Calibrated BERT Fine Tuning
1.0.0
Dieses Repo enthält unseren Code für Papier:
Kalibriertes Sprachmodell Feinabstimmung für In- und Nichtverteilungsdaten, EMNLP2020.
[Papier] [Folien]
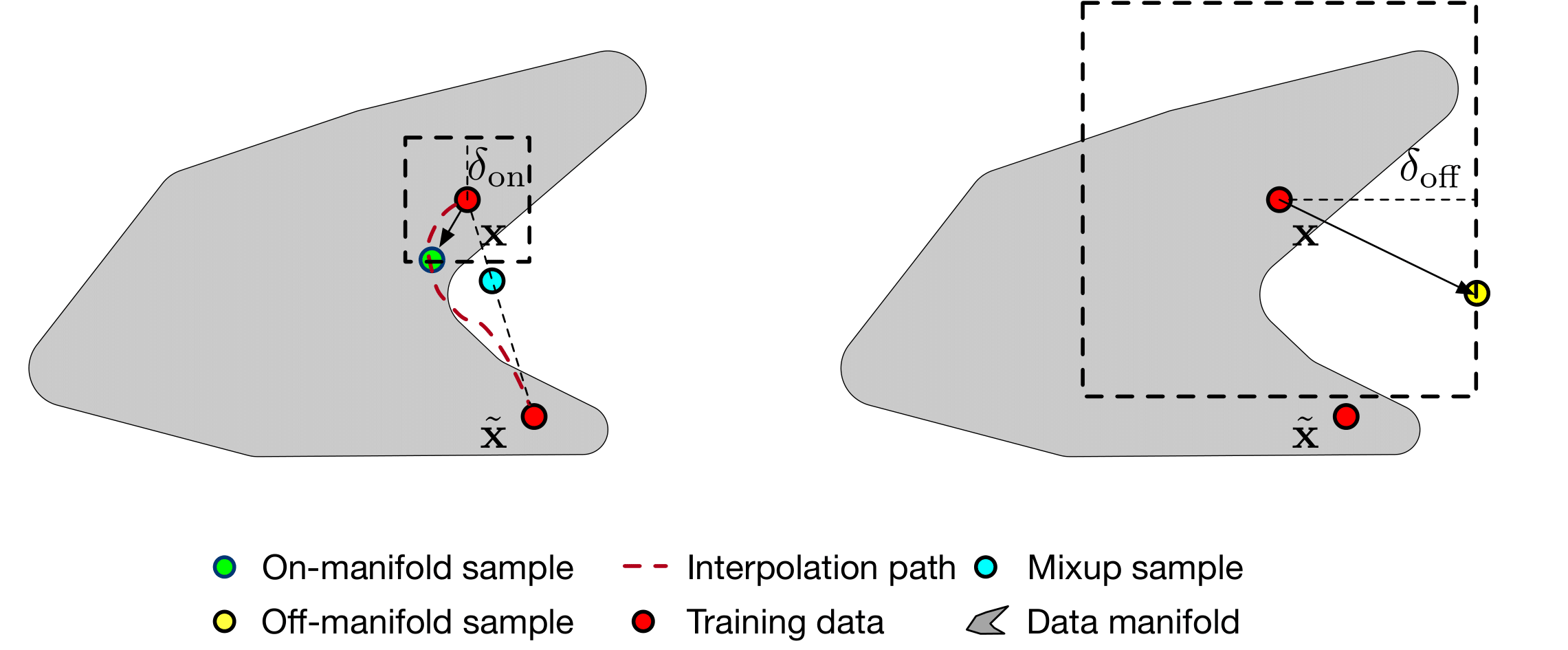
Training mit Bert Base:
CUDA_VISIBLE_DEVICES=0 python bert.py --dataset 20news-15 --seed 0
Training mit vielfältiger Glättung
CUDA_VISIBLE_DEVICES=0,1 python manifold-smoothing.py --dataset 20news-15 --seed 0 --eps_in 0.0001 --eps_out 0.001 --eps_y 0.1
Bewertung mit Bert Base
python test.py --model base --in_dataset 20news-15 --out_dataset 20news-5 --index 0
Bewertung mit Temperaturskalierung [1] (basierend auf dem geschulten Bert-Base-Modell)
python test.py --model temperature --in_dataset 20news-15 --out_dataset 20news-5 --index 0
Bewertung mit MC-Dropout [2] (basierend auf dem geschulten Bert-Base-Modell)
python test.py --model mc-dropout --in_dataset 20news-15 --out_dataset 20news-5 --eva_iter 10 --index 0
Bewertung mit vielfältiger Glättung
python test.py --model manifold-smoothing --in_dataset 20news-15 --out_dataset 20news-5 --eps_in 0.0001 --eps_out 0.001 --eps_y 0.1
[1] Guo, Chuan, Geoff Pleiss, Yu Sun und Kilian Q. Weinberger. "Über die Kalibrierung moderner neuronaler Netzwerke." In der Internationalen Konferenz über maschinelles Lernen , S. 1321-1330. 2017.
[2] Gal, Yarin und Zoubin Ghahramani. "Ausfall als Bayes'sche Näherung: Darstellung der Modellunsicherheit im tiefen Lernen." In der Internationalen Konferenz über maschinelles Lernen , S. 1050-1059. 2016.


