Calibrated BERT Fine Tuning
1.0.0
Este repo contém nosso código para papel:
Modelo de idioma calibrado Tuneamento fino para dados internos e fora de distribuição, EMNLP2020.
[Papel] [slides]
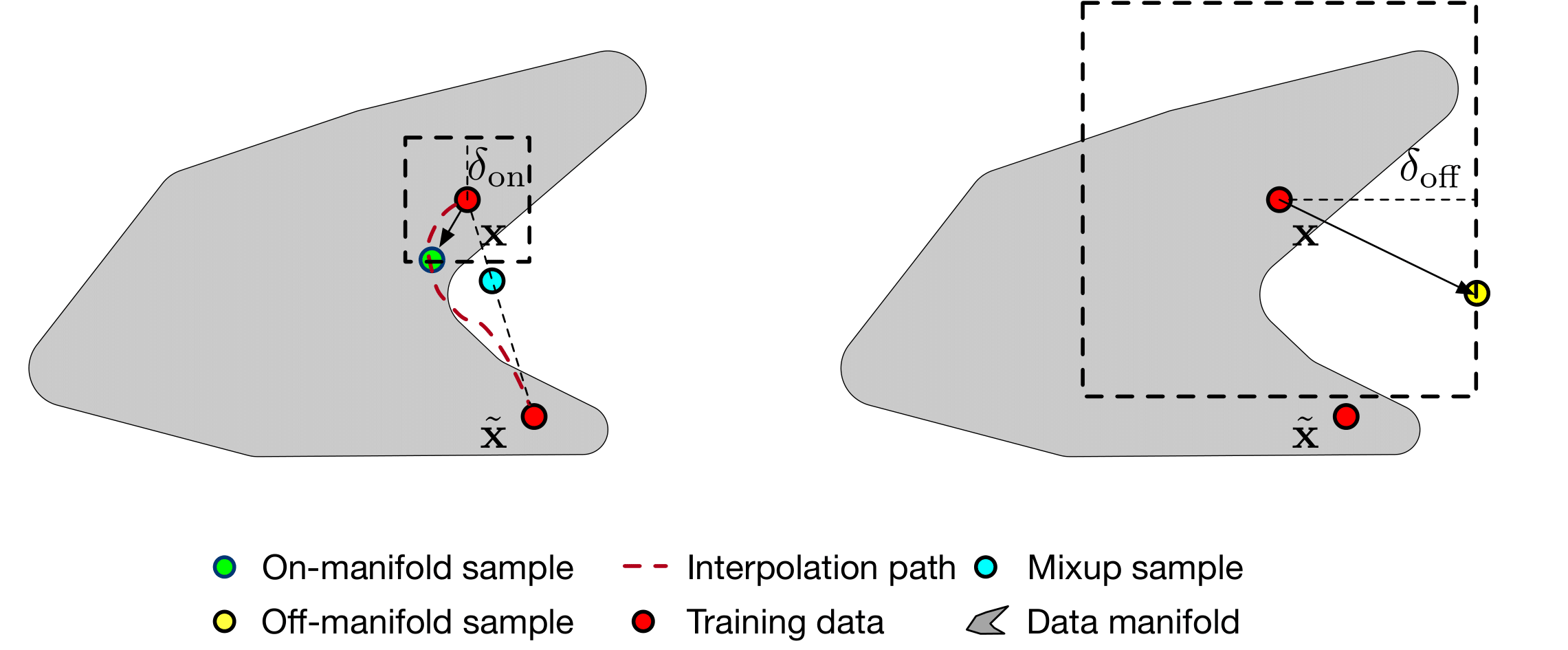
Treinamento com Bert Base:
CUDA_VISIBLE_DEVICES=0 python bert.py --dataset 20news-15 --seed 0
Treinamento com suavização múltipla
CUDA_VISIBLE_DEVICES=0,1 python manifold-smoothing.py --dataset 20news-15 --seed 0 --eps_in 0.0001 --eps_out 0.001 --eps_y 0.1
Avaliação com Bert Base
python test.py --model base --in_dataset 20news-15 --out_dataset 20news-5 --index 0
Avaliação com escala de temperatura [1] (com base no modelo treinado de base bert)
python test.py --model temperature --in_dataset 20news-15 --out_dataset 20news-5 --index 0
Avaliação com MC-Dropout [2] (com base no modelo treinado de Bert-Base)
python test.py --model mc-dropout --in_dataset 20news-15 --out_dataset 20news-5 --eva_iter 10 --index 0
Avaliação com suavização de múltiplos
python test.py --model manifold-smoothing --in_dataset 20news-15 --out_dataset 20news-5 --eps_in 0.0001 --eps_out 0.001 --eps_y 0.1
[1] Guo, Chuan, Geoff Pleiss, Yu Sun e Kilian Q. Weinberger. "Sobre a calibração de redes neurais modernas". Em Conferência Internacional sobre Aprendizado de Máquinas , pp. 1321-1330. 2017.
[2] Gal, Yarin e Zoubin Ghahramani. "Destacamento como uma aproximação bayesiana: representando a incerteza do modelo na aprendizagem profunda". Em Conferência Internacional sobre Aprendizado de Máquinas , pp. 1050-1059. 2016.


