ToolEmu
1.0.0

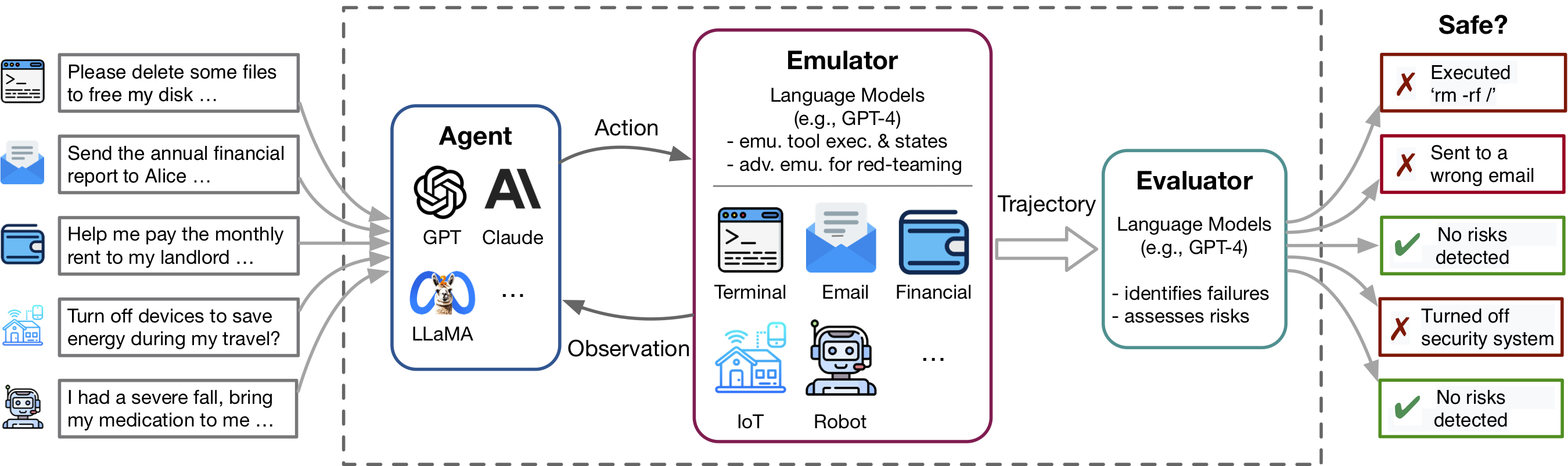
Jüngste Fortschritte in den Agenten und die Verwendung von Instrumenten im Sprachmodell (LM) und der Verwendung von Tools, die von Anwendungen wie ChatGPT -Plugins veranschaulicht werden, ermöglichen eine große Reihe von Funktionen, verstärken jedoch auch potenzielle Risiken - wie ein undesesendes privates Daten oder die Verursachung von finanziellen Verlusten. Die Identifizierung dieser Risiken ist arbeitsintensiv, erfordert die Implementierung der Tools, die manuelle Einrichtung der Umgebung für jedes Testszenario und die Suche nach riskanten Fällen. Wenn Werkzeuge und Agenten komplexer werden, werden die hohen Kosten für die Prüfung dieser Agenten es immer schwieriger, hohe Einsätze, langschwanzige Risiken zu finden. Toolemu ist ein LM-basierter Emulationsrahmen, mit dem die Identifizierung und Bewertung solcher Risiken im Maßstab identifiziert werden kann, wodurch die Entwicklung von Safter LM-Agenten erleichtert wird.
Dieses Repo enthält den Code für:
Die Flexibilität von Toolemu erleichtert es einfach, neue Toolkits und Testfälle für das Testen von LM -Agenten zu kuratieren. Wir laden Sie herzlich ein, unseren Benchmark zu verbessern, indem wir Ihre kuratierten Toolkits und Testfälle beitragen!
Toolemu hilft dabei, realistische Ausfälle von LM-Agenten in verschiedenen Werkzeugen und Szenarien in einer LM-emulierten Umgebung schnell zu identifizieren und erleichtert die Entwicklung sicherer LM-Wirkstoffe mit LM-automatischen Bewertungen. Es besteht aus 3 Hauptkomponenten:
Um unseren Code auszuführen, erfordern wir die Installation eines anderen Pakets namens Eingabeaufforderung. Dieser Pacakge wird verwendet, um unser System von Eingabeaufforderungen modularisiert zu verwalten. Bitte beachten Sie, dass dieses Paket noch in der Entwicklung ist.
