Calibrated BERT Fine Tuning
1.0.0
repo นี้มีรหัสของเราสำหรับกระดาษ:
การปรับแต่งโมเดลภาษาที่ปรับเทียบสำหรับข้อมูลทั้งในและนอกการแจกจ่าย EMNLP2020
[กระดาษ] [สไลด์]
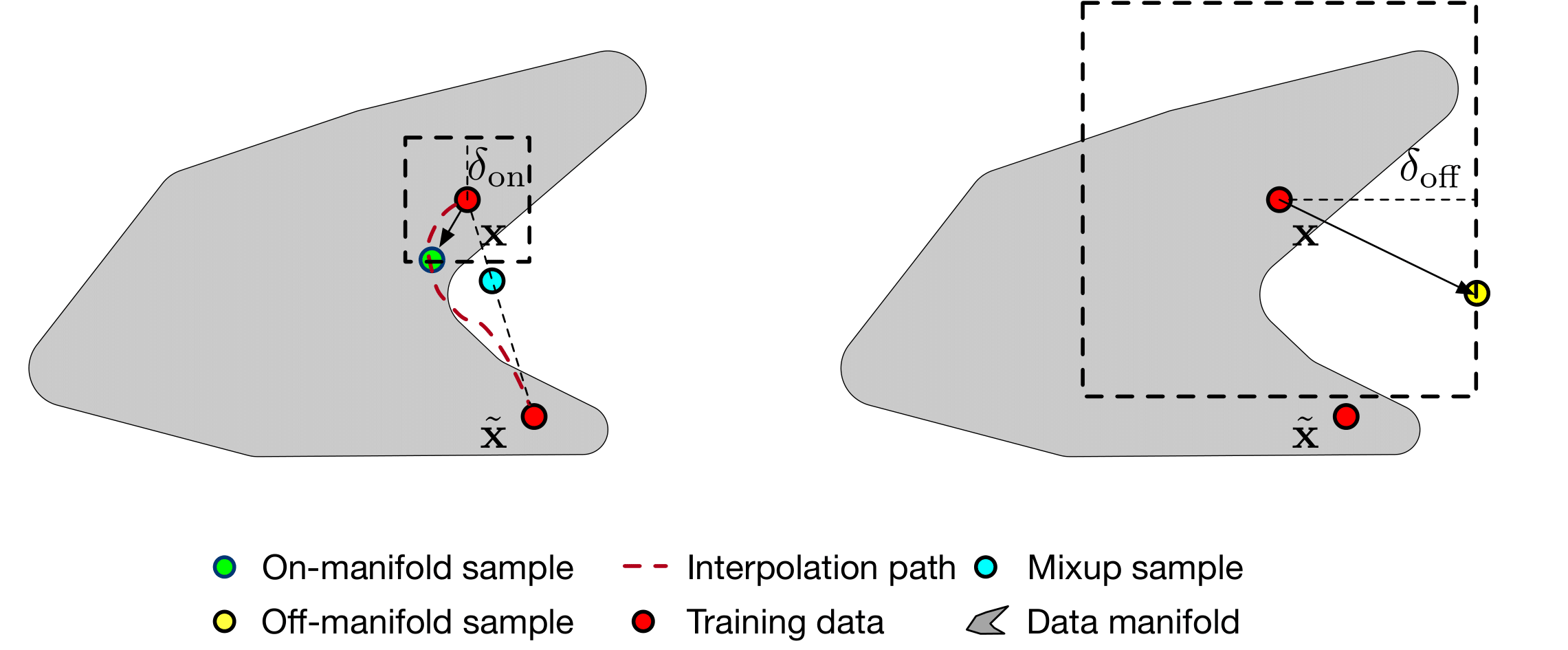
การฝึกอบรมกับ Bert Base:
CUDA_VISIBLE_DEVICES=0 python bert.py --dataset 20news-15 --seed 0
การฝึกอบรมด้วยการปรับให้เรียบ
CUDA_VISIBLE_DEVICES=0,1 python manifold-smoothing.py --dataset 20news-15 --seed 0 --eps_in 0.0001 --eps_out 0.001 --eps_y 0.1
การประเมินผลด้วยฐานเบิร์ต
python test.py --model base --in_dataset 20news-15 --out_dataset 20news-5 --index 0
การประเมินผลด้วยการปรับขนาดอุณหภูมิ [1] (ขึ้นอยู่กับโมเดล Bert-Base ที่ผ่านการฝึกอบรม)
python test.py --model temperature --in_dataset 20news-15 --out_dataset 20news-5 --index 0
การประเมินผลด้วย MC-Dropout [2] (ขึ้นอยู่กับโมเดล Bert-Base ที่ผ่านการฝึกอบรม)
python test.py --model mc-dropout --in_dataset 20news-15 --out_dataset 20news-5 --eva_iter 10 --index 0
การประเมินด้วยการปรับให้เรียบ
python test.py --model manifold-smoothing --in_dataset 20news-15 --out_dataset 20news-5 --eps_in 0.0001 --eps_out 0.001 --eps_y 0.1
[1] Guo, Chuan, Geoff Pleiss, Yu Sun และ Kilian Q. Weinberger "ในการสอบเทียบเครือข่ายประสาทที่ทันสมัย" ใน การประชุมนานาชาติเกี่ยวกับการเรียนรู้ของเครื่อง , หน้า 1321-1330 2017.
[2] Gal, Yarin และ Zoubin Ghahramani "การออกกลางคันเป็นการประมาณแบบเบย์: แสดงถึงความไม่แน่นอนของแบบจำลองในการเรียนรู้อย่างลึกซึ้ง" ใน การประชุมนานาชาติเกี่ยวกับการเรียนรู้ของเครื่อง , หน้า 1050-1059 2559.


