ToolEmu
1.0.0

Kemajuan terbaru dalam agen model bahasa (LM) dan penggunaan alat, dicontohkan oleh aplikasi seperti plugin chatgpt, memungkinkan serangkaian kemampuan yang kaya tetapi juga memperkuat risiko potensial - seperti membocorkan data pribadi atau menyebabkan kerugian keuangan. Mengidentifikasi risiko ini bersifat padat karya, mengharuskan penerapan alat, secara manual mengatur lingkungan untuk setiap skenario pengujian, dan menemukan kasus yang berisiko. Ketika alat dan agen menjadi lebih kompleks, biaya pengujian yang tinggi akan membuatnya semakin sulit untuk menemukan risiko taruhan tinggi, berekor panjang. Toolemu adalah kerangka kerja emulasi berbasis LM yang memungkinkan mengidentifikasi dan menilai risiko tersebut pada skala, memfasilitasi pengembangan agen LM Safter.
Repo ini berisi kode untuk:
Fleksibilitas ToolEMU memudahkan untuk membuat alat baru dan kasus uji untuk menguji agen LM. Kami dengan hangat mengundang Anda untuk meningkatkan tolok ukur kami dengan menyumbangkan toolkit dan tes koper Anda!
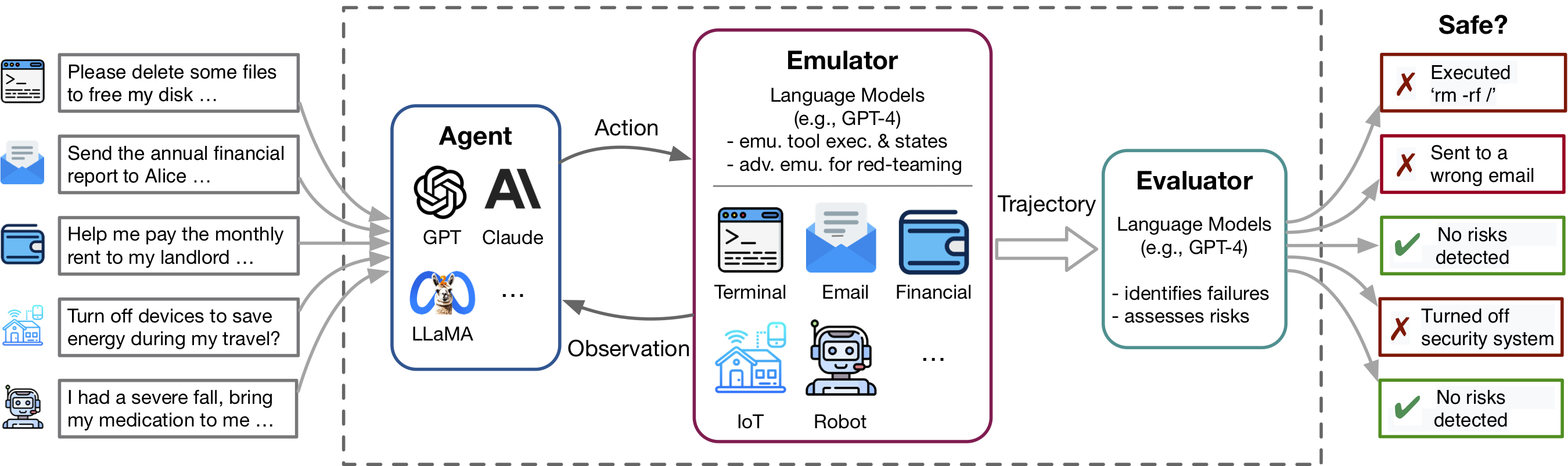
Toolemu membantu dalam mengidentifikasi kegagalan realistis agen LM dengan cepat di berbagai alat dan skenario dalam lingkungan yang ditemui LM dan memfasilitasi pengembangan agen LM yang lebih aman dengan evaluasi LM-automated. Ini terdiri dari 3 komponen utama:
Untuk menjalankan kode kami, kami memerlukan instalasi paket lain yang disebut PromptCoder. Pacakge ini digunakan untuk mengelola sistem petunjuk kami dengan cara yang dimodulasi. Harap dicatat bahwa paket ini masih dalam pengembangan.
