personality prediction
Code for ICDM'20 paper

Este repositório contém código para o papel de baixo e de cima para baixo: prever a personalidade com recursos psicolinguísticos e de modelos de idiomas, publicados na Conferência Internacional da IEEE de mineração de dados 2020 .
Aqui estão um conjunto de experimentos escritos no TensorFlow + Pytorch para explorar a detecção automatizada de personalidade usando modelos de idiomas no conjunto de dados de ensaios (traços de personalidade grandes e cinco) e o conjunto de dados Kaggle MBTI.
Puxe o repositório do Github, seguido pela criação de um novo ambiente virtual (CONDA ou VENV):
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10Instale a poesia e use -o para instalar as dependências necessárias para a execução do projeto:
curl - sSL https : // install . python - poetry . org | python3 -
poetry install Primeiro execute o código do extrator LM que passa o conjunto de dados pelo modelo de idioma e armazena as incorporações (de todas as camadas) em um arquivo de picles. Criar esse 'novo conjunto de dados' nos economiza muito tempo de computação e permite uma pesquisa eficaz dos hiperparâmetros da rede Finetuning. Antes de executar o código, crie uma pasta PKL_DATA na pasta repo. Todos os argumentos são opcionais e não passam nenhum argumento executa o extrator com os valores padrão.
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data 'Em seguida, execute um modelo de Finetuning para obter os recursos extraídos como entrada do arquivo de picles e treinar um modelo de Finetuning. Encontramos um MLP superficial para ser o melhor desempenho
python finetune_models/MLP_LM.py| Tabela de resultados | Modelos de idiomas vs características psicolinguísticas |
|---|---|
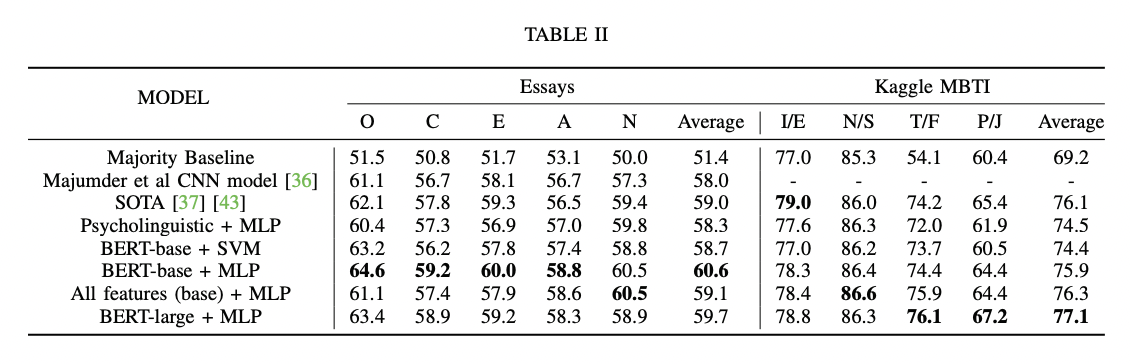 | 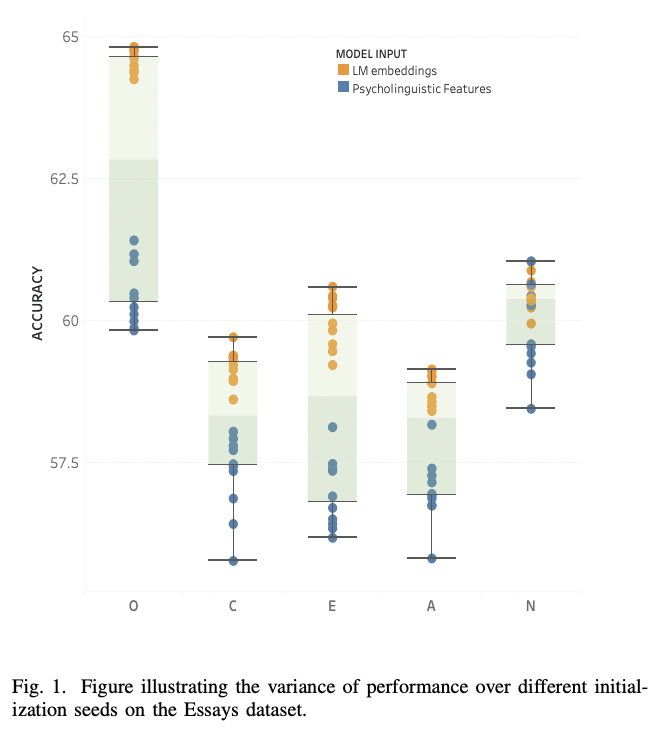 |
Siga as etapas abaixo para prever a personalidade (por exemplo, os Big-Five: Ocean Traits) em um novo texto/ensaio:
python finetune_models/MLP_LM.py -save_model ' yes 'Agora use o script abaixo para prever o texto invisível:
python unseen_predictor.pyLM_extractor.pyEm uma GPU RTX2080, o extrator 'Bert-Base' -Embed leva cerca de ~ 2m 30s e 'Bert-Large' leva cerca de ~ 5m 30s
Em uma CPU, o extrator 'Bert-Base' leva cerca de ~ 25m
python finetune_models/MLP_LM.pyEm uma GPU RTX2080, a execução de 15 épocas (sem validação cruzada) leva dos 5S-60s, dependendo da arquitetura MLP.
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}Se você achar esse repositório útil para sua pesquisa, cite -o usando o seguinte:
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}O código -fonte deste projeto é licenciado sob a licença do MIT.


