseen_predictor.pyLM_extractor.pyAuf einem RTX2080-GPU dauert der EMBED 'Bert-Base' Extraktor ungefähr ~ 2 m 30 und 'Bert-Large' ca. ~ 5 m 30s
Auf einer CPU dauert der BERT-BASE-Extraktor ungefähr ~ 25 m
python finetune_models/MLP_LM.pyAuf einer RTX2080-GPU, die 15 Epochen (ohne Kreuzvalidierung) läuft, dauert je nach MLP-Architektur 5S-60er Jahre.
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}Wenn Sie dieses Repo für Ihre Forschung nützlich finden, zitieren Sie sie bitte mit Folgendem:
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}Der Quellcode für dieses Projekt ist unter der MIT -Lizenz lizenziert.