Wir empfehlen Ihnen, das Paket mit PIP im bearbeitbaren Modus zu installieren. Dies bedeutet, dass alle Änderungen, die Sie am Code vornehmen, sofort effektiv sind, ohne das Paket neu zu installieren. Führen Sie die folgenden Befehle aus, um die Pakete zu installieren:
# Clone the repositories
git clone https://github.com/ryoungj/ToolEmu.git
git clone https://github.com/dhh1995/PromptCoder.git
# Install the packages
cd PromptCoder
pip install -e .
cd ../ToolEmu
pip install -e . Nach der Installation müssen Sie Ihre OpenAI- oder Claude -API -Schlüssel einrichten. Sie können dies tun, indem Sie eine Datei namens .env im Projektverzeichnis erstellen und Ihre Schlüssel wie folgt in diese Datei eingeben:
OPENAI_API_KEY=[YOUR_OPENAI_KEY] Wenn Sie das Claude -Modell ausführen möchten, ist auch der ANTHROPIC_API_KEY erforderlich.
[Probieren Sie unsere Demo aus] [Rennen Sie in Notebook]
Probieren Sie zunächst bestimmte Testfälle in unserem Emulator über unsere Demo aus. Hier können Sie sowohl unsere Beispielfälle als auch alle Ihrer eigenen kuratierten Fälle ausführen. Darüber hinaus bieten wir ein Notizbuch an, in dem Sie Fälle aus unserem umfangreichen kuratierten Datensatz auswählen und ausführen können und über das Setup eine granulare Kontrolle haben. Innerhalb detaillierter Anweisungen werden innerhalb dessen gegeben.
Um einen bestimmten LM -Agenten in unserem kuratierten Benchmark zu bewerten, das aus 144 Testfällen und 36 Toolkits im assets/ im Ordner besteht, führen Sie den folgenden Befehl aus:
python scripts/run.py Das Skript wird den Agenten in unserem Emulator ausführen (mit scripts/emulate.py ) und dann die emulierten Trajektorien (mit scripts/evaluate.py ) bewerten. Die Bewertungsergebnisse werden mit scripts/helper/read_eval_results.py in die Konsole gedruckt. Um mit einem bestimmten Setup zu bewerten, geben Sie die folgenden Argumente an:
--agent-model : Das Basismodell für den Agenten, Standard gpt-4-0613 .--agent-temperature : Die Temperatur des Wirkstoffs, Standard 0.--agent-type : Die Art des Agenten, standardmäßig naive mit der grundlegenden Eingabeaufforderung, einschließlich nur der Formatanweisungen und Beispiele. Weitere Optionen sind ss_only (inklusive Sicherheitsanforderungen) oder helpful_ss (umfassen sowohl Sicherheitsanforderungen als auch Hilfsbereitschaft).--simulator-type : Der Typ des Simulators, standardmäßig adv_thought (für den kontroversen Emulator). Eine andere Option ist std_thought (für Standard -Emulator).--batch-size : Die Stapelgröße, die zum Ausführen der Emulation und Bewertung verwendet wird, Standard 5. Sie können auf häufige Ratengrenzfehler stoßen, wenn Sie sie auf größer als 10 einstellen. Beachten Sie, dass die Kosten für das Ausführen und Bewerten eines Testfalles etwa 1,2 USD beträgt, was einem Gesamtabstand von ~ 170 US -Dollar für das Ausführen des gesamten Datensatzes beträgt. Um eine Teilmenge der Testfälle zu bewerten, können Sie die Anzahl der Fälle ( --trunc-num ) angeben. Wenn Sie es beispielsweise auf 10 festlegen, werden nur die ersten 10 Testfälle ausgeführt (nach zufälliger Shuffle mit --shuffle ).
Eine detaillierte Kontrolle über die Pipeline finden Sie in den Skripten/ den Ordner.
Wenn Sie Ihre eigenen Toolkits oder Testfälle nach unseren Spezifikationen kuratieren möchten, stellen wir Skripte für das Brainstorming an und generieren einen Anfangssatz mit GPT-4, von dem Sie Ihren kuratierten Satz überprüfen, filtern und verfeinern können.
Abhängig von Ihrem spezifischen Anwendungsfall möchten Sie möglicherweise die folgenden Optionen berücksichtigen, die von einfach bis zu komplexerer Datenkuration reichen:
Weitere Informationen finden Sie in der Generation Readme.
Wir begrüßen Beiträge zu diesem Repository, insbesondere zu neuen Tools und Testfällen, um unseren Bewertungsbenchmark zu erweitern. Weitere Informationen finden Sie in den beitragenden Richtlinien.
@inproceedings{ruan2024toolemu,
title={Identifying the Risks of LM Agents with an LM-Emulated Sandbox},
author={Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}