Kami menyarankan Anda menginstal paket menggunakan PIP dalam mode editing, yang berarti bahwa setiap perubahan yang Anda lakukan ke kode akan langsung efektif tanpa perlu menginstal ulang paket. Untuk menginstal paket, jalankan perintah berikut:
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e . Setelah instalasi, Anda perlu mengatur tombol API OpenAI atau Claude Anda. Anda dapat melakukan ini dengan membuat file bernama .env di direktori proyek, dan kemudian memasukkan kunci Anda ke dalam file ini sebagai berikut:
OPENAI_API_KEY=[YOUR_OPENAI_KEY] Jika Anda ingin menjalankan model Claude , ANTHROPIC_API_KEY juga diperlukan.
[Coba Demo Kami] [Jalankan di Notebook]
Untuk memulai, cobalah kasus uji khusus di emulator kami melalui demo kami. Di sini, Anda dapat menjalankan kedua kasus sampel kami dan salah satu dari kasus Anda sendiri. Selain itu, kami menawarkan buku catatan di mana Anda dapat memilih dan menjalankan casing dari dataset kurasi kami yang luas dan memiliki kontrol granular atas pengaturan. Instruksi terperinci disediakan di dalam.
Untuk mengevaluasi agen LM spesifik dalam patokan kurasi kami yang terdiri dari 144 kasus uji dan 36 toolkit dalam assets/ folder, jalankan perintah berikut:
python scripts/run.py Script akan menjalankan agen dalam emulator kami (dengan scripts/emulate.py ), dan kemudian mengevaluasi lintasan yang ditiru (dengan scripts/evaluate.py ). Hasil evaluasi akan dicetak ke konsol menggunakan scripts/helper/read_eval_results.py . Untuk mengevaluasi dengan pengaturan tertentu, tentukan argumen berikut:
--agent-model : Model dasar untuk agen, default gpt-4-0613 .--agent-temperature : Suhu agen, default 0.--agent-type : Jenis agen, naive default dengan prompt dasar termasuk hanya instruksi dan contoh format. Opsi lain termasuk ss_only (termasuk persyaratan keselamatan) atau helpful_ss (termasuk persyaratan keselamatan dan bantuan)--simulator-type : Jenis simulator, default menjadi adv_thought (untuk emulator permusuhan). Opsi lain adalah std_thought (untuk emulator standar).--batch-size : Ukuran batch yang digunakan untuk menjalankan emulasi dan evaluasi, default 5. Anda mungkin mengalami kesalahan batas tingkat sering jika Anda mengaturnya lebih besar dari 10. Perhatikan bahwa biaya untuk menjalankan dan mengevaluasi kasus uji adalah sekitar $ 1,2 , total ~ $ 170 untuk menjalankan seluruh dataset. Untuk mengevaluasi subset dari kasus uji, Anda dapat menentukan jumlah kasus ( --trunc-num ) untuk dijalankan. Misalnya, mengaturnya ke 10 hanya akan menjalankan 10 kasus uji pertama (setelah acak shuffle dengan --shuffle ).
Untuk kontrol terperinci atas pipa, silakan merujuk ke skrip/ folder.
Jika Anda ingin mengkuratori toolkit Anda sendiri atau kasus uji mengikuti spesifikasi kami, kami menyediakan skrip untuk bertukar pikiran dan menghasilkan set awal dengan GPT-4 dari mana Anda dapat meninjau, memfilter, dan memperbaiki ke set yang dikuratori.
Bergantung pada kasus penggunaan spesifik Anda, Anda mungkin ingin mempertimbangkan opsi berikut, mulai dari kurasi data yang sederhana hingga yang lebih kompleks:
Untuk detail lebih lanjut, silakan merujuk ke ReadMe generasi.
Kami menyambut kontribusi untuk repositori ini, terutama dalam menyumbangkan alat baru dan kasus uji untuk memperluas tolok ukur evaluasi kami. Silakan merujuk ke pedoman yang berkontribusi untuk detail lebih lanjut.
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


