personality prediction
Code for ICDM'20 paper

Ce référentiel contient du code pour l'article ascendant et de haut en bas: prédire la personnalité avec des fonctionnalités psycholinguistiques et des modèles linguistiques, publié dans la conférence internationale de l'IEEE sur l'exploitation de données 2020 .
Voici un ensemble d'expériences écrites dans TensorFlow + Pytorch pour explorer la détection de personnalité automatisée à l'aide de modèles de langage sur l'ensemble de données des essais (traits de la personnalité Big-Five) et l'ensemble de données Kaggle MBTI.
Tirez le référentiel de GitHub, suivi par la création d'un nouvel environnement virtuel (conda ou venv):
git clone https : // github . com / yashsmehta / personality - prediction . git
cd personality - prediction
conda create - n mvenv python = 3.10Installez la poésie et utilisez-le pour installer les dépendances requises pour exécuter le projet:
curl - sSL https : // install . python - poetry . org | python3 -
poetry install Exécutez d'abord le code d'extracteur LM qui passe l'ensemble de données via le modèle de langue et stocke les incorporations (de toutes les couches) dans un fichier de cornichon. La création de ce «nouvel ensemble de données» nous fait gagner beaucoup de temps de calcul et permet une recherche efficace des hyperparamètres pour le réseau Finetuning. Avant d'exécuter le code, créez un dossier PKL_DATA dans le dossier Repo. Tous les arguments sont facultatifs et ne passant aucun argument exécute l'extracteur avec les valeurs par défaut.
python LM_extractor.py -dataset_type ' essays ' -token_length 512 -batch_size 32 -embed ' bert-base ' -op_dir ' pkl_data 'Exécutez ensuite un modèle de finetuning pour prendre les fonctionnalités extraites en entrée du fichier de cornichon et former un modèle de financement. Nous trouvons un MLP peu profond comme le plus performant
python finetune_models/MLP_LM.py| Tableau de résultats | Modèles linguistiques vs traits psycholinguistiques |
|---|---|
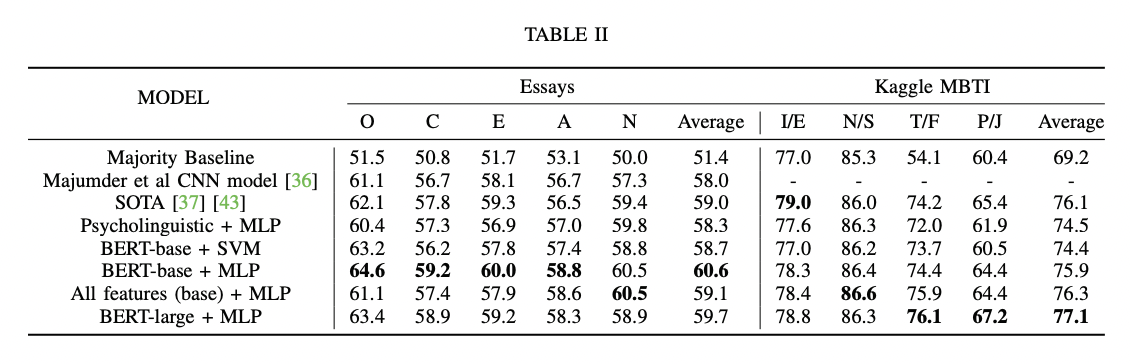 | 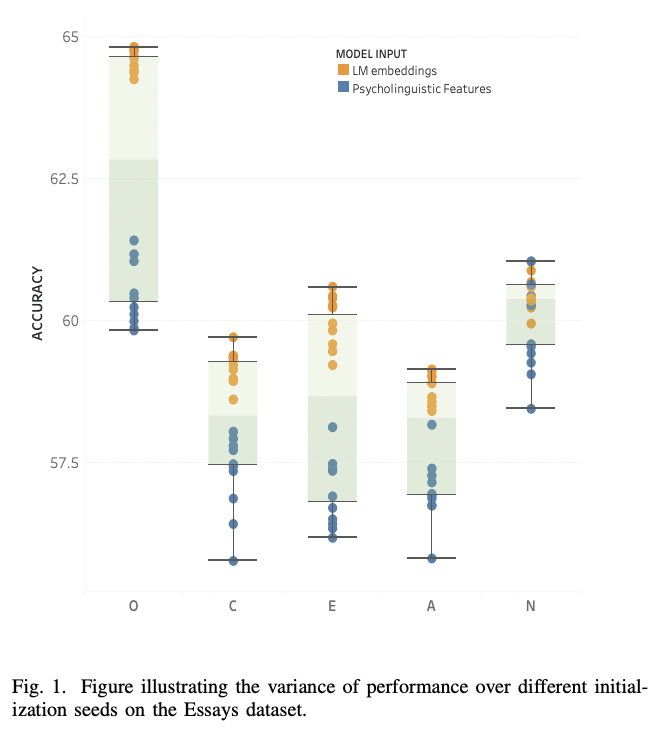 |
Suivez les étapes ci-dessous pour prédire la personnalité (par exemple, les Big-Five: Ocean Traits) sur un nouvel texte / essai:
python finetune_models/MLP_LM.py -save_model ' yes 'Utilisez maintenant le script ci-dessous pour prédire le texte invisible:
python unseen_predictor.pyLM_extractor.pySur un GPU RTX2080, l'extracteur `` Bert-base '' lancé prend environ ~ 2m 30s et «bert-large» prend environ ~ 5m 30s
Sur un processeur, l'extracteur «Bert-base» prend environ ~ 25 m
python finetune_models/MLP_LM.pySur un GPU RTX2080, en cours d'exécution pour 15 époques (sans validation croisée) tire de 5S à 60, selon l'architecture MLP.
@article { mehta2020recent ,
title = { Recent Trends in Deep Learning Based Personality Detection } ,
author = { Mehta, Yash and Majumder, Navonil and Gelbukh, Alexander and Cambria, Erik } ,
journal = { Artificial Intelligence Review } ,
pages = { 2313–2339 } ,
year = { 2020 } ,
doi = { https://doi.org/10.1007/s10462-019-09770-z } ,
url = { https://link.springer.com/article/10.1007/s10462-019-09770-z }
publisher= { Springer }
}Si vous trouvez ce dépôt utile pour vos recherches, veuillez le citer en utilisant les éléments suivants:
@inproceedings { mehta2020bottom ,
title = { Bottom-up and top-down: Predicting personality with psycholinguistic and language model features } ,
author = { Mehta, Yash and Fatehi, Samin and Kazameini, Amirmohammad and Stachl, Clemens and Cambria, Erik and Eetemadi, Sauleh } ,
booktitle = { 2020 IEEE International Conference on Data Mining (ICDM) } ,
pages = { 1184--1189 } ,
year = { 2020 } ,
organization = { IEEE }
}Le code source de ce projet est concédé sous licence MIT.


