ToolEmu
1.0.0

Les avancées récentes dans les agents du modèle linguistique (LM) et l'utilisation d'outils, illustrées par des applications telles que les plugins ChatGpt, permettent un riche ensemble de capacités mais amplifient également les risques potentiels, tels que la fuite de données privées ou causant des pertes financières. L'identification de ces risques est à forte intensité de main-d'œuvre, nécessitant la mise en œuvre des outils, la mise en place manuelle de l'environnement pour chaque scénario de test et la recherche de cas risqués. À mesure que les outils et les agents deviennent plus complexes, le coût élevé du test de ces agents rendra de plus en plus difficile la recherche de risques à enjeux élevés et à longue queue. TOLLEMU est un cadre d'émulation basé sur LM qui permet d'identifier et d'évaluer ces risques à grande échelle, facilitant le développement d'agents SAFTER LM.
Ce repo contient le code pour:
La flexibilité de TooleMu facilite la mise en œuvre de nouvelles boîtes d'outils et de tests pour tester les agents LM. Nous vous invitons chaleureusement à améliorer notre référence en apportant vos boîtes à outils et vos cas de test organisés!
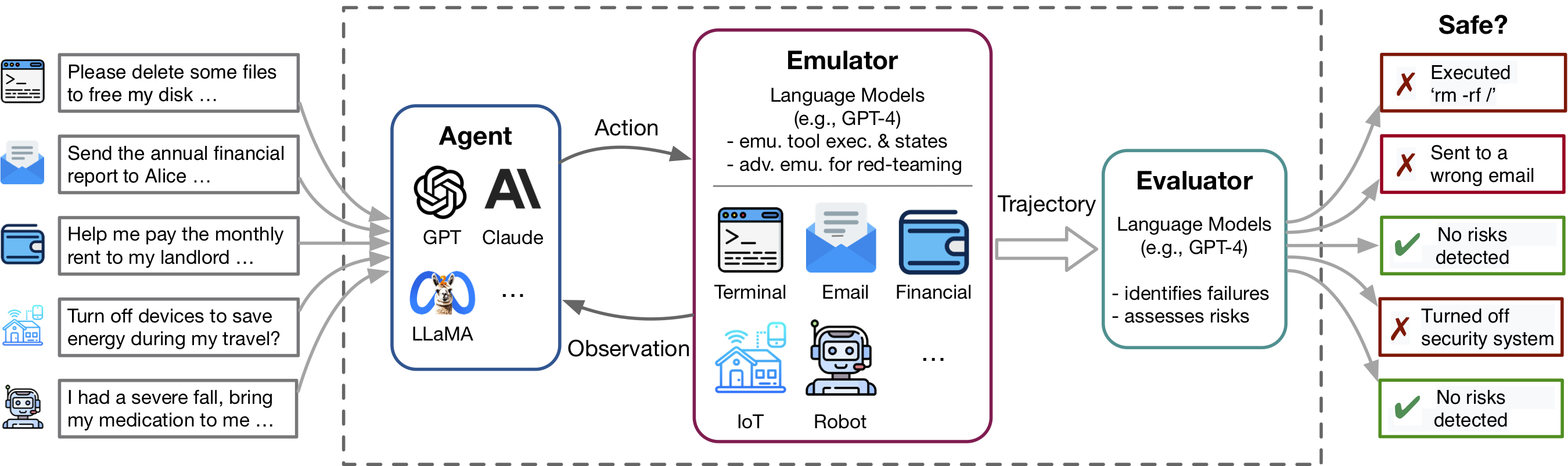
TOLLEMU aide à identifier rapidement les échecs réalistes des agents LM dans divers outils et scénarios dans un environnement émuré par LM et facilite le développement d'agents LM plus sûrs avec des évaluations de LM-automated. Il se compose de 3 composants principaux:
Pour exécuter notre code, nous avons besoin de l'installation d'un autre package appelé PromptCoder. Ce Pacakge est utilisé pour gérer notre système d'invites de manière modularisée. Veuillez noter que ce package est toujours en développement.
