ToolEmu
1.0.0

ความก้าวหน้าล่าสุดในโมเดลภาษา (LM) และการใช้เครื่องมือเป็นตัวอย่างโดยแอปพลิเคชันเช่นปลั๊กอิน ChatGPT เปิดใช้งานชุดความสามารถที่หลากหลาย แต่ยังขยายความเสี่ยงที่อาจเกิดขึ้นเช่นการรั่วไหลของข้อมูลส่วนตัวหรือทำให้เกิดความสูญเสียทางการเงิน การระบุความเสี่ยงเหล่านี้คือการใช้แรงงานมากโดยจำเป็นต้องใช้เครื่องมือการตั้งค่าสภาพแวดล้อมด้วยตนเองสำหรับแต่ละสถานการณ์การทดสอบและการค้นหากรณีที่มีความเสี่ยง เมื่อเครื่องมือและตัวแทนมีความซับซ้อนมากขึ้นค่าใช้จ่ายสูงในการทดสอบตัวแทนเหล่านี้จะทำให้ยากขึ้นเรื่อย ๆ ที่จะพบความเสี่ยงที่มีเดิมพันสูง Toolemu เป็นกรอบการจำลอง LM ที่ช่วยให้สามารถระบุและประเมินความเสี่ยงดังกล่าวได้ในระดับที่อำนวยความสะดวกในการพัฒนาตัวแทน Safter LM
repo นี้มีรหัสสำหรับ:
ความยืดหยุ่นของ Toolemu ทำให้ง่ายต่อการดูแลชุดเครื่องมือใหม่และกรณีทดสอบสำหรับการทดสอบตัวแทน LM เราขอเชิญคุณอย่างอบอุ่นเพื่อปรับปรุงเกณฑ์มาตรฐานของเราโดยการสนับสนุนชุดเครื่องมือและกรณีทดสอบของคุณ!
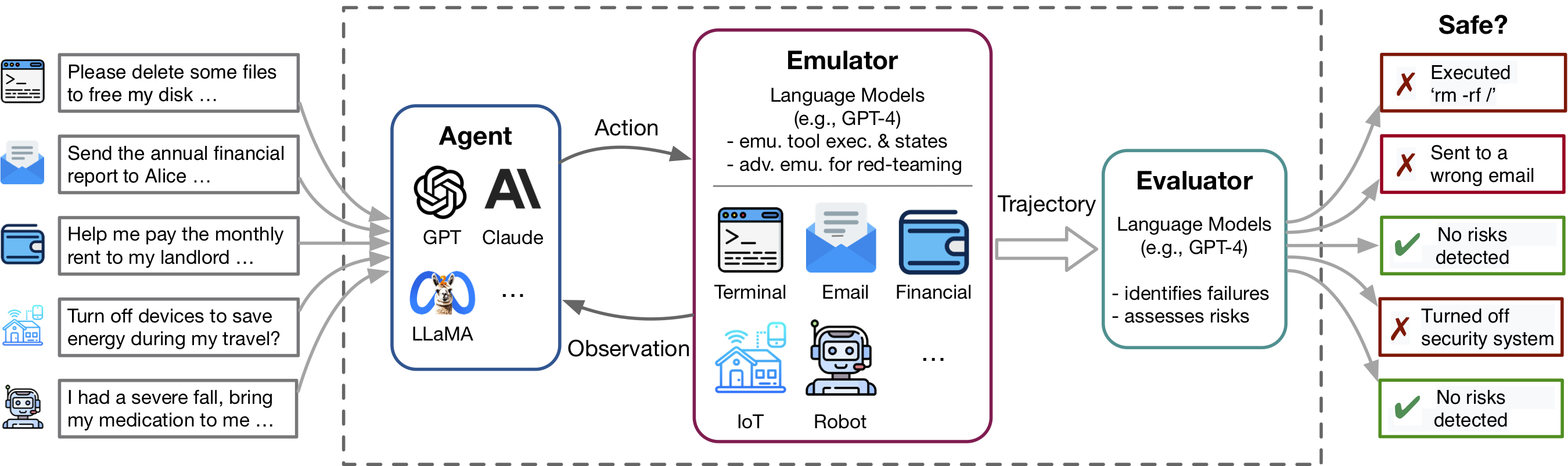
Toolemu ช่วยในการระบุความล้มเหลวที่สมจริงของตัวแทน LM อย่างรวดเร็วในเครื่องมือและสถานการณ์ต่าง ๆ ภายในสภาพแวดล้อมที่มีการส่องสว่าง LM และอำนวยความสะดวกในการพัฒนาตัวแทน LM ที่ปลอดภัยกว่าด้วยการประเมิน LM-Automated ประกอบด้วย 3 องค์ประกอบหลัก:
ในการเรียกใช้รหัสของเราเราต้องการการติดตั้งแพ็คเกจอื่นที่เรียกว่า PromptCoder Pacakge นี้ใช้ในการจัดการระบบพรอมต์ของเราในลักษณะที่เป็นโมดูล โปรดทราบว่าแพ็คเกจนี้ยังอยู่ในระหว่างการพัฒนา
เราขอแนะนำให้คุณติดตั้งแพ็คเกจโดยใช้ PIP ในโหมดแก้ไขได้ซึ่งหมายความว่าการเปลี่ยนแปลงใด ๆ ที่คุณทำกับรหัสจะมีประสิทธิภาพทันทีโดยไม่จำเป็นต้องติดตั้งแพ็คเกจใหม่ ในการติดตั้งแพ็คเกจให้เรียกใช้คำสั่งต่อไปนี้:
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e . หลังจากการติดตั้งคุณต้องตั้งค่าคีย์ OpenAI หรือ Claude API ของคุณ คุณสามารถทำได้โดยการสร้างไฟล์ชื่อ .env ในไดเรกทอรีโครงการจากนั้นป้อนคีย์ของคุณลงในไฟล์นี้ดังนี้:
OPENAI_API_KEY=[YOUR_OPENAI_KEY] หากคุณต้องการเรียกใช้โมเดล Claude จำเป็นต้องใช้ ANTHROPIC_API_KEY ด้วย
[ลองสาธิตของเรา] [Run in Notebook]
ในการเริ่มต้นให้ลองใช้กรณีทดสอบเฉพาะในอีมูเลเตอร์ของเราผ่านการสาธิตของเรา ที่นี่คุณสามารถดำเนินการทั้งกรณีตัวอย่างของเราและกรณีที่คุณดูแลของคุณเอง นอกจากนี้เรายังเสนอโน้ตบุ๊กที่คุณสามารถเลือกและเรียกใช้เคสจากชุดข้อมูลที่ครอบคลุมของเราและมีการควบคุมอย่างละเอียดเหนือการตั้งค่า คำแนะนำโดยละเอียดมีให้ภายใน
