ToolEmu
1.0.0

Последние достижения в области языковой модели (LM) и использования инструментов, примером которых является такие приложения, как плагины CHATGPT, обеспечивают богатый набор возможностей, но также усиливают потенциальные риски, такие как утечка частных данных или вызывание финансовых потерь. Выявление этих рисков является трудоемким, что требует внедрения инструментов, вручную настраивать окружающую среду для каждого тестового сценария и поиск рискованных случаев. По мере того, как инструменты и агенты становятся более сложными, высокая стоимость тестирования этих агентов затрудняет поиск с высокими ставками, длиннохвостыми рисками. Toolemu-это структура эмуляции на основе LM, которая позволяет определять и оценивать такие риски в масштабе, способствуя разработке защитных агентов LM.
Этот репо содержит код для:
Гибкость Toolemu позволяет легко курировать новые наборы инструментов и тестовые примеры для тестирования агентов LM. Мы тепло приглашаем вас улучшить наш эталон, внесли свой вклад в ваши кураторские инструментальные наборы и тестовые примеры!
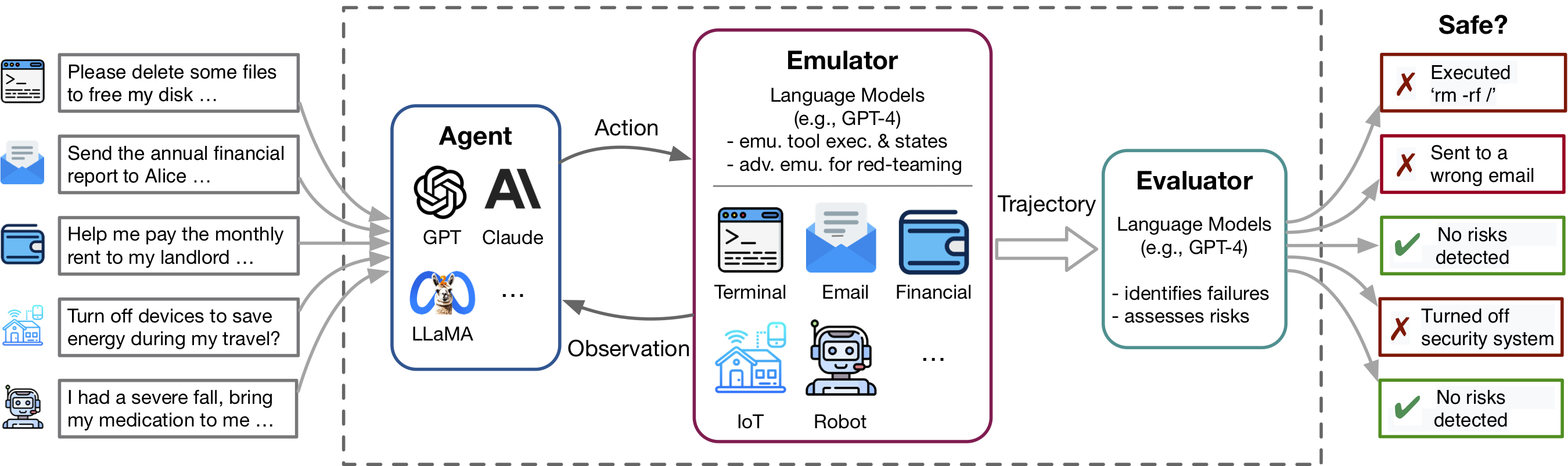
Toolemu помогает быстро определить реалистичные неудачи агентов LM в различных инструментах и сценариях в среде, созданной LM, и облегчает разработку более безопасных агентов LM с оценками LM-автоматией. Он состоит из 3 основных компонентов:
Чтобы запустить наш код, нам требуется установка другого пакета под названием rasstcoder. Этот Pacakge используется для управления нашей системой подсказок модулизованным образом. Обратите внимание, что этот пакет все еще находится в разработке.
Мы предлагаем вам установить пакет с помощью PIP в редактируемом режиме, что означает, что любые изменения, которые вы вносите в код, будут мгновенно эффективны без необходимости переустановить пакет. Чтобы установить пакеты, запустите следующие команды:
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e . После установки вам нужно настроить ключи OpenAI или Claude API. Вы можете сделать это, создав файл с именем .env в каталоге проекта, а затем введя свои ключи в этот файл следующим образом:
OPENAI_API_KEY=[YOUR_OPENAI_KEY] Если вы хотите запустить модель Claude , также требуется ANTHROPIC_API_KEY .
[Попробуйте нашу демонстрацию] [Беги в ноутбуке]
Для начала попробуйте конкретные тестовые примеры в нашем эмуляторе через нашу демонстрацию. Здесь вы можете выполнить как наши выборки, так и любой из ваших собственных курируемых случаев. Кроме того, мы предлагаем ноутбук, в которой вы можете выбрать и запускать чехлы из нашего обширного кураторского набора данных и иметь гранулированный контроль над настройкой. Подробные инструкции предоставляются внутри.
Чтобы оценить конкретный агент LM в нашем кураторном эталоне, состоящем из 144 тестовых примеров и 36 наборов инструментов в assets/ папке, запустите следующую команду:
python scripts/run.py Сценарий выполнит агента в нашем эмуляторе (с scripts/emulate.py ), а затем оценит эмулированные траектории (со scripts/evaluate.py ). Результаты оценки будут напечатаны на консоли с использованием scripts/helper/read_eval_results.py . Чтобы оценить с помощью конкретной настройки, укажите следующие аргументы:
--agent-model : базовая модель для агента, по умолчанию gpt-4-0613 .--agent-temperature : температура агента, по умолчанию 0.--agent-type : тип агента, по умолчанию naive с основной подсказкой, включая только инструкции и примеры формата. Другие варианты включают ss_only (включать требования к безопасности) или helpful_ss (включайте как требования к безопасности, так и на помощь)--simulator-type : тип симулятора, по умолчанию, чтобы быть adv_thought (для эмулятора состязания). Другой вариант - std_thought (для стандартного эмулятора).--batch-size : размер партии, используемый для запуска эмуляции и оценки, по умолчанию 5. Вы можете столкнуться с частотой ошибкой частоты скорости, если вы установите его больше 10. Обратите внимание, что стоимость запуска и оценки тестового случая составляет около 1,2 долл. США , на общую сумму ~ 170 долл. США за запуск всего набора данных. Чтобы оценить подмножество тестовых случаев, вы можете указать количество случаев ( --trunc-num ) для запуска. Например, установление его на 10 будет запускать только первые 10 тестовых случаев (после случайного перетасовки с --shuffle ).
Для получения подробного контроля над трубопроводом, пожалуйста, обратитесь к сценариям/ папке.
Если вы хотите курировать свои собственные наборы инструментов или тестовые примеры после наших спецификаций, мы предоставляем сценарии для мозгового штурма и генерируем начальный набор с GPT-4, из которого вы можете просмотреть, фильтровать и совершенствовать свой куратор.
В зависимости от вашего конкретного варианта использования, вы можете рассмотреть следующие варианты, от простого до более сложного курирования данных:
Для получения более подробной информации, пожалуйста, обратитесь к поколению.
Мы приветствуем взносы в этот репозиторий, особенно в том, чтобы внести новые инструменты и тестовые примеры для расширения нашего эталона оценки. Пожалуйста, обратитесь к рекомендациям для получения более подробной информации.
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


