Calibrated BERT Fine Tuning
1.0.0
Ce repo contient notre code pour papier:
Modèle de langue calibré Fonction des données pour les données dans la distribution, EMNLP2020.
[Papier] [Diaposités]
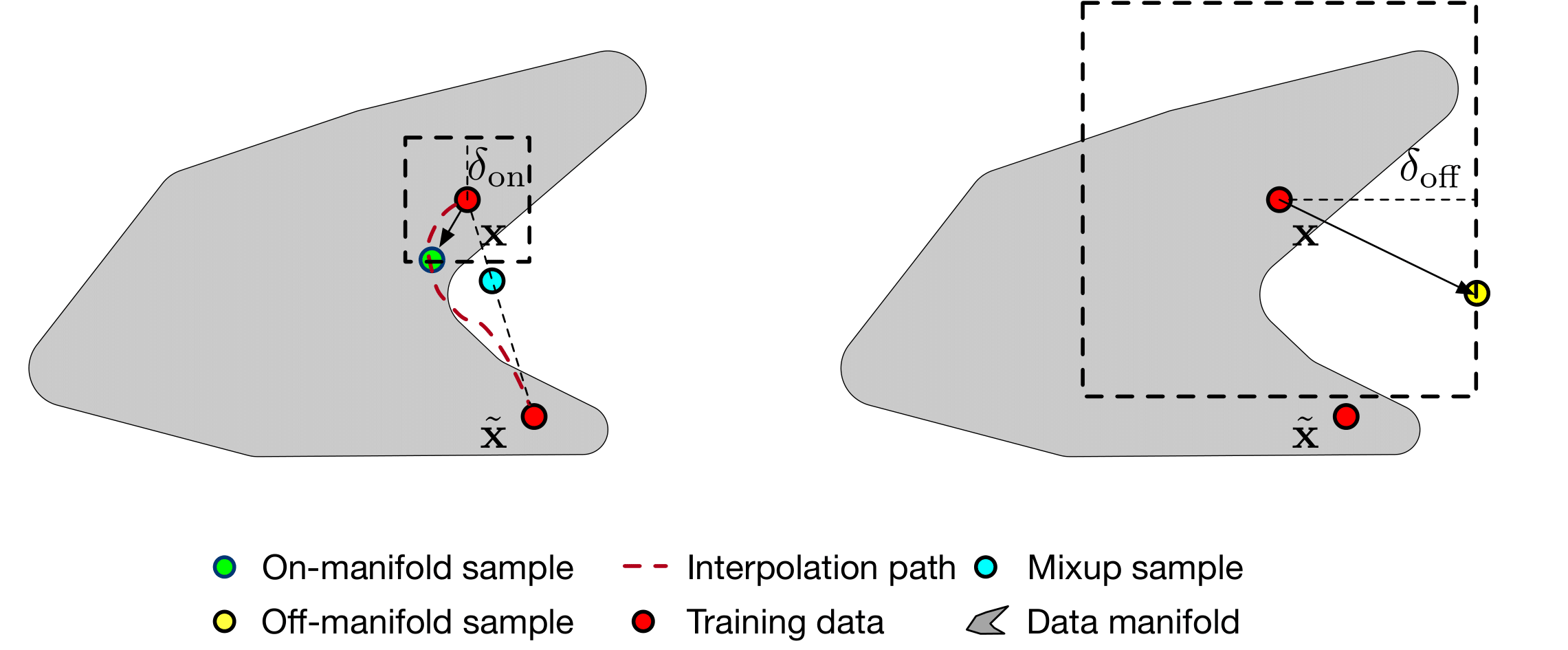
Formation avec Bert Base:
CUDA_VISIBLE_DEVICES=0 python bert.py --dataset 20news-15 --seed 0
Formation avec le lissage du collecteur
CUDA_VISIBLE_DEVICES=0,1 python manifold-smoothing.py --dataset 20news-15 --seed 0 --eps_in 0.0001 --eps_out 0.001 --eps_y 0.1
Évaluation avec Bert Base
python test.py --model base --in_dataset 20news-15 --out_dataset 20news-5 --index 0
Évaluation avec échelle de température [1] (basée sur le modèle de base Bert formé)
python test.py --model temperature --in_dataset 20news-15 --out_dataset 20news-5 --index 0
Évaluation avec MC-Dropout [2] (basé sur le modèle de base Bert formé)
python test.py --model mc-dropout --in_dataset 20news-15 --out_dataset 20news-5 --eva_iter 10 --index 0
Évaluation avec lissage multiple
python test.py --model manifold-smoothing --in_dataset 20news-15 --out_dataset 20news-5 --eps_in 0.0001 --eps_out 0.001 --eps_y 0.1
[1] Guo, Chuan, Geoff Pleiss, Yu Sun et Kilian Q. Weinberger. "Sur l'étalonnage des réseaux de neurones modernes." Dans International Conference on Machine Learning , pp. 1321-1330. 2017.
[2] Gal, Yarin et Zoubin Ghahramani. "Abrochage en tant qu'approximation bayésienne: représenter l'incertitude du modèle dans l'apprentissage en profondeur." Dans International Conference on Machine Learning , pp. 1050-1059. 2016.


