personality prediction
Code for ICDM'20 paper

Este repositorio contiene código para el documento de abajo hacia arriba y de arriba hacia abajo: predecir la personalidad con características del modelo psicolingüístico y de idioma, publicado en IEEE International Conference of Data Mining 2020 .
Aquí hay un conjunto de experimentos escritos en TensorFlow + Pytorch para explorar la detección de personalidad automatizada utilizando modelos de lenguaje en el conjunto de datos de ensayos (rasgos etiquetados con personalidad de Big-Five) y el conjunto de datos Kaggle MBTI.
Tire del repositorio de GitHub, seguido de la creación de un nuevo entorno virtual (conda o venv):
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10Instale la poesía y use eso para instalar las dependencias requeridas para ejecutar el proyecto:
curl - sSL https : // install . python - poetry . org | python3 -
poetry install Primero ejecute el código LM Extractor que pasa el conjunto de datos a través del modelo de idioma y almacena las incrustaciones (de todas las capas) en un archivo de encurtido. La creación de este 'nuevo conjunto de datos' nos ahorra mucho tiempo de cómputo y permite una búsqueda efectiva de los hiperparámetros para la red Finetuning. Antes de ejecutar el código, cree una carpeta PKL_DATA en la carpeta Repo. Todos los argumentos son opcionales y que no sean argumentos ejecuta el extractor con los valores predeterminados.
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data 'A continuación, ejecute un modelo Finetuning para tomar las características extraídas como entrada del archivo de encurtido y entrenar un modelo de Finetuning. Encontramos un MLP poco profundo para ser el mejor desempeño
python finetune_models/MLP_LM.py| Tabla de resultados | Modelos de idiomas frente a rasgos psicolingüísticos |
|---|---|
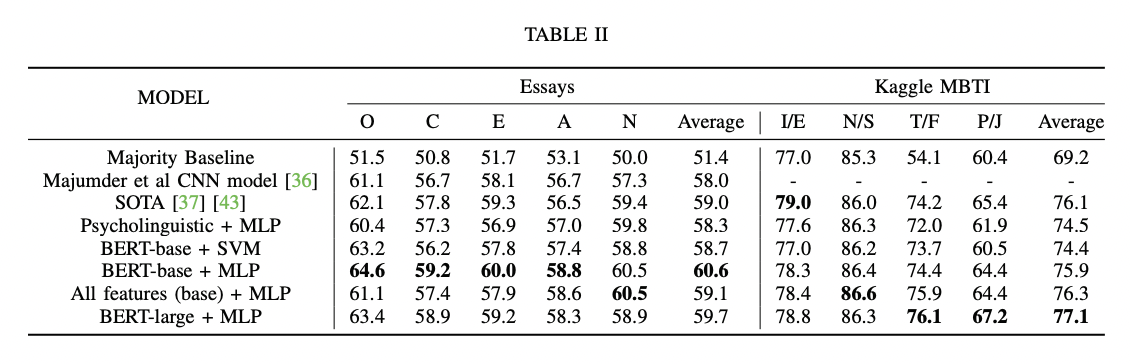 | 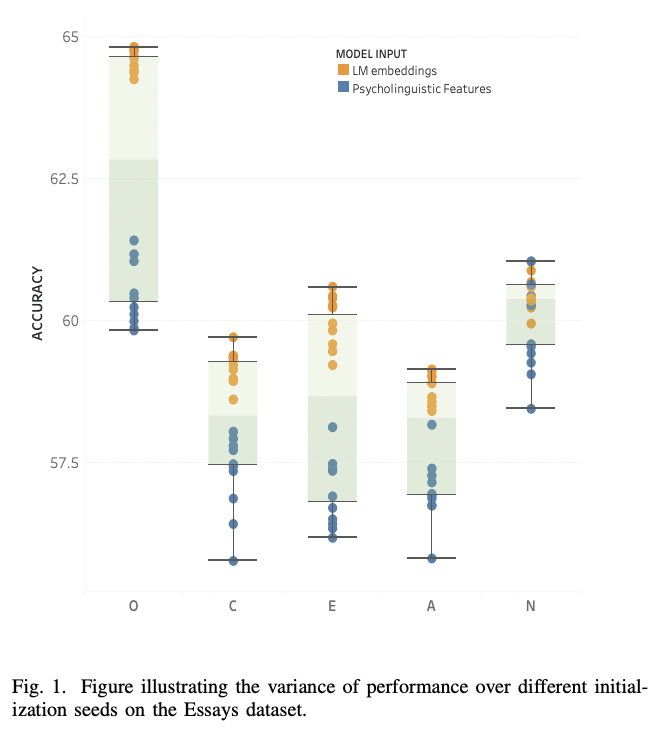 |
Siga los pasos a continuación para predecir la personalidad (por ejemplo, los cinco grandes: rasgos oceánicos) en un nuevo texto/ensayo:
python finetune_models/MLP_LM.py -save_model ' yes 'Ahora use el script a continuación para predecir el texto invisible:
python unseen_predictor.pyLM_extractor.pyEn una GPU RTX2080, el extractor 'Bert-Base'-Embed toma alrededor de ~ 2m 30s y 'Bert-Large' toma alrededor de ~ 5m 30s
En una CPU, el extractor 'Bert-Base' toma alrededor de ~ 25 m
python finetune_models/MLP_LM.pyEn una GPU RTX2080, que se ejecuta para 15 épocas (sin validación cruzada) toma de 5S-60, dependiendo de la arquitectura MLP.
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}Si encuentra este repositorio útil para su investigación, cíquelo usando lo siguiente:
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}El código fuente para este proyecto tiene licencia bajo la licencia MIT.