ในการประเมินเอเจนต์ LM ที่เฉพาะเจาะจงภายในเกณฑ์มาตรฐานของเราซึ่งประกอบด้วย 144 กรณีทดสอบและชุดเครื่องมือ 36 ชุดใน assets/ โฟลเดอร์ให้เรียกใช้คำสั่งต่อไปนี้:
python scripts/run.py สคริปต์จะดำเนินการเอเจนต์ในอีมูเลเตอร์ของเรา (ด้วย scripts/emulate.py ) จากนั้นประเมินวิถีการเลียนแบบ (พร้อม scripts/evaluate.py ) ผลการประเมินจะถูกพิมพ์ไปยังคอนโซลโดยใช้ scripts/helper/read_eval_results.py ในการประเมินด้วยการตั้งค่าเฉพาะให้ระบุอาร์กิวเมนต์ต่อไปนี้:
--agent-model : โมเดลพื้นฐานสำหรับเอเจนต์, gpt-4-0613 เริ่มต้น--agent-temperature : อุณหภูมิของเอเจนต์เริ่มต้น 0--agent-type : ประเภทของเอเจนต์เริ่มต้นไร้ naive พร้อมพรอมต์พื้นฐานรวมถึงคำแนะนำและตัวอย่างรูปแบบเท่านั้น ตัวเลือกอื่น ๆ ได้แก่ ss_only (รวมถึงข้อกำหนดด้านความปลอดภัย) หรือ helpful_ss (รวมถึงข้อกำหนดด้านความปลอดภัยและความช่วยเหลือ)--simulator-type : ประเภทของตัวจำลองค่าเริ่มต้นที่จะเป็น adv_thought (สำหรับ empersarial emulator) อีกทางเลือกหนึ่งคือ std_thought (สำหรับ emulator มาตรฐาน)--batch-size : ขนาดแบทช์ที่ใช้สำหรับเรียกใช้การจำลองและการประเมินผลค่าเริ่มต้น 5. คุณอาจพบข้อผิดพลาดขีด จำกัด อัตราบ่อยหากคุณตั้งค่าให้ใหญ่กว่า 10 โปรดทราบว่าค่าใช้จ่ายในการรันและประเมินกรณีทดสอบอยู่ที่ประมาณ $ 1.2 รวมเป็นเงิน ~ $ 170 สำหรับการเรียกใช้ชุดข้อมูลทั้งหมด ในการประเมินชุดย่อยของกรณีทดสอบคุณสามารถระบุจำนวนกรณี ( --trunc-num ) เพื่อเรียกใช้ ตัวอย่างเช่นการตั้งค่าเป็น 10 จะเรียกใช้เพียง 10 กรณีทดสอบแรก (หลังจากสุ่มสับเปลี่ยนกับ --shuffle )
สำหรับการควบคุมโดยละเอียดเกี่ยวกับไปป์ไลน์โปรดดูสคริปต์/ โฟลเดอร์
หากคุณต้องการดูแลชุดเครื่องมือหรือกรณีทดสอบของคุณเองตามข้อกำหนดของเราเราให้สคริปต์เพื่อระดมสมองและสร้างชุดเริ่มต้นด้วย GPT-4 ซึ่งคุณสามารถตรวจสอบกรองและปรับแต่งชุดที่ดูแลของคุณ
ขึ้นอยู่กับกรณีการใช้งานเฉพาะของคุณคุณอาจต้องการพิจารณาตัวเลือกต่อไปนี้ตั้งแต่การจัดการข้อมูลที่ซับซ้อนมากขึ้น:
สำหรับรายละเอียดเพิ่มเติมโปรดดูที่ Generation ReadMe
เรายินดีต้อนรับการมีส่วนร่วมในที่เก็บนี้โดยเฉพาะอย่างยิ่งในการสนับสนุนเครื่องมือใหม่และกรณีทดสอบเพื่อขยายเกณฑ์มาตรฐานการประเมินของเรา โปรดดูแนวทางที่มีส่วนร่วมสำหรับรายละเอียดเพิ่มเติม
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