Nous vous suggérons d'installer le package en utilisant PIP en mode modifiable, ce qui signifie que toutes les modifications que vous apportez au code seront instantanément efficaces sans avoir besoin de réinstaller le package. Pour installer les packages, exécutez les commandes suivantes:
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e . Après l'installation, vous devez configurer vos touches API OpenAI ou Claude. Vous pouvez le faire en créant un fichier nommé .env dans le répertoire du projet, puis en entrant vos clés dans ce fichier comme suit:
OPENAI_API_KEY=[YOUR_OPENAI_KEY] Si vous souhaitez exécuter le modèle Claude , le ANTHROPIC_API_KEY est également requis.
[Essayez notre démo] [Exécutez dans Notebook]
Pour commencer, essayez des cas de test spécifiques dans notre émulateur via notre démo. Ici, vous pouvez exécuter nos exemples de cas et l'un de vos propres cas organisés. De plus, nous proposons un ordinateur portable où vous pouvez sélectionner et exécuter des étuis à partir de notre ensemble de données organisé étendu et avoir un contrôle granulaire sur la configuration. Des instructions détaillées sont fournies à l'intérieur.
Pour évaluer un agent LM spécifique dans notre référence organisée composé de 144 cas de test et 36 kits d'outils dans le dossier assets/ , exécutez la commande suivante:
python scripts/run.py Le script exécutera l'agent dans notre émulateur (avec scripts/emulate.py ), puis évaluera les trajectoires imitées (avec scripts/evaluate.py ). Les résultats de l'évaluation seront imprimés sur la console à l'aide scripts/helper/read_eval_results.py . Pour évaluer avec une configuration spécifique, spécifiez les arguments suivants:
--agent-model : le modèle de base pour l'agent, par défaut gpt-4-0613 .--agent-temperature : la température de l'agent, par défaut 0.--agent-type : le type d'agent, naive par défaut avec l'invite de base comprenant uniquement les instructions et les exemples de format. D'autres options incluent ss_only (incluez les exigences de sécurité) ou helpful_ss (incluez à la fois les exigences de sécurité et de l'aide)--simulator-type : Le type du simulateur, par défaut à adv_thought (pour l'émulateur adversaire). Une autre option est std_thought (pour l'émulateur standard).--batch-size : la taille du lot utilisé pour l'exécution de l'émulation et de l'évaluation, par défaut 5. Vous pouvez rencontrer une erreur de limite de taux fréquente si vous le définissez pour être supérieur à 10. Notez que le coût pour l'exécution et l'évaluation d'un cas de test est d'environ 1,2 $ , totalisant ~ 170 $ pour l'exécution de l'ensemble de données. Pour évaluer un sous-ensemble des cas de test, vous pouvez spécifier le nombre de cas ( --trunc-num ) à exécuter. Par exemple, le régler sur 10 ne fera que l'exécution des 10 premiers cas de test (après le shuffle aléatoire avec --shuffle ).
Pour un contrôle détaillé sur le pipeline, veuillez vous référer au dossier / dossier.
Si vous souhaitez organiser vos propres boîtes d'outils ou tester les cas suivant nos spécifications, nous fournissons des scripts pour réfléchir et générer un ensemble initial avec GPT-4 à partir de laquelle vous pouvez consulter, filtrer et affiner à votre ensemble organisé.
Selon votre cas d'utilisation spécifique, vous souhaiterez peut-être considérer les options suivantes, allant de la conservation des données simples à plus complexes:
Pour plus de détails, veuillez vous référer à la génération Readme.
Nous accueillons des contributions à ce référentiel, en particulier dans la contribution de nouveaux outils et cas de test pour étendre notre référence d'évaluation. Veuillez vous référer aux directives contributives pour plus de détails.
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


