personality prediction
Code for ICDM'20 paper

이 저장소에는 IEEE 국제 데이터 마이닝 회의 2020 에 발표 된 심리 언어 및 언어 모델 기능을 갖춘 종이 상향식 및 하향식에 대한 코드가 포함되어 있습니다.
다음은 Tensorflow + Pytorch로 작성된 실험 세트입니다. 에세이 데이터 세트 (큰 특성 레이블이 붙은 특성) 및 Kaggle MBTI 데이터 세트의 언어 모델을 사용하여 자동화 된 성격 탐지를 탐색합니다.
github에서 저장소를 당기고 새로운 가상 환경 (Conda 또는 Venv)을 만듭니다.
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10시를 설치하고이를 사용하여 프로젝트 실행에 필요한 종속성을 설치하십시오.
curl - sSL https : // install . python - poetry . org | python3 -
poetry install 먼저 언어 모델을 통해 데이터 세트를 전달하는 LM 추출기 코드를 실행하고 피클 파일에 임베딩 (모든 레이어)을 저장합니다. 이 '새로운 데이터 세트'를 작성하면 많은 컴퓨팅 시간을 절약 할 수 있으며 Finetuning Network에 대한 하이퍼 파라미터를 효과적으로 검색 할 수 있습니다. 코드를 실행하기 전에 Repo 폴더에서 PKL_DATA 폴더를 만듭니다. 모든 인수는 선택 사항이며 인수를 전달하지 않으면 기본값이있는 추출기를 실행하지 않습니다.
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data '다음으로 Finetuning 모델을 실행하여 추출 된 기능을 피클 파일의 입력으로 가져 와서 Finetuning 모델을 훈련시킵니다. 우리는 얕은 MLP가 최고의 성과를 거두는 것을 발견했습니다.
python finetune_models/MLP_LM.py| 결과 테이블 | 언어 모델 대 심리 언어 특성 |
|---|---|
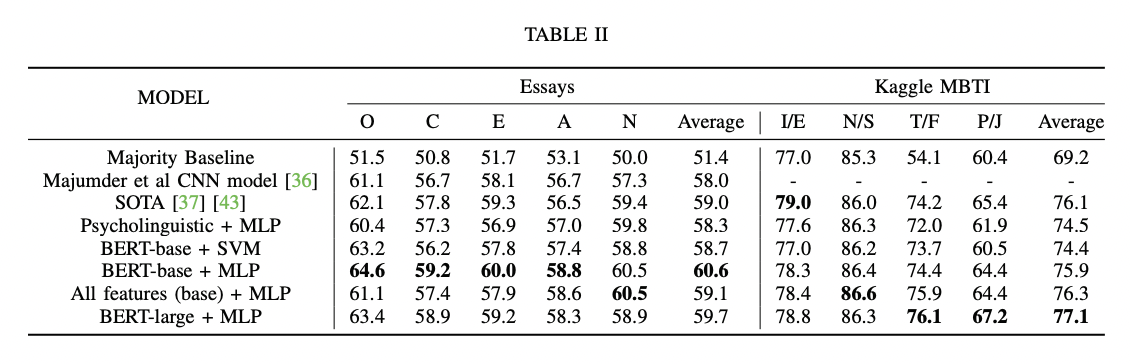 | 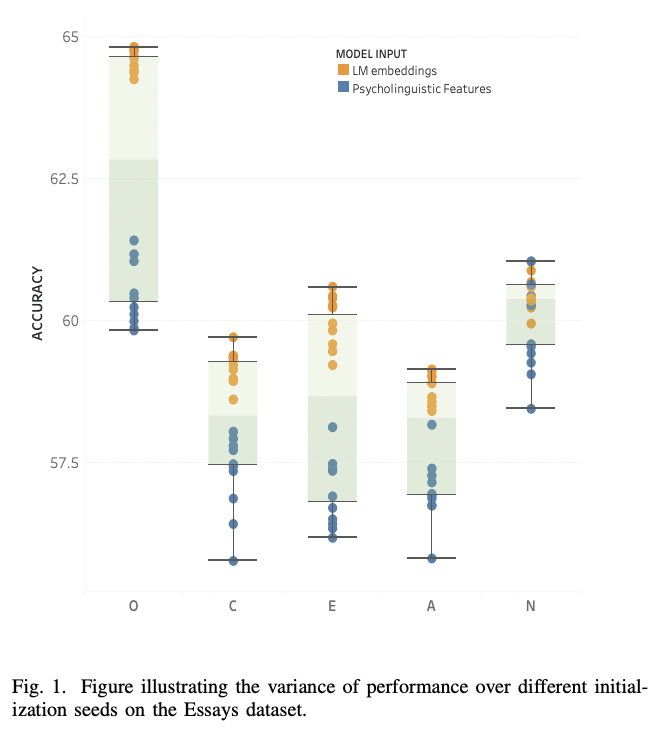 |
새로운 텍스트/에세이에서 성격을 예측하는 (예 : 큰 5 : 해양 특성)를 예측하려면 아래 단계를 따르십시오.
python finetune_models/MLP_LM.py -save_model ' yes '이제 아래 스크립트를 사용하여 보이지 않는 텍스트를 예측하십시오.
python unseen_predictor.pyLM_extractor.pyRTX2080 GPU에서, -Embed 'Bert-Base'추출기는 약 ~ 2m 30 초, 'Bert-Large'는 약 ~ 5m 30 초에 걸립니다.
CPU에서 'Bert-Base'추출기는 약 ~ 25m가 걸립니다
python finetune_models/MLP_LM.pyRTX2080 GPU에서는 15 개의 에포크 (교차 검증이없는)를 위해 실행되는 MLP 아키텍처에 따라 5S-60에서 실행됩니다.
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}이 repo가 귀하의 연구에 유용하다고 생각되면 다음을 사용하여 인용하십시오.
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}이 프로젝트의 소스 코드는 MIT 라이센스에 따라 라이센스가 부여됩니다.


