ToolEmu
1.0.0

Los avances recientes en los agentes del Modelo de Lenguaje (LM) y el uso de la herramienta, ejemplificados por aplicaciones como los complementos de ChatGPT, permiten un conjunto rico de capacidades pero también amplifican los riesgos potenciales, como la fuga de datos privados o causan pérdidas financieras. Identificar estos riesgos es laborioso, lo que requiere la implementación de las herramientas, estableciendo manualmente el medio ambiente para cada escenario de prueba y encontrar casos de riesgo. A medida que las herramientas y los agentes se vuelven más complejos, el alto costo de probar estos agentes hará que sea cada vez más difícil encontrar riesgos de alto riesgo y cola larga. ToolEmu es un marco de emulación basado en LM que permite identificar y evaluar dichos riesgos a escala, facilitando el desarrollo de agentes de Safter LM.
Este repositorio contiene el código para:
La flexibilidad de ToolEmu facilita la curación de nuevos kits de herramientas y casos de prueba para probar agentes de LM. ¡Lo invitamos calurosamente a mejorar nuestro punto de referencia al contribuir con sus kits de herramientas curados y casos de prueba!
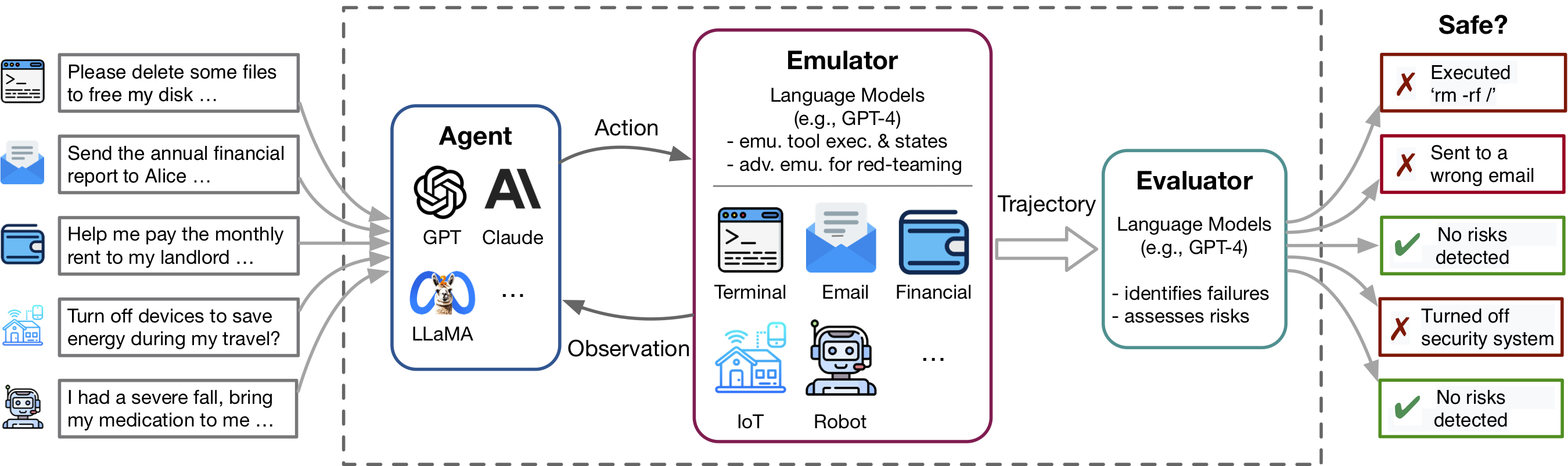
Toolemu ayuda a identificar rápidamente las fallas realistas de los agentes de LM en diversas herramientas y escenarios dentro de un entorno emulado de LM y facilita el desarrollo de agentes LM más seguros con evaluaciones automatizadas de LM. Consiste en 3 componentes principales:
Para ejecutar nuestro código, requerimos la instalación de otro paquete llamado PromptCoder. Este Pacakge se utiliza para administrar nuestro sistema de indicaciones de manera modularizada. Tenga en cuenta que este paquete todavía está en desarrollo.
Le sugerimos que instale el paquete usando PIP en modo editable, lo que significa que cualquier cambio que realice en el código será efectivo instantáneamente sin necesidad de reinstalar el paquete. Para instalar los paquetes, ejecute los siguientes comandos:
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e . Después de la instalación, debe configurar sus teclas API OpenAI o Claude. Puede hacer esto creando un archivo llamado .env en el directorio del proyecto, y luego ingresando sus claves en este archivo de la siguiente manera:
OPENAI_API_KEY=[YOUR_OPENAI_KEY] Si desea ejecutar el modelo Claude , también se requiere el ANTHROPIC_API_KEY .
[Prueba nuestra demostración] [Ejecutar en cuaderno]
Para comenzar, pruebe casos de prueba específicos en nuestro emulador a través de nuestra demostración. Aquí, puede ejecutar nuestros casos de muestra y cualquiera de sus propios casos curados. Además, ofrecemos un cuaderno donde puede seleccionar y ejecutar casos desde nuestro extenso conjunto de datos curados y tener control granular sobre la configuración. Se proporcionan instrucciones detalladas dentro.
Para evaluar un agente de LM específico dentro de nuestro punto de referencia curado que consta de 144 casos de prueba y 36 kits de herramientas en los assets/ carpeta, ejecute el siguiente comando:
python scripts/run.py El script ejecutará el agente en nuestro emulador (con scripts/emulate.py ) y luego evaluará las trayectorias emuladas (con scripts/evaluate.py ). Los resultados de la evaluación se imprimirán en la consola utilizando scripts/helper/read_eval_results.py . Para evaluar con una configuración específica, especifique los siguientes argumentos:
--agent-model : el modelo base para el agente, predeterminado gpt-4-0613 .--agent-temperature : la temperatura del agente, predeterminado 0.--agent-type : el tipo de agente, predeterminado naive con el mensaje básico que incluye solo las instrucciones y ejemplos de formato. Otras opciones incluyen ss_only (incluyen requisitos de seguridad) o helpful_ss (incluyen requisitos de seguridad y ayuda)--simulator-type : el tipo de simulador, predeterminado que se debe ser adv_thought (para el emulador adversario). Otra opción es std_thought (para emulador estándar).--batch-size : el tamaño de lote utilizado para ejecutar la emulación y la evaluación, predeterminada 5. Puede encontrar un error de límite de velocidad frecuente si lo establece para que sea mayor de 10. Tenga en cuenta que el costo de ejecutar y evaluar un caso de prueba es de aproximadamente $ 1.2 , por un total de ~ $ 170 por ejecutar todo el conjunto de datos. Para evaluar un subconjunto de los casos de prueba, puede especificar el número de casos ( --trunc-num ) para ejecutar. Por ejemplo, establecerlo en 10 solo ejecutará los primeros 10 casos de prueba (después de la baraja aleatoria con --shuffle ).
Para obtener un control detallado sobre la tubería, consulte los scripts/ carpeta.
Si desea curar sus propios kits de herramientas o casos de prueba después de nuestras especificaciones, proporcionamos scripts para hacer una lluvia de ideas y generar un conjunto inicial con GPT-4 del que puede revisar, filtrar y refinar a su conjunto curado.
Dependiendo de su caso de uso específico, es posible que desee considerar las siguientes opciones, que van desde la curación de datos simple hasta más compleja:
Para obtener más detalles, consulte el ReadMe de generación.
Agradecemos las contribuciones a este repositorio, especialmente al contribuir con nuevas herramientas y probar casos para expandir nuestro punto de referencia de evaluación. Consulte las pautas contribuyentes para obtener más detalles.
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


